

Introduction to Sentiment Analysis: Concept, Working, and Application
With advancements in technology and fields like deep learning, sentiment analysis is becoming more and more common for companies that want to gauge their customers’ sentiments.
Today, businesses use natural language processing, statistical analysis, and text analysis to identify the sentiment and classify words into positive, negative, and neutral categories.
The best companies understand the importance of understanding their customers’ sentiments – what they are saying, what they mean and how they are saying. You can use sentiment analysis to identify customer sentiment in comments, reviews, tweets, or social media platforms where people mention your brand.
As sentiment analysis is the domain of understanding emotions using software, we have prepared a complete guide to understand ‘what is sentiment analysis?’, its tools, and different classifications and use cases.
What is Sentiment Analysis?
Sentiment analysis can be defined as analyzing the positive or negative sentiment of the customer in text. The contextual analysis of identifying information helps businesses understand their customers’ social sentiment by monitoring online conversations.
As customers express their reviews and thoughts about the brand more openly than ever before, sentiment analysis has become a powerful tool to monitor and understand online conversations. Analyzing customer feedback and reviews automatically through survey responses or social media discussions allows you to learn what makes your customer happy or disappointed. Further, you can use this analysis to tailor your products and services to meet your customer’s needs and make your brand successful.
Recent advancements in AI solutions have increased the efficiency of sentiment analysis algorithms. You can creatively use advanced artificial intelligence and machine learning tools for doing research and draw out the analysis.
For example, sentiment analysis can help you to automatically analyze 5000+ reviews about your brand by discovering whether your customer is happy or not satisfied by your pricing plans and customer services. Therefore, you can say that the application of sentiment is endless.
Types of Sentiment Analysis
The sentiment analysis process mainly focuses on polarity, i.e., positive, negative, or neutral. Apart from polarity, it also considers the feelings and emotions(happy, sad, angry, etc.), intentions(interested or not interested), or urgency(urgent or not urgent) of the text.

Depending on how you interpret customer feedback, you can classify them and meet your sentiment analysis. However, below are some of the popular sentiment analysis classifications:
1. Fine-grained Sentiment Analysis
If your business requires the polarity precisions, then you can classify your polarity categories into the following parts:
- Very positive
- Positive
- Neutral
- Negative
- Very Negative
For polarity analysis, you can use the 5-star ratings as a customer review where very positive refers to a five-star rating and very negative refers to a one-star rating.
2. Emotion Detection
This type of sentiment analysis helps to detect customer emotions like happiness, disappointment, anger, sadness, etc. Here, you can use sentiment lexicons or complex machine learning algorithms to identify the customer’s feelings.
One of the disadvantages of using sentiment lexicons is that people tend to express emotions in different ways. So, it may be confusing to understand human emotion clearly while using it.
3. Aspect-based Sentiment Analysis
Let’s say that you are analyzing customer sentiment using fine-grained analysis. You want to identify the particular aspect or features for which people are mentioning positive or negative reviews. Here, aspect-based sentiment analysis comes into play.
For instance, in the review “The camera quality of this phone is getting worse with time,” an aspect-based classifier will determine that the review expresses a negative opinion from the customer for the phone’s camera feature.
4. Multilingual Sentiment Analysis
Multilingual sentiment analysis is complex compared to others as it includes many preprocessing and resources available online (i.e., sentiment lexicons). Businesses value the feedback of the customer regardless of their geography or language. Therefore, multilingual sentiment analysis helps you identify customer sentiment irrespective of location or language difference.
Importance of Sentiment Analysis
The most crucial advantage of sentiment analysis is that it enables you to understand the sentiment of your customers towards your brand. Your products and services can be improved, and you can make more informed decisions by automatically analyzing the customers’ feelings and opinions through social media conversations, reviews, surveys, and more.
According to the survey, 90% of the world’s data is unstructured. Especially in businesses, emails, tickets, chats, social media conversions, and documents are generated daily. Therefore, it is hard to analyze all this vast data in a timely and efficient manner.
Let us look at the overall benefits of sentiment analysis in detail:
Sort Data at Scale
There is too much business data to analyze daily. Can you imagine sorting all these documents, tweets, customer support conversations, or surveys manually? Sentiment analysis will help your business to process all this massive data efficiently and cost-effectively.
Real-Time Analysis
Is your angry customer about to churn? Is a PR crisis on social media escalating? Sentiment analysis will help you handle these situations by identifying critical real-time situations and taking necessary action right away.
