

How Do Recommendation Engines Work? What are the Benefits?
Introduction
Recommendation engines have become the backbone of personalized digital experiences, shaping how users discover products, services, and content. In 2025, these systems are advancing through AI, generative models, and context-aware personalization, enabling businesses to deliver hyper-relevant recommendations in real time
The global recommendation engine market is projected to reach USD 10.57 billion by 2025, reflecting its growing importance across industries
This is precisely why we made a short video on the topic. It is less than 2 mins, and summarizes how do Recommendation Engines work? & what are the benefits? We hope this helps you learn more and save your time. Cheers!
This blog explores how recommendation engines actually work, from the algorithms powering them to the data they leverage. It also highlights practical applications in industries like e-commerce, entertainment, and finance, while uncovering future trends that will define their role in driving customer engagement, satisfaction, and long-term business growth.
What is a Recommendation Engine?
A product recommendation engine is essentially a solution that allows marketers to offer their customers relevant product recommendations in real-time. As powerful data filtering tools, recommendation systems use algorithms and data analysis techniques to recommend the most relevant product/items to a particular user.

The main aim of any recommendation engine is to stimulate demand and actively engage users. Primarily a component of an eCommerce personalization strategy, recommendation engines dynamically populate various products onto websites, apps, or emails, thus enhancing the customer experience. These kinds of varied and omnichannel recommendations are made based on multiple data points such as customer preferences, past transaction history, attributes, or situational context.
Recommender systems can be used across multiple verticals such as e-commerce, entertainment, mobile apps, education, and more (discussed in detail later). In general, a recommendation engine can be helpful in any situation where there is a need to give users personalized suggestions and advice.
If you want to harness the power of a product recommendation engine for your application, then hire a dedicated Node.js developer. Node.js is a popular and efficient JavaScript runtime that excels at handling real-time, data-intensive, and scalable applications, making it an ideal choice for building recommendation engines.
How does a Recommendation Engine Work?
One of the crucial components behind the working of a product recommendation engine is the recommender function, which considers specific information about the user and predicts the rating that the user might assign to a product.
Having the ability to predict user ratings, even before the user has provided one, makes recommender systems a powerful tool.
It uses specialized algorithms and techniques that can support even the largest of product catalogs. Driven by an orchestration layer, the recommendation engine can intelligently select which filters and algorithms to apply in any given situation for a specific customer. It allows marketers to maximize conversions and also their average order value.
Typically, a recommendation engine processes data through the below four phases-
- Collection
Data collected here can be either explicit such as data fed by users (ratings and comments on products) or implicit such as page views, order history/return history, and cart events.
- Storing
The type of data you use to create recommendations can help you decide the kind of storage you should use, like the NoSQL database, a standard SQL database, or object storage.
- Analyzing
The recommender system analyzes and finds items with similar user engagement data by filtering it using different analysis methods such as batch analysis, real-time analysis, or near-real-time system analysis.
- Filtering
The last step is to filter the data to get the relevant information required to provide recommendations to the user. And for enabling this, you will need to choose an algorithm suiting the recommendation engine from the list of algorithms explained in the next section.
Types Of Recommender Systems
There are many problems solved by machine learning, but making product recommendations is a widely recognized application of machine learning. There are mainly three essential types of recommendation engines –
1. Collaborative Filtering
The collaborative filtering method is based on collecting and analyzing information based on behaviors, activities, or user preferences and predicting what they will like based on the similarity with other users. The prediction is done using various predictive maintenance machine learning techniques.

For example, if user X likes Tennis, Badminton, and Golf while user Y likes Tennis, Badminton, and Hockey, they have similar interests. So, there is a high probability that X would like Hockey and Y would enjoy Golf. It is how collaborative filtering is done.
The two types of collaborative filtering techniques are –
- User-User collaborative filtering
- Item-Item collaborative filtering
One of the main advantages of the collaborative filtering approach is that it can recommend complex items accurately, such as movies, without requiring an understanding of the item itself as it does not depend on machine analyzable content.
