Unsure About Kubernetes for LLMs? Here’s How to Make the Right Choice
A simple guide to help you decide if Kubernetes fits your LLM workloads, with key benefits, limitations, and easier alternatives explained.
Devops
Unsure About Kubernetes for LLMs? Here’s How to Make the Right Choice
A simple guide to help you decide if Kubernetes fits your LLM workloads, with key benefits, limitations, and easier alternatives explained.
Table of contents
Table of contents
Introduction
5 Benefits of Running LLMs on Kubernetes
Drawbacks and Limitations of Running LLM Workloads on Kubernetes
When to Use Kubernetes for AI and LLM Inference
When Kubernetes May Not Be the Best Fit for AI and LLM Inference
Alternatives to Kubernetes for LLM Workloads
Conclusion
FAQs
Introduction
Large Language Models (LLMs) are now utilized in various AI applications, including chatbots, content creation, and virtual assistants. As more industries adopt them, these models are becoming increasingly larger and more complex to manage. Running them efficiently requires strong infrastructure and careful resource planning.
This is where Kubernetes comes in. Many teams are now utilizing Kubernetes for AI workloads as it streamlines tasks such as scaling, resource allocation, and model deployment. It helps teams test models quickly, run large workloads efficiently, and utilize computing power more effectively. That’s why Kubernetes AI tools are becoming a popular choice for managing AI projects.
However, Kubernetes may not always be the perfect fit. Its setup and management can be complex, especially for smaller teams or simpler use cases.
In this blog, we’ll take a closer look at the benefits of running LLMs on Kubernetes, the drawbacks and limitations of running LLM workloads on Kubernetes, when to use and not to use Kubernetes for AI and LLM inference, and alternatives to Kubernetes for LLM workloads.
5 Benefits of Running LLMs on Kubernetes
Running large language models (LLMs) requires a significant amount of computing power, and Kubernetes makes this task much easier. Here are five key benefits of using Kubernetes for AI workloads:
1. Easy to Scale
LLMs don’t always need the same amount of power. Sometimes they need a lot, sometimes very little. Kubernetes can automatically add or remove resources as needed. So, your system grows when needed and shrinks when not, saving effort and cost.
2. Works Anywhere
You can run Kubernetes on the cloud, on your own servers, or both. It doesn’t lock you into one setup. This makes it easy to start small and grow later without having to redo everything.
3. Easy to Monitor
Kubernetes helps you monitor the performance of your models. You can check things like speed, errors, or how much memory is being used. This helps catch problems early and keep things running smoothly.
4. Good for Large Training Jobs
Training LLMs often involve using multiple machines simultaneously. Kubernetes makes it easier to manage this. It spreads the work across different machines, allowing training to finish faster.
5. Saves Money
Since Kubernetes adds or removes resources only when needed, you don’t pay for extra machines sitting idle. It helps you get the most out of your setup without wasting money.
Drawbacks and Limitations of Running LLM Workloads on Kubernetes
While Kubernetes for AI workloads has many advantages, it’s not always the easiest option, especially when working with Large Language Models (LLMs). There are a few things that can make it challenging to use.
1. Complex Setup and Management
Getting Kubernetes ready for LLM workloads can be difficult. Setting up features such as networking, GPUs, and autoscaling requires time and skill. For teams without extensive Kubernetes experience, this can slow down the process. Managing day-to-day operations can also become challenging, especially as models and workloads grow larger.
2. Slow Start Times
LLMs are big, and so are the containers that hold them. When a new container starts, it may take time to download the image and load the model into memory. This delay is known as a "cold start." In real-time applications, these slow start times can lead to noticeable lags or slow responses.
3. Fewer Built-in Tools for LLMs
Unlike managed AI platforms (such as AWS SageMaker or Google Vertex AI), Kubernetes doesn’t come with tools built explicitly for LLMs. You’ll need to set up your own infrastructure for tasks such as model versioning, serving, monitoring, and scaling. This means more work for your team and a higher risk of things going wrong if not managed carefully.
Kubernetes AI tools give you a lot of control, but they also take time and effort to set up and manage. For some teams, that extra work makes sense. But for others, especially those with smaller projects or limited resources, it might feel like more trouble than it's worth.