Consistent Criteria
According to research, customers only agree for 60-65% while determining the sentiment of the particular text. Tagging text is highly subjective, influenced by thoughts and beliefs, and also includes personal experience. Therefore, you can apply criteria and filters to all your data, improve their accuracy, and gain better insights using sentiment analysis.
How Does Sentiment Analysis Work?
Sentiment analysis works with the help of natural language processing and machine learning algorithms by automatically identifying the customer’s emotions behind the online conversations and feedback.
Depending on the amount of data and accuracy you need in your result, you can implement different sentiment analysis models and algorithms accordingly. Therefore, sentiment analysis algorithms comprise one of the three buckets below.
1. Rule-Based Approach
The rule-based system performs sentiment analysis based on manually crafted rules to identify polarity, subjectivity, or the subject of an opinion.
These rules contain different natural language processing techniques developed in computational linguistics like stemming tokenization, parsing, lexicons(list of words and expressions), or part of speech tagging.
For instance, you define two lists of polarized words, i.e., negative words(bad, worst, ugly, etc.) and positive words(good, best, beautiful, etc.). You have to count the number of positive and negative words in the text. If the number of positive words is greater than negative words, the text returns the positive sentiment and vice versa. If the number of negative and positive words is equal, then the text returns the neutral sentiment.
Since the rule-based system does not consider how words are combined in the sequence, this system is very naive. However, new rules can be added to support the new expression and vocabulary of the system by using more advanced processing techniques. But these will also add complexity to the design and affect the previous results.
2. Automatic Approach
Unlike rule-based systems, the automatic approach works on machine learning techniques, which rely on manually crafted rules. Here, the sentiment analysis system consists of a classification problem where the input will be the text to be analyzed. It will return a polarity if the text, for example, is positive, negative, or neutral.
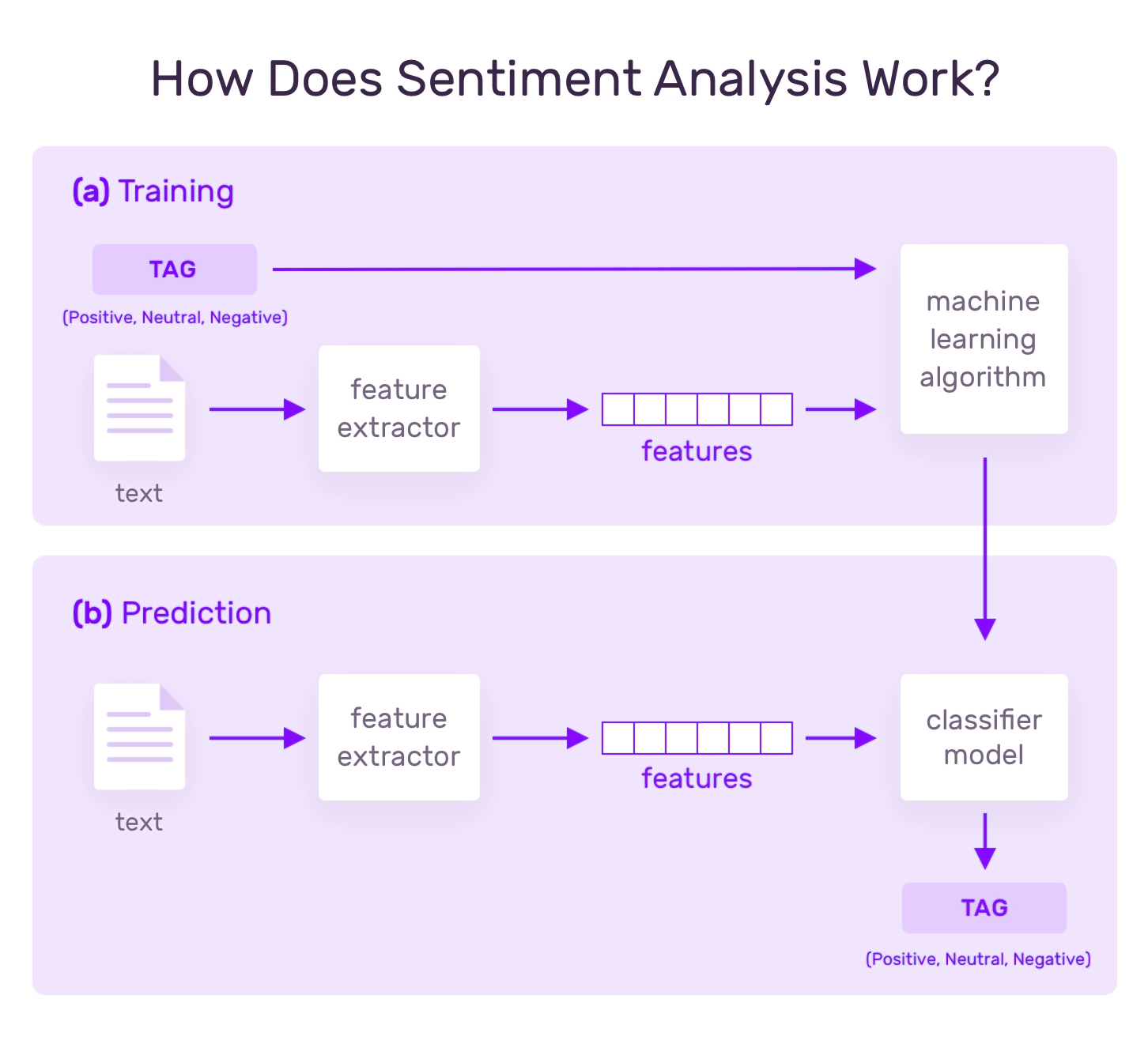
a]Training and Prediction
In the training process, your model links with a particular input(i.e., text) to the corresponding output based on the test sample. The feature extractor will help to transfer the input to the feature vector. These pairs of feature vectors and the tags provided are transferred to the machine learning algorithm to generate a model.
In the prediction process, the feature extractor transforms the unidentified text inputs into feature vectors. Further, these feature vectors generate the predicted tags like positive, negative, and neutral.
b]Feature Extraction from Input Text
Machine learning text classifiers will transform the text extraction using the classical approach of bag-of-words or bag-of-n-grams with their frequency. A new feature extraction system is created on word embeddings known as word vectors.
This kind of representation helps to improve the performance of classifiers by making it possible for words with similar meanings to have similar presentations.