2. Content-Based Filtering
Content-based filtering methods are mainly based on the description of an item and a profile of the user’s preferred choices. In content-based filtering, keywords are used to describe the items, whereas a user profile is built to state the type of item this user likes.

For example, if a user likes to watch movies such as Mission Impossible, then the recommender system recommends movies of the action genre or movies of Tom Cruise.
The critical premise of content-based filtering is that if you like an item, you will also like a similar item. This approach has its roots mainly in information retrieval and information filtering research.
3. Hybrid Recommendation Systems
Hybrid Recommendation engines are essentially the combination of diverse rating and sorting algorithms. For instance, a hybrid recommendation engine could use collaborative filtering and product-based filtering in tandem to recommend a broader range of products to customers with accurate precision.

Netflix is an excellent example of a hybrid recommendation system as they make recommendations by:
- Comparing the watching and searching habits of users and finding similar users on that platform, thus making use of collaborative filtering
- Recommending such shows/movies which share common characteristics with the ones rated highly by the user. It is how they make use of content-based filtering.
Compared to pure collaborative and content-based methods, hybrid methods can provide more accurate recommendations. They can also overcome the common issues in recommendation systems such as cold start and the data paucity troubles.
Recommendation Engines: Top 5 Implementation Challenges
Although recommendation engines produce a lot of revenue for e-commerce giants such as Amazon and Netflix, they do have various challenges. Some of these are discussed below –
- Synonymous Names
The challenge of synonymy arises when a single product or item is represented with two or more different names or listings of items (for instance, action movie or action film) having a similar meaning. In such a case, the recommendation system is not capable of recognizing whether the terms show various items or the same item.
- Scalability
One of the other issues with recommendation systems is the scalability of algorithms having real-world datasets. In most cases, the traditional approach has become overwhelmed by the multiplicity of products and clients, leading to dataset challenges and performance reduction.
If you have scarce resources to scale your recommendation systems, it's best to affiliate with an artificial intelligence development company.
- Latency Challenges
Latency issues arise when new products are added more frequently to the database of a recommendation engine. Still, already existing products are recommended to users since newly added products are not rated. Companies can use either a collaborative filtering method or the category-based approach in combination with user-item interaction to deal with the issue.
- Privacy
In most cases, customers need to feed their personal information to the recommendation system for tailor-made and beneficial services. However, it causes various data privacy and security issues, making the customers feel hesitant to feed their personal data into recommendation systems.
But since the recommendation system is bound to have the customer’s personal information and use it to the fullest to offer personalized recommendation services, they must navigate the situation with extra care and ensure trust among their users.
- Issue Of Sparsity
There are instances when users do not give ratings or reviews to the products they purchased, making the rating and review model relatively sparse leading to data sparsity issues. It leads to a decrease in the possibility of finding a set of customers with similar ratings or interests.
Are you facing any of these challenges with your recommendation engine? One solution to address these challenges is partnering with a UX research company like ours. Our company specializes in gathering user insights and feedback to optimize the user experience of digital products, including recommendation engines. By conducting user research and usability testing, we can help identify pain points and areas for improvement in your recommendation engine, ultimately leading to more satisfied users and increased engagement.
How to Implement a Recommendation Engine in 6 Steps
Implementing a recommendation engine requires a structured approach. Businesses must align goals, manage data, select the right algorithm, and ensure continuous monitoring to deliver personalized, effective, and scalable recommendation experiences.
1. Define Goals
Start by clearly defining what you aim to achieve with the recommendation engine whether it’s boosting sales, improving user engagement, or reducing churn.
A clear objective helps align stakeholders, set measurable KPIs, and guides technology choices to ensure recommendations deliver tangible business impact.
2. Data Strategy
A strong data strategy is critical. Businesses should gather high-quality, relevant data such as user behavior, transactions, or contextual signals. This data must be cleaned, standardized, and securely stored.
