Collecting data is good, collecting big data is better, but analyzing big data not so easy. It requires knowledge of enterprise search engines for making content from different sources like enterprise database, social media, sensor data etc. searchable to a defined audience. Elasticsearch, Apache Solr, Sphinx are some of the free and open source enterprise search software.
Elasticsearch is the main product of a company called ‘Elastic’. It is used for web search, log analysis, and big data analytics. Often compared with Apache Solr, both depend on Apache Lucene for low-level indexing and analysis. Elasticsearch is more popular because it is easy to install, scales out to hundreds of nodes with no additional software, and is easy to work with due to its built-in REST API.

1. Developer-Friendly API
Elasticsearch is API driven. Almost any action can be performed using a simple RESTful API using JSON over HTTP. Client libraries are available for many programming languages. It has a clean and easily navigated documentation increasing the quality and user experience of independently created applications on your platform. It can be integrated with Hadoop for fast query results. Klout, website which measure social media influence uses this technique and has scale from 100 million to 400 million users, while reducing database update time from one day down to four hours, and delivering query results to the business analysts in seconds rather than minutes.
2. Real-Time Analytics
Real-time analytics provides updated results of customer events, such as page views, website navigation, shopping cart use, or any other kind of online or digital activity. This data is extremely important for businesses conducting dynamic analysis and reporting in order to quickly respond to trends in user behavior. Using Elasticsearch data is immediately available for search and analytics. Elasticsearch combines the speed of search instances with the power of analytics for better decision making. It gives insights that make your business streamlined and improves your products by interactive search and other analyzing features.
3. Ease of Data Indexing
Data indexing is a way of sorting a number of records on multiple fields. Elasticsearch is schema-free and document-oriented. It stores complex real world entities in Elasticsearch as structured JSON documents. Simply index a JSON document and it will automatically detect the data structure and types, create an index, and make your data searchable. You also have full control to customize how your data is indexed. It simplifies the analytics process by improving the speed of data retrieval process on a database table.
Implementing data indexing can be challenging without expert guidance and may require assistance from a data engineering consulting company.
4. Full-Text Search
In a full-text search, a search engine examines all of the words in every stored document as it tries to match search criteria. Elasticsearch builds distributed capabilities on top of Apache Lucene to provide the most powerful full- text search capabilities available in any open source product. Powerful, developer-friendly query API supports multilingual search, geolocation, contextual did-you-mean suggestions, autocomplete, and result-snippets.
5. Resilient Clusters
Elasticsearch clusters are resilient — they will detect new or failed nodes. It will also reorganize and rebalance data automatically to ensure that your data is safe and accessible. A cluster may contain multiple indices that can be queried independently or as a group. Index aliases allow filtered views of an index and may be updated transparently in your application.
Thus. Implementing Elasticsearch offers organizations scalability, real-time search capabilities, and powerful analytics features, making it an invaluable tool for driving insights and extracting meaningful intelligence in big data analytics.