Classification Algorithms
Various classification algorithms involve statistical modelings like naive Bayes, support vector machines, deep learning, or logistic regression. Let us discuss them in detail below:
- Naive Bayes: It is a family of probabilistic algorithms that predict the category of a text by using the Bayes theorem.
- Support Vector Machines: It is a non-probabilistic model that uses a representation of the input text as a point in multi-dimensional space. Different text categories map to distinct regions within the space because the new texts are categorized based on the similarity with the existing text and the region they are mapping.
- Deep Learning: A family of algorithms that attempts to mimic the human brain with the help of artificial neural networks to process the data.
- Linear Regression: A family of algorithms in statistics that helps to predict some value (y) for a given set of features (x).
3. Hybrid Approaches
The hybrid model is the combination of elements of the rule-based approach and automatic approach into one system. A massive advantage of this approach is that the results are often more accurate and precise than the rule-based and automated approaches.
Sentiment Analysis: Machine Learning Approach
The above approaches were good enough to implement the sentiment analysis but very hard to elaborate on. Therefore, a machine learning approach was introduced to apply the sentiment analysis model effectively and carry out word representations in a vector space.
It would help if you considered connecting with a Natural Language Processing consulting service to educate yourself on the latest NLP trends.
Word Representations in a Vector Space
Feature Extraction
Firstly, you must represent your sentences in a vector space while building a deep learning sentiment analysis model. Frequency-based methods represent a sentence either by bag-of-words (list of the words that appear in the sentence with their frequencies) or by term frequency-inverse document frequency vector (the word frequencies in your sentences weights with their frequencies in the entire corpus).
These methods are beneficial for long texts. For instance, you can efficiently classify a newspaper article or a book by its most frequently used words. But if the sentences are short, the results will not be so accurate. At the same time, the sentence structure is also essential to identify while analyzing the sentiments because tf-IDF models rarely capture the negations, concessions, and amplification. For example, the text “Excellent camera but bad battery life.” will have the same effect as “Bad camera but excellent battery life.”
Word Vectors
When you represent the text with vectors, the vectors consider both the words and the semantic structure of the text. You must define every word with an n-feature vector and represent the sentence with an n*length matrix. For instance, you can create a vector of the same size as the vocabulary, and to describe the ith word, use 1 and 0 elsewhere.
Tomas Mikolov created a new way to represent words in a vector space. He trains the neural network model on a vast corpus that defines the term “ants” by the hidden layer’s output vector. These word vectors capture the semantic information as it captures enough data to analyze the statistical repartition of the word that follows “ant” in the sentence.