Establishing governance ensures privacy compliance while creating a foundation for accurate, reliable, and scalable recommendation models.
3. Algorithm Selection
Selecting the right algorithm depends on goals and data. Options include collaborative filtering, content-based filtering, or hybrid models. Businesses should evaluate algorithm performance against their use case, scalability needs, and complexity.
The right choice ensures recommendations remain relevant, adaptive, and aligned with evolving customer expectations.
4. Testing
Before full-scale deployment, rigorous testing is essential. Use A/B testing, simulations, and offline experiments to compare different recommendation strategies.
Testing validates model accuracy, relevance, and user impact, enabling teams to fine-tune algorithms. This step minimizes risks and ensures recommendations truly improve customer experience and outcomes.
5. Deployment
Once tested, integrate the recommendation engine into production systems. This involves connecting it with customer-facing platforms, APIs, or applications.
Deployment must ensure seamless delivery of recommendations without disrupting existing workflows. Proper scaling and infrastructure support ensure real-time responsiveness and smooth operation under varying demand loads.
6. Monitoring
After deployment, continuous monitoring is crucial. Track performance metrics like click-through rates, conversions, and user satisfaction. Regularly retrain models with fresh data to maintain accuracy.
Monitoring also helps detect bias or drift, ensuring recommendations stay fair, effective, and aligned with both business goals and customer needs.
Advantages Of Recommendation Systems
Among the key advantages of recommendation, engines include –
- Enhance Sales & Average Order Value
One of the excellent methods to increase your revenue and average order value (AOV) is to encourage your website visitors to add recommended products and offerings at the checkout page.
Recommendation systems allow you to drive much higher conversions and enhance average order value. You can bring multiple data sets (historical data, real-time visitor behavior, and third-party insights) into a recommendation algorithm using a recommendations engine. These data sets can then deliver relevant recommendations in real-time and allow customers to engage with your brand in real-time.
This kind and level of relevancy give a definite boost to your sales and average order value by exposing your customers to a higher volume of products that are likely to pique their interest.
Further, by leveraging various data algorithms and inferences about what the customer will like based on their past preferences or what has been purchased by similar customers, the recommender systems can systematically encourage additional spending while offering a much more engaging user experience.
- Helps You Deliver Customized And Relevant Content
One of the most efficient ways for any brand to meet customer expectations is to build customized and relevant content. Recommended system allows brands to personalize the customer experience and make suggestions for the items that make the most sense to them.
A recommendation engine also allows you to analyze the customer’s current website usage and their previous browsing history to be able to deliver relevant product recommendations. The best part is that all this data is collected in real-time so the software can react as the consumer preference or shopping habits alters.
- Deliver A Consistent Brand Experience
Recommendation engine AI can be key to creating a consistent brand experience by simply drawing data from various channels. It allows you to optimize your omnichannel customer experience and make customers feel part of an ongoing journey instead of starting afresh with each interaction.
Serving your customers with more personalized recommendations across various channels they interact with you, including email, web, and the in-store app, can also allow you to build a long-lasting and robust connection with them.
- Drives Website Traffic
Using a recommendation engine allows you to bring targeted traffic to your website. The recommender system can achieve this with specifically targeted blasts and personalized email messages.
5 Key Applications of Recommendation Engines

Here are the top 5 use cases of recommendation engines.
1. eCommerce Platforms
Recommendation engines are a crucial tool for eCommerce businesses seeking a competitive edge. This concept was developed by Amazon in 2021, which recommended products to buyers using item-item collaborative filtering.
This practice resulted in a whopping 29% increase in sales compared to the previous quarter. Eventually, this approach increased the purchases on the platform by 35%.
To this day, Amazon uses its recommendation engine as its USP to maintain its position as a market leader. Furthermore, they’ve also leveraged this capability in their streaming platform - Amazon Prime.