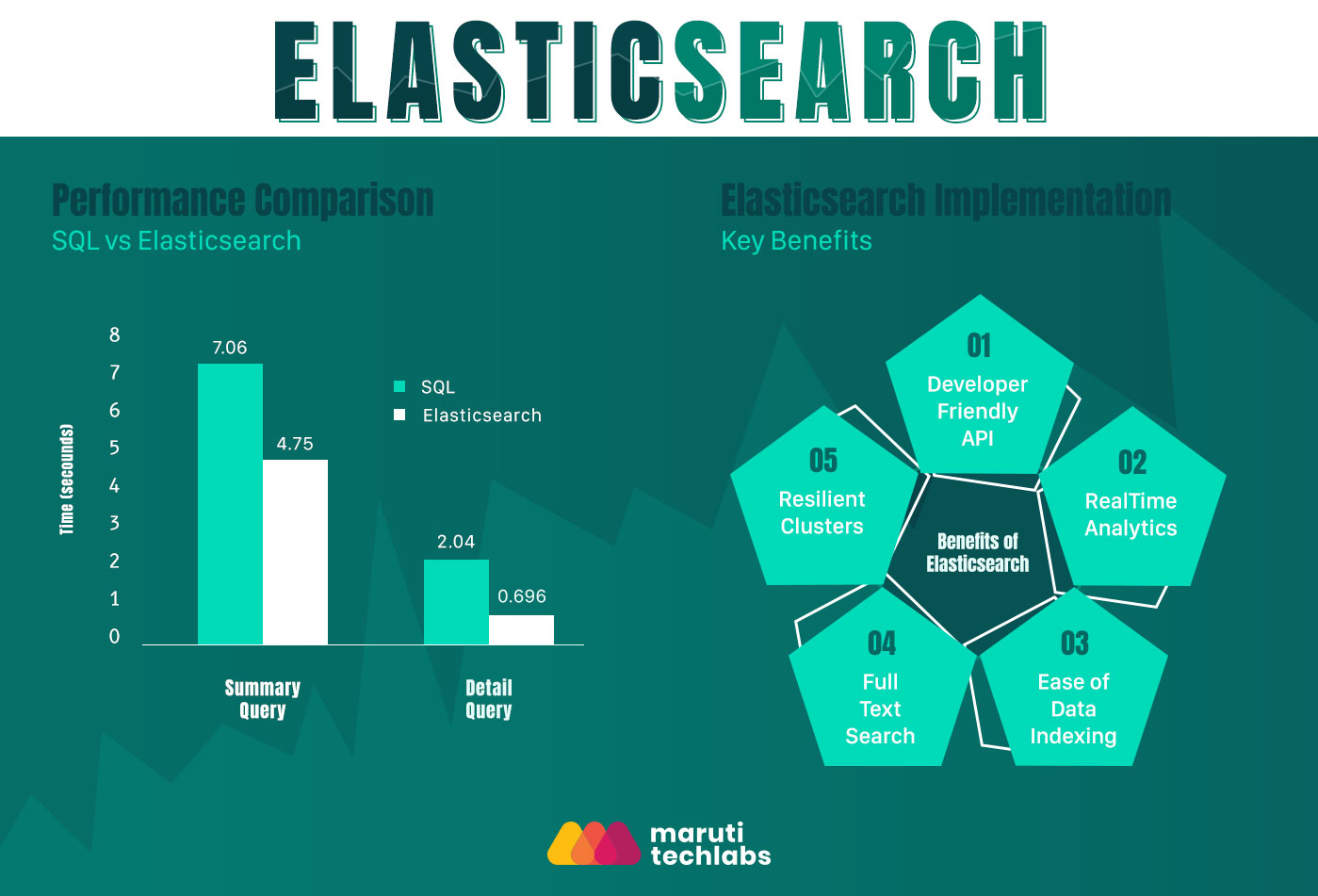
Maruti Techlabs is using Elasticsearch for improving the user experience in searching data of used car parts for our client based in Austin, Texas. A potential customer can find ‘used parts’ for his car on this portal. A huge amount of data (around 42 million data) affects the usability of the system performance and query response time. If a search requires data entities from a large data set, you could see a significant drag in query performance. Standard tools like Relational Database Management Systems (RDBMS) are not suited for real-time big data analysis and dynamic conditions leading to time-outs. Thus, a complex search involves a mix of traditional databases from numerous vendors consisting of structured and unstructured data. For this client, Maruti Techlabs chose Elasticsearch as the secondary data layer component. We have separate services for data import and result computation. So when data from vendors is maintained in SQL server it is simultaneously fed into Elasticsearch. Using Elasticsearch query response time was significantly reduced from 7.06 seconds to 4.75 seconds. Scalability is another additional benefit of this new architecture. Leveraging Elasticsearch to build the data infrastructure has made it easier to linearly scale as new data nodes are added in the future.