The exact process is followed here, i.e., an index vector represents every word. This small vector is the input of a convolution neural network. Further, it is integrated into the deep learning model as a hidden layer of linear neurons and converts these significant vectors into small parts.
Therefore, the model trains as a whole so that the word vectors you use are enough to fit the sentiment information of the word, i.e. the features you get capture enough data on the terms to predict the sentiment of the text.
Click here to learn about predictive maintenance machine learning techniques.
Sentence Representation
You have to build the representation of the sentence that considers words of the text and the semantic structure. The easiest method is to create a matrix and superpose of these word vectors that represent the text.
According to Tomas Mikolov, you can also do this by the method called Doc2Vec. Here, he modifies the neural network used for the Word2Vec and takes input as a word vector and vector that depends on the sentence. Later, this word vector is considered a parameter to the model and optimized using gradient descent. By doing this, you will have a set of features for every sentence that represents the structure of the sentence.
Pros and Cons of Sentiment Analysis
As discussed earlier, the customer writing positive or negative sentiment will differ by the composition of words in their reviews. Therefore, feeding the logistic regression to these vectors and training the regression to predict the feelings from the given text is one of the best sentiment analysis methods, especially using the fine-grained classification.
It is not an easy task to build the document vector for the given sentence. You have to run a gradient descent algorithm to search for the right coefficient for this vector in every sentence. Therefore, the Doc2Vec classification needs a significant hardware investment that takes much longer to process than other sentiment analysis methods where the preprocessing is a shorter algorithm.
Convolution Neural Networks
For text classification, another method you can consider combines a multilayer computer vision neural network with a convolution layer, dense layers of neurons with sigmoid activation function, and additional layers designed to prevent overfitting. Convolutional layers are a technique designed for computer vision services, and it helps to improve the accuracy of image recognition and object detection models.
The basic idea is to apply the convolutions to the image and the set of filters and consider this new image as input to the next layer. Depending on the filer you use, the output image will smooth the edges, capture them, or sharpen the key patterns. You will build highly relevant features to feed the next layer of the model by training the filter’s coefficients.
These features tend to work like local patches that practice compositionality. The model’s training will automatically practice the best patches depending on the classification problem you wish to solve.
Applications in Natural Language Processing
Natural language processing is a popular model which people often try to apply in various other fields like NLP in healthcare, retail, advertising, manufacturing, automotive, etc. For NLP tasks like sentiment analysis, you have to build a word vector and convolve the image developed by juxtaposing these vectors for creating relevant features.
Eventually, the filters will allow you to highlight the intensely positive or negative words in the text. It will also help you understand the relationship between negations and what follows. It will also capture the relevant data about how the words follow each other and learn particular words or n-grams that contain the sentiment information.
Further, it ultimately connects the deep neural network with the outputs of these convolutions and selects the best feature for classifying the sentence’s sentiment.
Long Short Term Memory
Implementing the long short term memory (LSTM) is a fascinating architecture to process natural language. It starts reading the sentence from the first word to the last word. Later after processing each word, it tries to figure out the sentiment of the sentence.
For example, if the sentence is “The camera is worst, and battery backup is bad.” Here, the model will read “The,” then “camera,” then “worst,” “battery,” then “backup,” and at last “bad.” It will consider a vector that represents what comes before memory and a partial output. For instance, it will consider the sentence as negative halfway and update the process with more data.
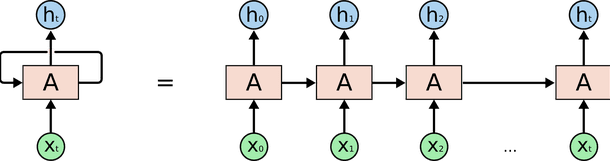
The above image accurately shows the sentiment analysis process in detail. It is very efficient at speech recognition and translation processes. But at the same time, it slows down the evaluation process considerably. So it should be implemented with care.
Challenges Faced During Sentiment Analysis
Sentiment analysis is a difficult task in natural language processing as even humans struggle to analyze sentiments accurately. Let’s look at some challenges of machine-based sentiment analysis:

1. Subjectivity and Tone
As you know, there are two types of text available, i.e., subjective and objective. Subjective texts contain explicit sentiments, while the objective text does not. For example, you want to analyze the sentiment of the following two texts:
The phone is nice
The phone is blue
You will say that the sentiments are positive for the first and neutral for the second. Here, all text predicates should not be treated differently regarding how they create the sentiment. In this example, nice is more subjective in comparison to blue.