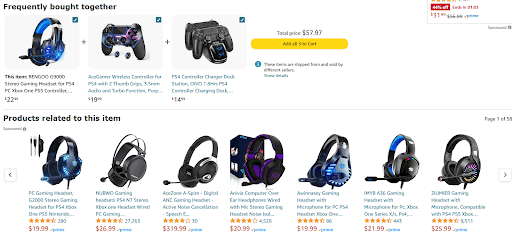
The recommendation engine forecasts user behavior and interests with its intuitive understanding of the user. It fosters enhanced cart volume, upsells, and cross-sells and promotes engagement to drive purchases, diminishing cart abandonment.
Following Amazon’s footsteps, retailers like H&M, Pandora, and ASOS have also leveraged recommender systems to achieve positive results.
2. Media Recommendations
The power of recommender systems has not only been leveraged by Amazon. Platforms like Spotify, Netflix, Disney+Hotstar, and YouTube have also devised intelligent recommendation systems. Today, recommendations are just something every app, website, or platform offers.
Media platforms cultivate a sense of user preferences to suggest new content accordingly. Moreover, as these engines are equipped with AI, they utilize their self-learn ability to offer increased engagement levels and decrease churn ratio.

For instance, about 75% of content users watch on Netflix is due to their recommendation algorithm. The company feels its personalized recommendation engine is worth a considerable sum of USD 1B/year. It contributes to sustaining and increasing subscription rates while delivering a splendid ROI that the company can invest in creating fresh content.
3. Video Games & Stores
Video games present a fortune of user data ranging from games to decisions. Such data that encompass a user’s activity, responses, and behavior is used by programmers to create experiences that generate revenue while not being perceived as pushy.
Gaming platforms such as PlayStation Store, Xbox Games Store, and Steam intelligently study a gamer’s playing history to garner recommendations. For instance, individuals interested in battle royale games like PUBG will receive suggestions for games like CoD, not multiplayer online role-playing games like World of Warcraft.
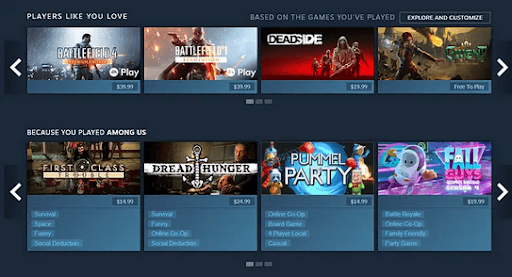
Additionally, video games leverage AI-fueled recommender engines to lead players toward making in-game purchases. They aim to offer players a more refined or rewarding experience by spending money on small transactions.
Eventually, these players can be guided to invest in higher-value purchases that help enhance the platform’s revenue and player’s experience.
4. Location-Centric Recommendations
Learning where your customers are presents a huge business opportunity. It’s crucial information that can enhance your sales, marketing, and advertising efforts.
For instance, Foursquare, a known cloud-based platform, unlocks the power of location for users and suggests fun activities, breweries, restaurants, and more. Starbucks also uses its app to share nearby stores and happy hours. It cultivates engagement amongst users while increasing profitability for local businesses.
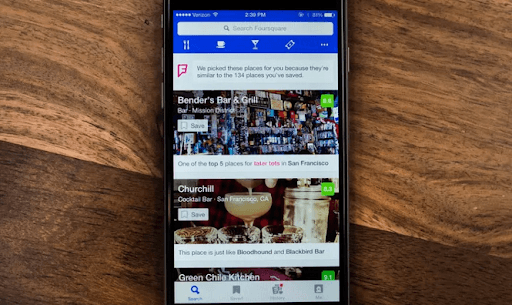
5. Health & Fitness
This business domain is relatively new for recommender systems but possesses a vast potential. Health and fitness apps collect data about a user’s height, weight, fitness goals, and more to suggest workout regimes, yoga and meditation practices, and diet recipes, helping them reach their fitness goals.
