Decoding the Intersection of Credit Scoring and Machine Learning
Discover how machine learning is impacting the finance sector and what this means for the future of finance.
Artificial Intelligence and Machine Learning
Decoding the Intersection of Credit Scoring and Machine Learning
Discover how machine learning is impacting the finance sector and what this means for the future of finance.
Table of contents
Table of contents
Introduction
What is a Credit Scoring System?
How do you Implement Credit Scoring with Machine Learning?
How do Machine Learning Models Add Business Value?
Conclusion
Introduction
Finance is something that no person on earth can live without. It is the basic necessity of life, as everybody needs money to eat, travel, and buy things. Although as technology gets smarter so do people. The present financial market is already comprised of humans as well as machines. People are finding more and more ways to default on loans, stealing money from others account, creating a fake credit rating etc.
Today, machine learning plays an integral role in many phases of the financial ecosystem. From approving loans, to managing assets, to assess risks. Yet, only a few technically-sound professionals have a precise view of how ML finds its way into their daily financial lives. Nowadays, detection of frauds has become easy thanks to Machine Learning. Given the fact that machine learning is a very broad concept, we will learn a few ways how Finance could benefit with the use of Machine Learning.
What is a Credit Scoring System?
A credit scoring system is a statistical analysis conducted by financial institutions and lenders to assess the creditworthiness of an individual or a business owner.
Credit scoring models assist lenders with crucial decision-making processes, like extending or denying credit and determining the loanee's possibility of repaying the loan on time by analyzing their credit history, income, and other factors.
Banks and other financial institutions have followed the traditional manual process for determining a borrower's creditworthiness. However, this process encompasses limited data points that result in consistency and errors.
The advent of artificial intelligence (AI) has transformed credit scoring. AI credit scoring leverages machine learning and advanced algorithms to scrutinize data from unconventional data sources, such as online purchases and social media activity, to predict creditworthiness explicitly and competently.
Here are the benefits of using AI over traditional scoring systems.
It allows lenders to make quick and attested decisions by examining extensive data swiftly and precisely.
AI touches myriad verticals like online purchases and social media activity, contradictory to traditional credit scoring systems.
AI systems are ever-evolving, inculcating varying market scenarios to offer the latest insights to lenders.
How do you Implement Credit Scoring with Machine Learning?
Despite rigorous credibility verification, financial institutions grapple with issues like large corporations defaulting on loan payments. Lenders need help with significant data inputs using conventional statistical methods, resulting in incorrect predictions.
Banks face the challenge of instantaneously assessing customer credit scores. This time-consuming due diligence process can be expedited by merging artificial intelligence (AI) and machine learning (ML). Here’s how this feat can be achieved.
Supervised learning is essential when implementing machine learning credit scoring and decision-making. It refers to a type of ML where models learn from labeled data.
Regarding credit scoring, a related label would be whether or not a loanee defaulted on a payment. These models act as a reference to determine predictions for newly added unseen data.
Credit scoring and decision models can be developed using numerous ML algorithms, such as neural networks, random forests, support vector machines, decision trees, and logistic regression. Ensemble methods and deep learning models are also leveraged to handle high-dimensional data and capture intricate patterns.