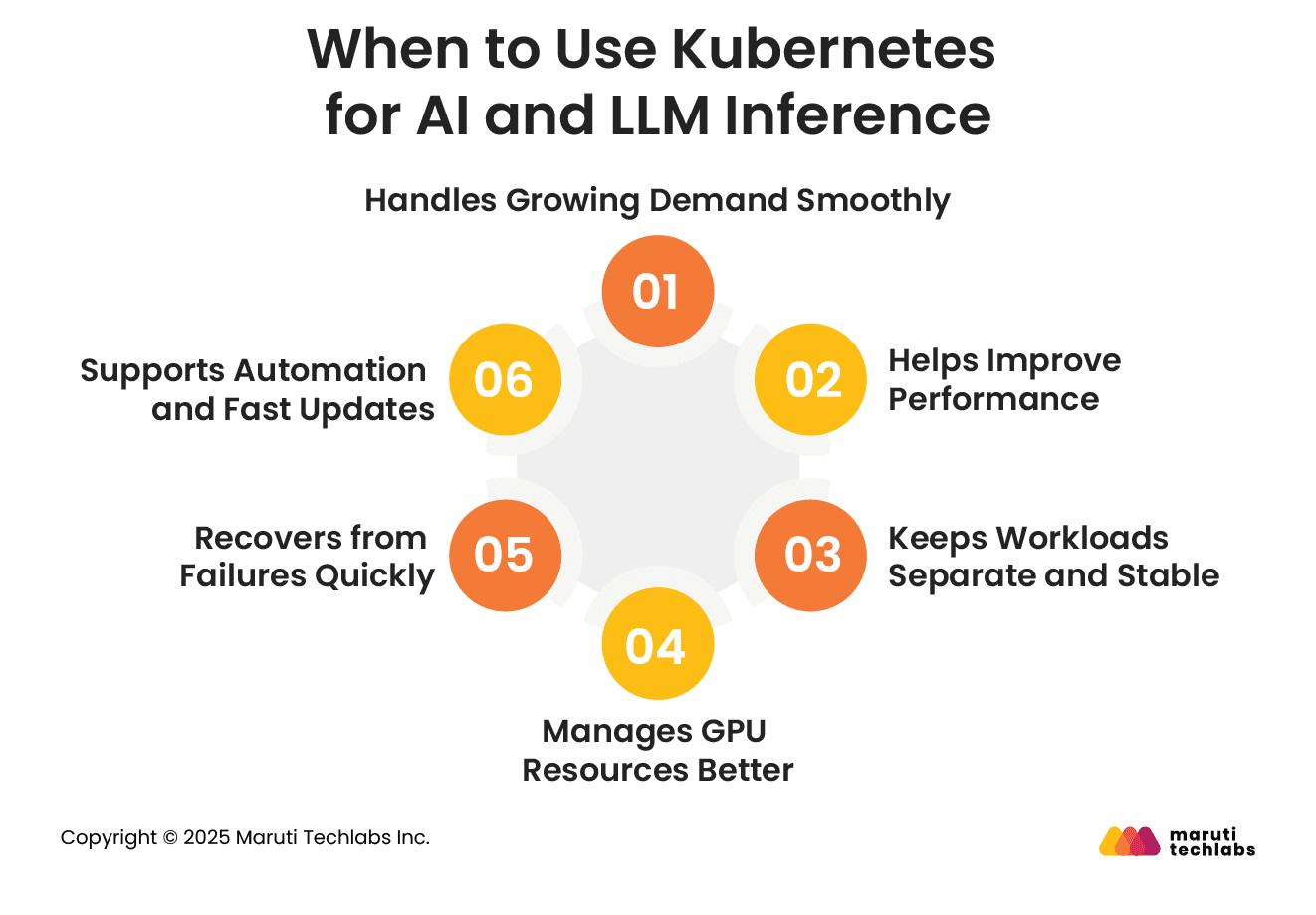
When to Use Kubernetes for AI and LLM Inference
Kubernetes can be a great fit for AI and LLM inference workloads in many situations. Here are some key reasons to consider it:
1. Handles Growing Demand Smoothly
If your AI application requires support for a large or fluctuating number of users, Kubernetes makes it easy to scale up or down. With built-in auto-scaling features, it can automatically add more resources when needed and reduce them when the load is low. This helps maintain smooth performance without wasting resources.
2. Helps Improve Performance
Although inference requires less power than training, it still requires significant computing support. Kubernetes helps distribute the workload efficiently across resources, such as CPUs and GPUs. This improves speed and keeps your systems running well under different loads.