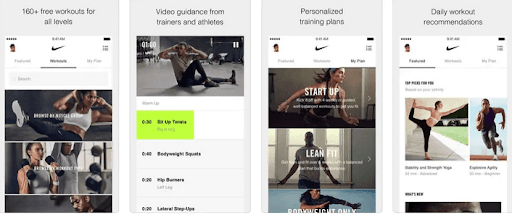
These experiences can be more personalized when connected with wearables. For instance, suggesting measures with an increase in vital signs.
Furthermore, these apps efficiently use user experience, feedback, and ratings, offering intelligent recommendations. For example, if users find an exercise regime too simple, they can increase difficulty sharing more thoughtful and personalized recommendations.
Top 5 Industry Applications of Recommendation Engines
Recommendation engines are transforming industries by enabling personalized experiences, driving engagement, and boosting revenue. From e-commerce to healthcare, they tailor solutions that improve satisfaction, efficiency, and long-term business growth.
1. E-Commerce
In e-commerce, recommendation engines drive revenue by suggesting complementary products, upselling premium versions, and creating dynamic bundles tailored to each shopper’s behavior. By analyzing browsing patterns, purchase history, and real-time interactions, platforms like Amazon or Flipkart can personalize shopping journeys.
This not only improves conversion rates but also enhances customer satisfaction, as users receive curated recommendations aligned with their interests. Dynamic bundling further increases cart value by offering logical combinations, from clothing ensembles to tech accessories.
2. Media & Entertainment
In media and entertainment, recommendation engines personalize viewing and listening experiences. Netflix leverages collaborative filtering and deep learning to suggest shows and movies based on user preferences and community patterns.
Similarly, Spotify generates curated playlists, blending user history with real-time listening behavior. These tailored suggestions keep users engaged, reduce churn, and promote content discovery.
By constantly refining recommendations, platforms maintain a competitive edge while delivering a more enjoyable and immersive user experience for audiences worldwide.
3. Finance
In finance, recommendation engines are reshaping how individuals make investment decisions. By analyzing transaction history, spending patterns, and market data, financial platforms can suggest customized savings plans, investment opportunities, or credit products.
Robo-advisors use recommendation algorithms to offer portfolio rebalancing strategies and risk-adjusted investment suggestions. This personalization empowers customers to make informed financial decisions while increasing engagement and trust.
For banks and fintechs, these systems enhance cross-selling and client retention by aligning offerings with individual financial goals.
4. Healthcare
Healthcare platforms use recommendation engines to provide patients with personalized wellness content, treatment reminders, and tailored care plans.
By leveraging medical history, lifestyle data, and even wearable device inputs, these systems suggest preventive care measures, fitness routines, or therapy follow-ups.
For providers, recommendation engines improve patient engagement and adherence, resulting in better health outcomes. From personalized mental health resources to chronic disease management, these engines ensure care delivery is proactive, patient-centered, and aligned with individual health needs.
5. SaaS / B2B
In SaaS and B2B applications, recommendation engines play a vital role in user retention and product adoption. By analyzing how customers interact with a platform, they suggest relevant features, integrations, or workflows to maximize value.
For example, a CRM might recommend automation tools to sales reps or analytics dashboards to managers. These nudges accelerate onboarding, improve product stickiness, and encourage upselling of premium functionalities.
Ultimately, recommendation engines ensure businesses unlock greater ROI by aligning software use with organizational goals.
Future Trends: AI & Generative AI in Recommendation Engines
The future of recommendation engines lies in deeper personalization powered by AI and generative AI. Emerging technologies will transform how businesses deliver relevant content, improve engagement, and anticipate customer needs in real time.
1. Personalization
Transformers and embeddings are redefining personalization by capturing nuanced relationships in massive datasets. Unlike traditional models, they consider context, intent, and semantics to deliver highly accurate recommendations.
From understanding subtle shopping preferences to mapping complex content consumption patterns, these advancements enable richer, more adaptive recommendation engines that evolve with each interaction.
