The Hidden Challenges of Scaling Data Products and Practical Fixes
Learn the pitfalls and best practices of scaling data products across your enterprise.
Data Analytics and Business Intelligence
The Hidden Challenges of Scaling Data Products and Practical Fixes
Learn the pitfalls and best practices of scaling data products across your enterprise.
Table of contents
Table of contents
Introduction
What You Need to Know About Data Products?
Common Pitfalls That Prevent Data Products from Scaling in Large Organizations
5 Practical Lessons for Scaling Data Products at Enterprise Level
Conclusion
Introduction
Data products are more than just dashboards or analytics tools. They’re a blend of data, user experience, and governance designed to solve real business problems and drive decisions across teams.
However, building one useful data product differs significantly from scaling it across an entire enterprise. Many teams face hurdles like unclear ownership, inconsistent data, or low user adoption when they try to grow their efforts. These issues can slow progress and reduce trust in data systems.
In this blog, we’ll explore what data products are, the five most common mistakes companies make when trying to scale them, and practical lessons for doing it the right way. Whether you’re just starting or trying to scale existing efforts, this guide will help you stay on track and build data products that actually deliver value at scale.
What You Need to Know About Data Products?
A data product is a complete, reusable package combining raw data, context (metadata and definitions), and tools such as dashboards, pre-built queries, machine learning models, or data pipelines. These products are built to serve real business needs and can support a variety of users and use cases across the company.
What sets data products apart is the product-thinking approach behind them. Like building a software product, creating a data product starts with understanding who will use it and what problems it should solve. It’s not just about delivering data; it’s about delivering value. Teams focus on high-impact features first, gather feedback regularly, and improve the product over time.
Well-designed data products are easy to find, connect with other tools, and take action on. They help everyone, from analysts and engineers to decision-makers, unlock insights from data that might otherwise stay buried. By treating data as a product, organizations can build scalable, maintainable, and truly useful solutions.
Common Pitfalls That Prevent Data Products from Scaling in Large Organizations
Scaling data products across an enterprise isn’t easy. While the concept sounds straightforward, many teams run into similar challenges that slow them down or stop them altogether. Below are five common pitfalls that can derail your efforts:
1. Treating Data Products Like One-Off Dashboards
Many teams start by building a dashboard or a report to meet a specific request. However, if every solution is treated as a one-time project, it becomes difficult to maintain, reuse, or scale later. An actual data product should be reusable, support multiple use cases, and be built with long-term value in mind.
2. No Versioning, Metadata, or Governance
Without version control, it's hard to track changes or manage updates. Missing metadata makes it challenging to understand the data's meaning or where it comes from. And without proper governance, there's a risk of poor data quality, duplication, or non-compliance. All of these make scaling nearly impossible.
3. Ignoring Internal Developer Experience
Data engineers, analysts, and other developers build and maintain data products. Without the right tools, documentation, or processes, they’ll spend more time fixing issues than delivering value. Poor developer experience often leads to slow development and burnout.
4. Centralized Bottlenecks and Lack of Federated Ownership
When one central team is responsible for all data products, it quickly becomes a bottleneck. Instead, encourage federated ownership and let individual teams or domains manage their own data products. This not only speeds up delivery but also ensures better context and accountability.
5. Skipping Change Management and Adoption Metrics