3. Keeps Workloads Separate and Stable
AI tasks often involve multiple steps, such as data processing, testing, and fine-tuning. Kubernetes runs each task in its own container, ensuring that one task does not interfere with another. This makes your system more stable, even when running multiple jobs simultaneously.
4. Manages GPU Resources Better
LLM workloads typically require powerful hardware, such as GPUs. Kubernetes can automatically assign the right GPU to the right job. It ensures that your hardware is fully used and nothing is left sitting idle.
5. Recovers from Failures Quickly
If a part of your system stops working, Kubernetes quickly restarts it or moves the task to another healthy machine. This keeps your AI applications running with minimal downtime.
6. Supports Automation and Fast Updates
Kubernetes works well with automation tools, enabling you to build, test, and deploy new models more quickly. It supports continuous updates so your AI systems stay current without manual work.
When Kubernetes May Not Be the Best Fit for AI and LLM Inference
While Kubernetes is powerful, it’s not always the right choice for every AI project. In some cases, using it might add more complexity than needed.
If you're working on a small or early-stage AI project, Kubernetes can feel like too much. Setting it up and managing it requires time, tools, and experience. For quick tests or small models, simpler platforms or managed services are often a better fit.
Kubernetes may not be ideal for real-time applications where every second counts, such as chatbots that require instant responses. Since LLM containers can be large and slow to load, delays (also called “cold starts”) can affect performance in such cases.
Another factor to consider is the skill set of your team. If your team lacks experience with DevOps or managing ML infrastructure, Kubernetes can be overwhelming. It has a learning curve and requires careful setup to work well.
In these situations, managed AI platforms like AWS SageMaker or Google Vertex AI may be easier to use and maintain. They offer numerous built-in tools for training and deploying models, reducing manual work.
Kubernetes offers flexibility and control, but it’s not the only way to run Large Language Models (LLMs). If your team is looking for something easier to manage, there are other options worth exploring.
Alternatives to Kubernetes for LLM Workloads
Kubernetes gives you a lot of control, but it’s not always the easiest way to run large language models. If you're looking for something simpler to manage, there are a couple of good options to consider.
1. Serverless LLM Platforms
Serverless platforms make things easier by handling all the setup in the background. You don’t need to worry about servers or scaling your model; it all happens automatically. The model runs only when needed, which is ideal for smaller projects or those with fluctuating traffic. Tools like Modal, Replicate, or AWS Lambda let you spend more time building your model and less time worrying about how to run it.
2. Managed AI Services
Managed AI services are offered by cloud providers and come with built-in tools for training, deploying, and managing models. Services like AWS SageMaker, Google Vertex AI, and Azure Machine Learning handle a lot of the hard work for you. You get features like version control, auto-scaling, and easy model updates, all with less setup.
These platforms are especially useful for teams without much DevOps experience or those who want a faster way to go from idea to deployment.
The alternatives can save time and reduce complexity, making them great options for many teams working with LLMs.
Conclusion
Kubernetes is a suitable choice for running large, complex LLM workloads that require scaling and support multiple teams or processes. It offers flexibility and strong control, but also needs more setup and technical know-how.
On the other hand, if your project is smaller, needs quick responses, or you want to avoid managing infrastructure, serverless platforms or managed AI services might work better. They’re easier to get started with and require less ongoing effort.
The best option depends on your workload size, response time needs, and your team’s experience with infrastructure.
1. Which tool is specifically designed to extend Kubernetes for AI workflows?
Kubeflow is a tool made to run machine learning and AI workflows on top of Kubernetes. It helps manage steps like training, tuning, and serving models, so teams don’t have to build everything from scratch.
2. What functions does Kubernetes perform in the context of deploying AI models?
Kubernetes helps run AI models by handling scaling, resource use, and container management. It makes sure your models stay available, adjust to demand, and run smoothly across different environments.
3. What are the limitations of Kubernetes for running LLM workloads?
Kubernetes can be hard to set up, especially for small teams. LLMs may load slowly, causing delays. Also, Kubernetes doesn’t come with built-in tools for LLMs, so you’ll need to manage many things manually.
4. Which three features of Kubernetes make it suitable for managing AI/ML clusters?
Kubernetes works well for AI/ML clusters because it can scale resources automatically, manage hardware like GPUs efficiently, and keep different tasks separate to avoid conflicts or errors.
Lalit Bhatt works across cloud infrastructure, DevOps, and project delivery, bringing 18+ years of experience across cloud migration, AWS architecture, infrastructure improvements, and team mentoring, depending on what clients need.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!