2. Context and Polarity
Analyzing sentiment without context gets difficult as machines cannot learn about contexts if it is not trained explicitly. The most crucial disadvantage that arises from context is changing in polarity. Check out the below responses to a survey:
Everything of it
Absolutely nothing!
Consider the question, “What did you like about this phone?” The first response will be positive, and the second response will be negative. Now consider the question, “What did you dislike about this phone?” The negative verb “dislike” in the given question will change the sentiment analysis of the text.
If you consider the tiniest part of the context in the input text, you will need many preprocessing and postprocessing methods.
3. Irony and Sarcasm
When it comes to sarcasm, people tend to express their negative sentiments using affirmative words, making it difficult for machines to detect and understand the context of the situation and genuine emotions.
For instance, consider the question, “Did you enjoy your trip with us?”
Yeah, sure. So enjoyable!
Not one, but many!
If you consider the first response, the exclamation mark displays negation, correct? The challenge here is that there is no textual cue to help the machine understand the sentiment because “yeah” and “sure” are often considered positive or neutral.
However, suppose you consider the second response. In that case, sentiment is positive, but you will also develop many different contexts expressed in negative sentiment.
4. Comparisons
It is quite a challenge to tackle the comparisons while analyzing the sentiment of the text. For instance,
This product is better than others.
The new shop is far from the old one.
I like blue more than orange.
The first response specifies that it is positive. But what about the second and third responses? As mentioned above, context can make a difference in the sentiments of the sentence. In the second response, if the “old one” is considered useless, it becomes a lot easier to classify it.
5. Emojis
According to Guibon, there are two types of emojis, i.e., Western emojis (:D) containing only one or two characters, and Eastern emojis (¯ \ (ツ) / ¯), which have more characters of vertical nature.
Emojis play a prominent role in sentiment analysis, especially while working with tweets. When it comes to analyzing tweets, you will have to pay more attention to character-level and word-level at the same time. And for this purpose, a lot of preprocessing might be needed.
For example, you must preprocess the tweets and convert the eastern emojis and western emojis into tokens. Further, whitelist them, which will improve your sentiment analysis performance.
6. Defining Neutral
When performing accurate sentiment analysis, defining the category of neutral is the most challenging task. As mentioned earlier, you have to define your types by classifying positive, negative, and neutral sentiment analysis. In this case, determining the neutral tag is the most critical and challenging problem. Since tagging data requires consistency for accurate results, a good definition of the problem is a must.
Here are some examples to define neutral texts:
- Objective texts: As objective texts do not contain explicit sentiments, you can include them in the neutral category.
- Irrelevant information: You can tag the irrelevant data of your text as neutral if you haven’t preprocessed your text. But it is recommended to do this only if this data does not affect overall performance. Because sometimes, you may add unnecessary data(noise) to your categorization, and performance can worsen.
- Wishes Texts: You can consider some wishes like “I wish the camera had more clarity” as neutral texts. But at the same time, the texts including comparisons like “I wish the camera were better” are pretty difficult to categorize.
7. Human Annotator Accuracy
Sentiment Analysis is quite a difficult task, whether it’s a machine or a human. When it comes to sentiment analysis, the inter-annotator agreement is very low. And since the machines learn from the humans by the data they feed, sentiment analysis classifiers are not as accurate as other types.
Application of Sentiment Analysis

1. Brand Monitoring
A brand is not defined by the product it manufactures. It depends on how you build a brand by online marketing, social campaigning, content marketing, and customer support services. Getting full 360 views of how your customers view your product, company, or brand is one of the most important uses of sentiment analysis.
Sentiment analysis enables you to quantify the perception of potential customers. Analyzing social media and surveys, you can get key insights about how your business is doing right or wrong for your customers.
Companies tend to use sentiment analysis as a powerful weapon to measure the impact of their products and campaigns on their customers and stakeholders. Brand monitoring allows you to have a wealth of insights from the conversions about your brand in the market. Sentiment analysis enables you to automatically categorize the urgency of all brand mentions and further route them to the designated team.
Keeping the feedback of the customer in knowledge, you can develop more appealing branding techniques and marketing strategies that can help make quick transitions.