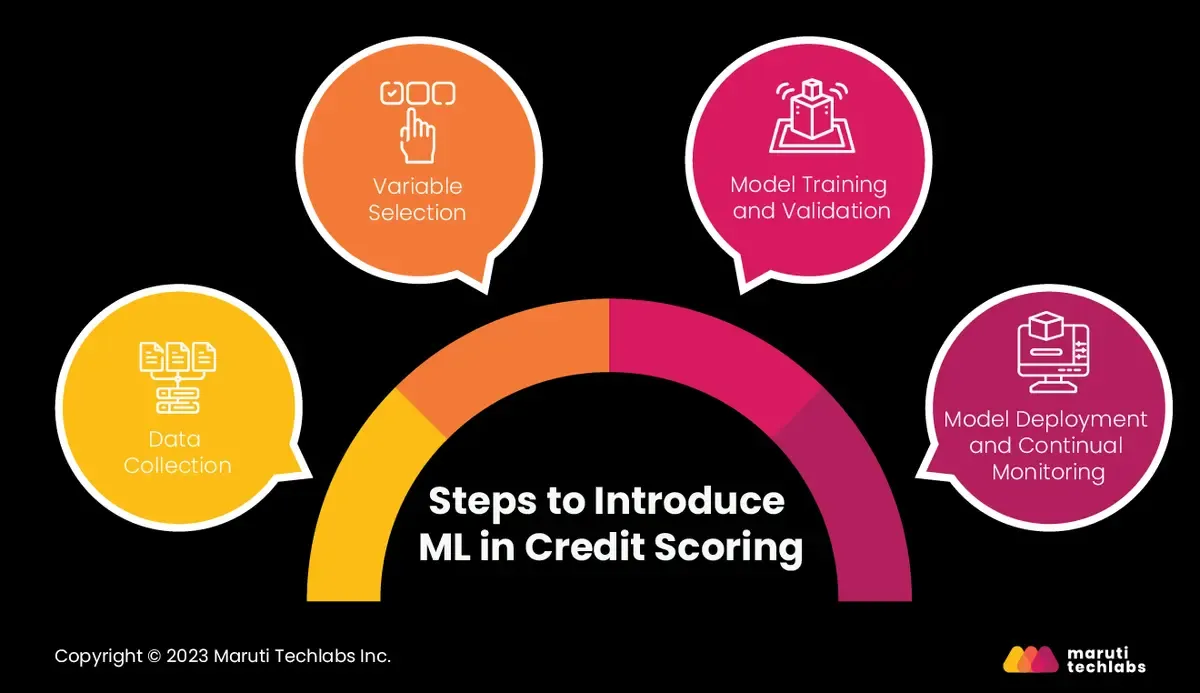
Steps to introduce ML in credit scoring
1. Data Collection
Data gathering and preparation are the primary steps in this process. It includes collecting data from financial statements, load applications, and credit bureaus. Following this step, the garnered data has to be cleaned, normalized, and converted into a format that the ML algorithm can readily use.
2. Variable Selection
This step involves selecting the correct variables (features) to feed into the model. It includes debt ratio, income, employment status, and credit history. The chosen features directly affect the model’s performance. Using inapt variables leads to overfitting, where the model performs well on training data but inefficiently with unseen data.
3. Model Training and Validation
The formulated data is then bifurcated into training and validation sets. The ML algorithm leverages the training set to understand the correlation between the features and outcomes. The validation set checks the model’s performance and regulates its parameters.
4. Model Deployment and Continual Monitoring
Once trained and validated, the model can be deployed in the credit scoring system. Monitoring its performance is imperative to ensure that the model makes accurate predictions. If one observes a downfall in the model's performance, it has to be retrained using apt data.
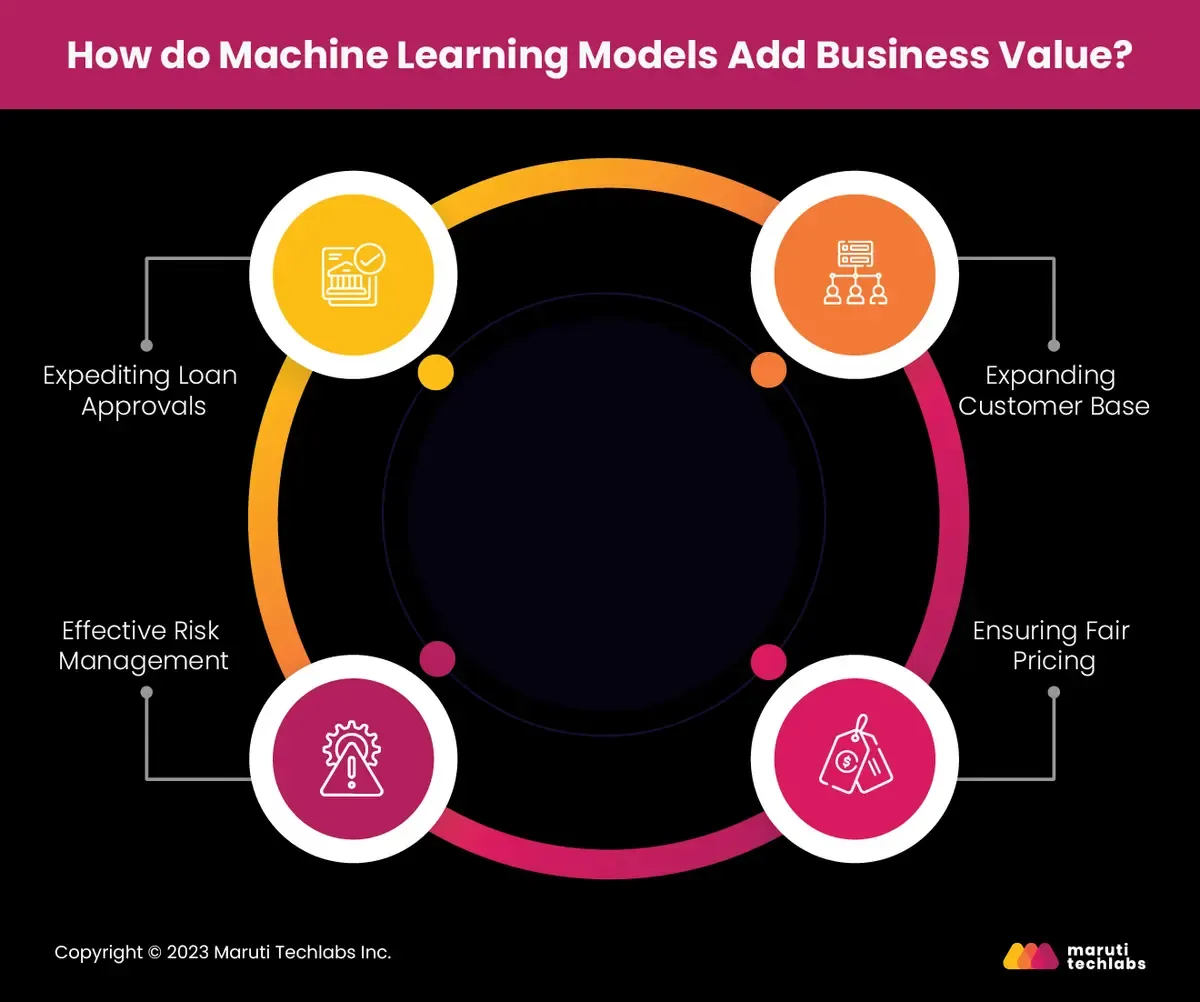
How do Machine Learning Models Add Business Value?
Introducing machine learning to credit scoring offers various benefits to banks and financial institutions. Here are a few evident areas where automation provides added business value.
Expediting Loan Approvals
Rendering quick decisions is the key to gaining a competitive edge. Manual underwriting processes are too time-consuming in an era where customers crave instant responses to their credit applications.
Automation significantly reduces decision-making time, helping lenders provide instant loan approvals. It boosts a lender's market share, enhancing customer satisfaction.
Effective Risk Management
Adept risk management is a crucial element for the lending business. Financial institutions have to evaluate the risk associated with all credit applications precisely.