Building a data product is just the first step. You also need to support adoption and track its use. Skipping change management leads to low usage, confusion, or resistance. Without metrics, it’s hard to know if the product delivers value. Avoiding these pitfalls requires thoughtful planning, collaboration, and a shift in mindset from one-off data tasks to scalable, well-governed products.
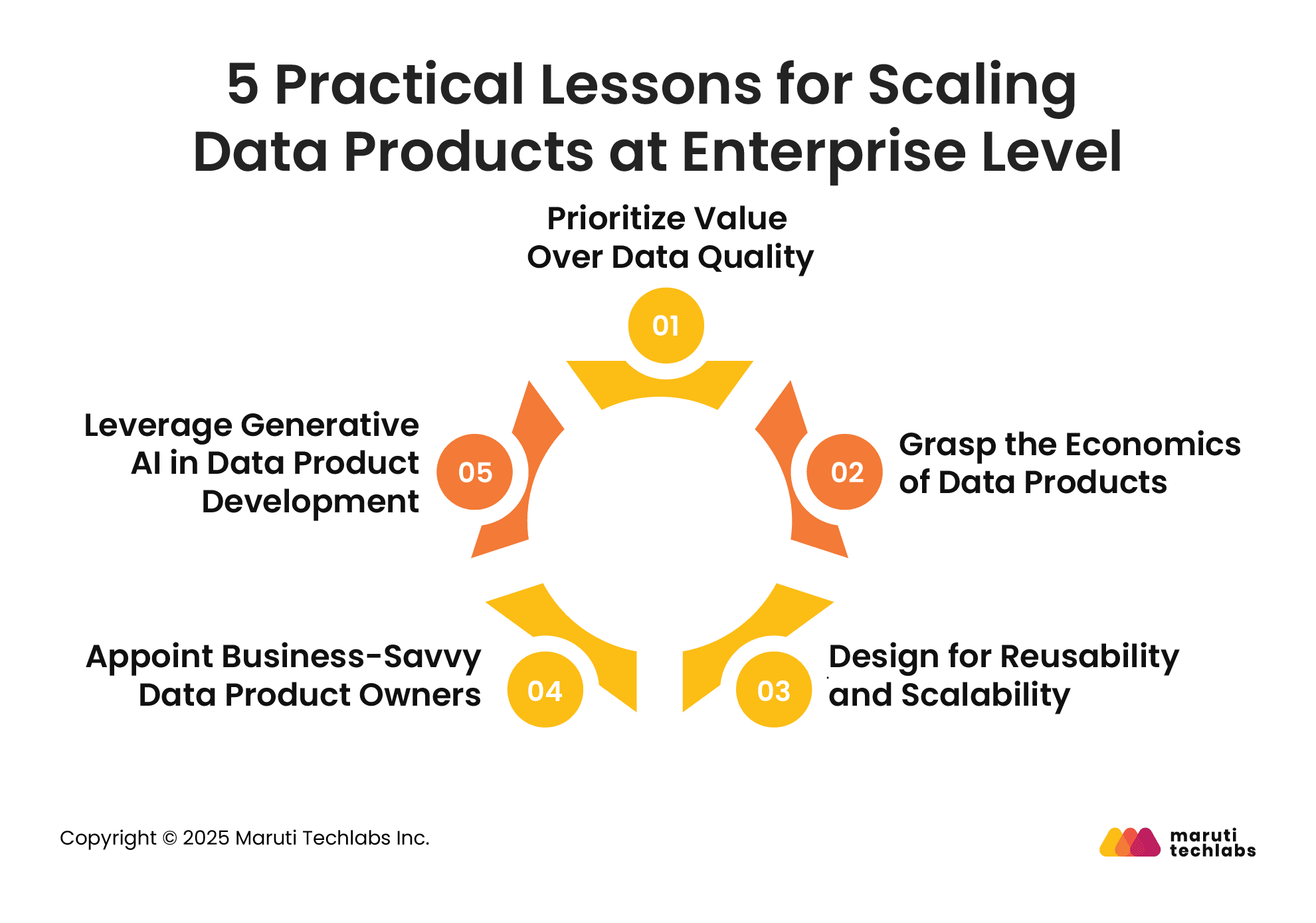
5 Practical Lessons for Scaling Data Products at Enterprise Level
Scaling data products across an enterprise takes more than good intentions; it takes a shift in mindset. Here are five practical lessons to help you build a strong foundation and ensure your data products deliver value over time.
1. Prioritize Value Over Data Quality
Many data teams try to perfect the data before doing anything with it. But the goal of a data product isn’t to make data flawless; it’s to deliver value. Before developing a data product, leadership should identify the use cases with the most impact and focus efforts there. Clear prioritization ensures teams spend time solving business problems, not chasing perfect data.
2. Grasp the Economics of Data Products
Think of data products like an investment. Each successful product should reduce the effort needed for the next one and increase the value delivered. This compounding effect, the flywheel effect, helps organizations build momentum. Focusing on products that can support multiple use cases lowers costs over time and increases returns on your data investments.
3. Design for Reusability and Scalability
Avoid starting from scratch with each new request. Instead, design data products with reusability in mind. This means building them to serve more than one use case or department. It reduces duplication of work and ensures that each product becomes more valuable over time. Scalable design helps teams respond faster to business needs without sacrificing quality.
4. Appoint Business-Savvy Data Product Owners
You need people who can run data products like a business. Data Product Owners (DPOs) should understand the data and the company. They should be able to define use cases, communicate the value clearly, and build support across teams. Strong ownership helps keep data products aligned with strategic goals and user needs.
5. Leverage Generative AI in Data Product Development
Generative AI is changing how data products are built. It can accelerate development, automate repetitive tasks, and even suggest improvements. Some organizations are seeing up to 3x faster delivery using Gen AI. Integrating it into your development process can boost both speed and cost-efficiency.
These lessons help move beyond isolated data efforts toward a sustainable, enterprise-wide approach to data product development.
Conclusion
Successful scaling of data products requires more than the right tools and platforms; it requires a thoughtful approach to ownership, governance, developer experience, and user adoption. Many organizations fall short not because they lack data but because they overlook the foundational work that ensures data products can evolve, scale, and deliver lasting value.
It might be time to reassess whether your current approach focuses only on delivering dashboards or quick fixes. Building scalable data products means investing in reusable systems, reliable data sources, and strong internal capabilities, especially in data engineering.
At Maruti Techlabs, our Data Engineering services focus on building the core infrastructure that powers high-performing data products. We help teams create scalable architectures, establish clean data domains, and automate data flows through robust DataOps practices. From versioning and metadata management to creating reusable pipelines, our team ensures that your data products are not just usable but built to last.
Contact us if you're looking to build data products that unlock long-term value and scale across your enterprise.
Pinakin Ariwala has over 20 years of experience in AI/ML, data engineering, and software development. He has led AI and machine learning projects across industries, including agriculture, finance, and healthcare, and has been featured on the Clutch Leaders Matrix podcast discussing real-world AI/ML applications.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!