2. Customer Service
Customer service companies often use sentiment analysis to automatically classify their user incoming calls into “urgent” and “not urgent” classes. The classification is based on the sentiments of the emails or proactively identifying the calls of frustrated customers.
The customer expects their experience with the companies to be intuitive, personal, and immediate. Therefore, the service providers focus more on the urgent calls to resolve users’ issues and thereby maintain their brand value. Therefore, analyze customer support interactions to make sure that your employees are following the appropriate process. Moreover, increase the efficiency of your services so that customers aren’t left waiting for support for longer periods.
As the customer service sector has become more automated using machine learning, understanding customers’ sentiments has become more critical than ever before. For the same reason, companies are opting for NLP-based chatbots as their first line of customer support to better grasp context and intent of the conversations.
3. Finance and Stock Monitoring
It is said that “Be fearful when others are greedy and be greedy when others are fearful.” But here, the question that arises: how do you know if others are fearful or greedy? Well, here, you can make use of the sentiment analysis technique. Making investments, especially in the business world, is quite tricky. The stocks and market are always on the edge of risks, but they can be condensed if you do correct research before investing.
For instance, if you are looking to invest in the automobile industry and are confused about choosing between company X and company Y, you can look at the sentiments received from the company for their latest products. It will help you to find the one that is performing better in the market.
4. Business Intelligence Buildup
Digital marketing plays a prominent role in business. Social media often displays the reactions and reviews of the product. When you are available with the sentiment data of your company and new products, it is a lot easier to estimate your customer retention rate.
Sentiment analysis enables you to determine how your product performs in the market and what else is needed to improve your sales. You can also analyze the responses received from your competitors. Based on the survey generated, you can satisfy your customer’s needs in a better way. You can make immediate decisions that will help you to adjust to the present market situation.
Business intelligence is all about staying dynamic. Therefore, sentiment analysis gives you the liberty to run your business effectively. For example, if you come up with a big idea, you can test and analyze it before bringing life to it.
5. Enhancing the Customer Experience
A satisfying customer experience means a higher chance of returning the customers. A successful business knows that it is important to take care of how they deliver compared to what they deliver.
Brand Monitoring offers us unfiltered and invaluable information on customer sentiment. However, you can also put this analysis on customer support interactions and surveys.
NPS (Net Promoter Score) surveys help you gain feedback for your business with the simple question: Will you recommend this brand, product, or service to your friend or family? The output is a single score on the number scale. Businesses use these sentiment scores to analyze the customer as promoters, detractors, and passives.
Here the goal is to find the overall customer experience and elevate your customer to promoter level. Theoretically, include the phases as: will buy more, stay longer and refer to another customer.
The next step in the NPS survey is to ask survey participants to leave the score and seek open-ended responses, i.e., qualitative data. Qualitative surveys are far more challenging to analyze. Still, with the help of sentiment analysis, these texts can be classified into multiple categories, which offer further insights into customers’ opinions.
As mentioned earlier, the experience of the customers can either be positive, negative, or neutral. Depending on the customers’ reviews, you can categorize the data according to its sentiments. This classification will help you properly implement the product changes, customer support, services, etc.
Also, remember that getting a positive response to your product is not always enough. The customer support services of your company should always be impeccable irrespective of how phenomenal your services are.
6. Market Research and Analysis
Business intelligence uses sentiment analysis to understand the subjective reasons why customers are or are not responding to something, whether the product, user experience, or customer support.
Sentiment analysis will enable you to have all kinds of market research and competitive analysis. It can make a huge difference whether you are exploring a new market or seeking an edge on the competition.
You can review your product online and compare them to your competition. You can also analyze the negative points of your competitors and use them to your advantage.
Sentiment analysis is used in sociology, psychology, and political science to analyze trends, opinions, ideological bias, gauge reaction, etc. A lot of these sentiment analysis applications are already up and running.
Conclusion
The era of getting valuable insights from surveys and social media has peaked due to the advancement of technology. Therefore, it is time for your business to be in touch with the pulse of what your customers are feeling. Companies are using intelligent classifiers like contextual semantic search and sentiment analysis to leverage the power of data and get the deepest insights.
Formulate business strategies, exceed customer expectations, generate leads, build marketing campaigns, and open up new avenues for growth through natural language processing solutions.
Maruti Techlabs’ developers help you model human language and recognize the underlying meaning behind the words said or the action performed. We take communication beyond words and help to interpret human language and behavior.
Are you looking to interpret customer sentiments for increasing brand value? Drop us a note here, and we’ll take it from there.