2. Creating Personalized Product Content
Generative AI enhances recommendation engines by generating personalized product titles, descriptions, and even images. Instead of generic catalog entries, users receive content that resonates with their interests and context.
This innovation improves discoverability, boosts conversion rates, and ensures e-commerce platforms stand out with compelling, hyper-relevant, and engaging product experiences.
3. Customer Interactions
Conversational recommenders powered by large language models (LLMs) are reshaping customer interactions. Rather than static suggestions, chatbots now engage users in natural dialogue, understanding intent and preferences dynamically.
This conversational approach personalizes recommendations in real time, improving satisfaction, guiding decision-making, and turning customer support channels into intelligent product discovery tools.
4. Real-Time Contextual Recommendations
Real-time contextual recommendations analyze live user behavior such as location, device, and recent interactions—to deliver hyper-relevant suggestions instantly.
Whether offering a timely playlist, product, or healthcare tip, these engines adapt to the moment. This capability drives higher engagement, immediate value delivery, and fosters customer loyalty through responsiveness and personalization.
In Conclusion
Recommendation engines today serve as the key to the success of any online business. But, for a sound recommendation system to make relevant recommendations in real-time requires powerful abilities to correlate not just the product but also customer, inventory, logistics, and social sentiment data.
All in all, recommender systems can be a powerful tool for any e-commerce business, and rapid future developments in the field will increase their business value even further.
With a wide range of business applications, including anticipating seasonal purchases based on recommendations, determining essential purchases, and offering better suggestions to customers, brands can leverage recommender systems for two key areas – brand loyalty and enhanced customer retention.
The first step to having great product recommendations for your customers is really just having the courage to dive into better conversions. And remember – the only way to truly engage with customers is to communicate with each as an individual.
However, developing a recommendation engine takes a great deal of data expertise. Your recommendation engine is only as effective as it is built to be. At Maruti Techlabs, our machine learning experts are well-versed with techniques like deep learning, supervised learning, unsupervised learning, reinforcement learning, etc.
If you wish to improve your recommender systems with these cognitive computing methods or simply want to learn more about how machine learning solutions can resolve your business challenges, get in touch with us today.
FAQs
1. What is a recommendation engine example?
A popular example is Netflix, which uses recommendation engines to suggest shows and movies based on viewing history, preferences, and patterns across millions of users.
By analyzing behavior with advanced algorithms, Netflix personalizes entertainment choices, keeping users engaged, reducing churn, and highlighting new content that aligns with individual tastes and community trends.
2. What are the main benefits of using a recommendation engine?
Recommendation engines offer businesses major benefits: improved customer engagement, increased conversion rates, and higher revenue through upselling and cross-selling.
They enhance personalization, making customers feel understood. Additionally, they streamline product discovery, reduce decision fatigue, and build long-term loyalty by continuously adapting suggestions to user behavior, preferences, and real-time contextual signals.
3. What industries use recommendation engines the most?
E-commerce, media and entertainment, finance, healthcare, and SaaS are leading adopters of recommendation engines. Amazon uses them for upselling, Netflix for content discovery, and fintechs for personalized investments.
Healthcare platforms recommend wellness plans, while SaaS tools nudge feature adoption. These industries leverage recommendation engines to drive personalization, engagement, and business growth.
4. How does AI improve recommendation engines?
AI improves recommendation engines by enabling smarter personalization through deep learning, embeddings, and real-time analytics. Unlike rule-based systems, AI can process vast, unstructured data including behavior, context, and preferences to deliver accurate, dynamic suggestions.
It enhances adaptability, automates content generation, and powers conversational recommenders, creating more engaging, human-like interactions that improve user satisfaction.
5. What challenges come with recommendation engines?
Recommendation engines face challenges like data quality issues, bias in algorithms, and cold-start problems for new users or items. Privacy and regulatory compliance add complexity, requiring secure handling of sensitive data.
Additionally, balancing personalization with diversity, maintaining transparency, and ensuring models remain accurate over time require continuous monitoring, retraining, and governance.