Using credit scoring models, lenders can enhance decision-making, diminishing the probability of approving risky loans. It protects their financial health, increasing overall profitability.
Expanding Customer Base
Credit history and income level are the essential criteria for credit decisions. However, individuals with unconventional income sources and limited credit history were not considered following this approach.
However, the creditworthiness of ‘thin or no file individuals’ can be gauged using automated credit-decisioning models leveraging data sources like rent payment history and utility bill payments. It allows lenders to expand their business by tapping into new customer segments.
Ensuring Fair Pricing
Credit scoring models can help learn the risk associated with each applicant. Using this, lenders can finalize interest rates based on their credit risk.
Conclusion
Although machine learning is a newer technology there are lots of academicians and industry experts among which machine learning is very popular. It is safe to say that there are a lot more innovation coming in this field. And adopting Machine Learning also has its own setbacks due to data sensitivity, infrastructure requirements, the flexibility of business models etc. But the advantages outweigh the drawbacks and help solve lots of problems with Machine Learning.
Since machine learning techniques are far more secure and safer than human practices, it is the best choice for finance. It would help provide opportunities to banks and other financial institutions by helping them avoid huge losses caused due to defaults. Finance is a very critical matter in all the countries around of the world, and safeguarding them against threats and improving its operations would help all grow and prosper faster.
Pinakin Ariwala has over 20 years of experience in AI/ML, data engineering, and software development. He has led AI and machine learning projects across industries, including agriculture, finance, and healthcare, and has been featured on the Clutch Leaders Matrix podcast discussing real-world AI/ML applications.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!