When it comes to identifying and analyzing the images, humans recognize and distinguish different features of objects. It is because human brains are trained unconsciously to differentiate between objects and images effortlessly.
In contrast, the computer visualizes the images as an array of numbers and analyzes the patterns in the digital image, video graphics, or distinguishes the critical features of images. Thanks to AI software solutions such as deep learning approaches, the rise of smartphones and cheaper cameras has opened a new era of image recognition.
Different industry sectors such as gaming, automotive, and e-commerce are adopting the high use of image recognition daily. The image recognition market is assumed to rise globally to a market size of $42.2 billion by 2022.

While choosing an image recognition solution, its accuracy plays an important role. However, continuous learning, flexibility, and speed are also considered essential criteria depending on the applications.
What is Image Recognition?
Image recognition is a technology that enables us to identify objects, people, entities, and several other variables in images. In today’s era, users are sharing a massive amount of data through apps, social networks, and using websites. Moreover, the rise of smartphones equipped with high-resolution cameras generates many digital images and videos. Hence, the industries use a vast volume of digital data to deliver better and more innovative services.
Image recognition is a sub-category of computer vision technology and a process that helps to identify the object or attribute in digital images or video. However, computer vision is a broader team including different methods of gathering, processing, and analyzing data from the real world. As the data is high-dimensional, it creates numerical and symbolic information in the form of decisions. Apart from image recognition, computer vision also consists of object recognition, image reconstruction, event detection, and video tracking.
Categories of Image Recognition Tasks
Depending on the type of information required, you can perform image recognition at various levels of accuracy. An algorithm or model can identify the specific element, just as it can simply assign an image to a large category.
So, you can categorize the image recognition tasks into the following parts:
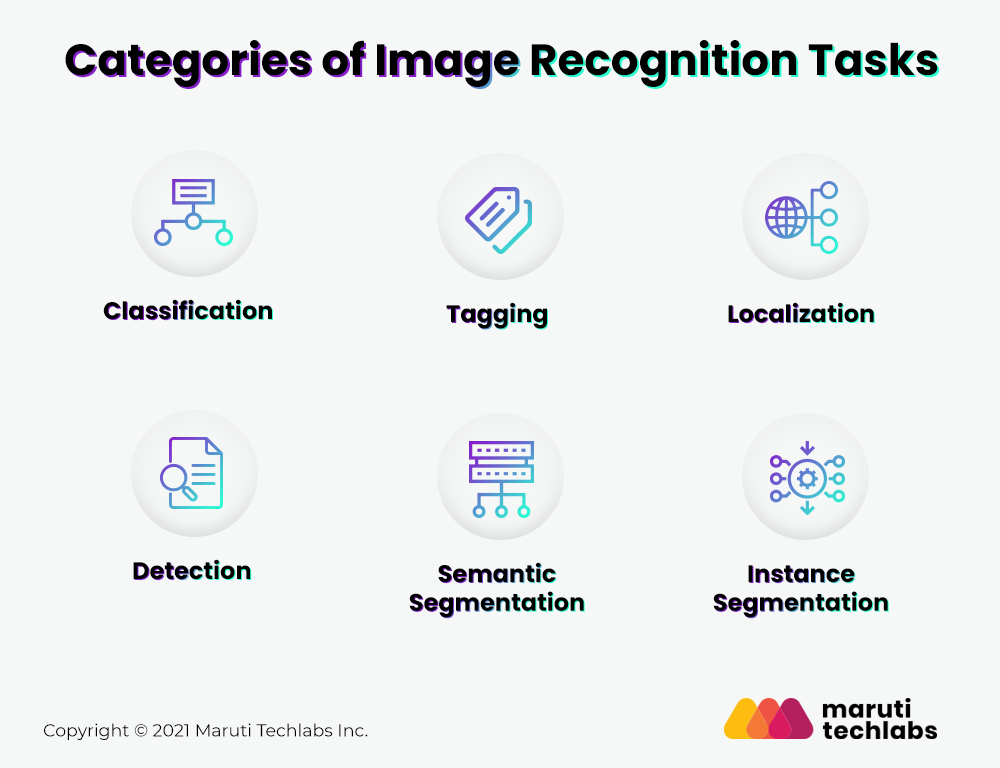
- Classification: It identifies the “class,” i.e., the category to which the image belongs. Note that an image can have only one class.
- Tagging: It is a classification task with a higher degree of precision. It helps to identify several objects within an image. You can assign more than one tag to a particular image.
- Localization: It helps in placing the image in the given class and creates a bounding box around the object to show its location in the image.
- Detection: It helps to categorize the multiple objects in the image and create a bounding box around it to locate each of them. It is a variation of the classification with localization tasks for numerous objects.
- Semantic Segmentation: Segmentation helps to locate an element on an image to the nearest pixel. In some cases, it is necessary to be extremely precise in the results, such as the development of autonomous cars.
- Instance Segmentation: It helps in differentiating multiple objects belonging to the same class.

How does Image Recognition Work?
As mentioned above, a digital image represents a matrix of numbers. This number represents the data associated with the image pixels. The different intensity of the pixels forms an average of a single value and represents itself in matrix format.
The data fed to the recognition system is basically the location and intensity of various pixels in the image. You can train the system to map out the patterns and relations between different images using this information.
After finishing the training process, you can analyze the system performance on test data. Intermittent weights to neural networks were updated to increase the accuracy of the systems and get precise results for recognizing the image. Therefore, neural networks process these numerical values using the deep learning algorithm and compare them with specific parameters to get the desired output.
Scale-invariant Feature Transform(SIFT), Speeded Up Robust Features(SURF), and PCA(Principal Component Analysis) are some of the commonly used algorithms in the image recognition process. The below image displays the Roadmap of image recognition in detail.
Neural Network Structure
There are numerous types of neural networks in existence, and each of them is pretty useful for image recognition. However, convolution neural networks(CNN) demonstrate the best output with deep learning image recognition using the unique work principle. Several variants of CNN architecture exist; therefore, let us consider a traditional variant for understanding what is happening under the hood.
Input Layer
Most of the CNN architecture starts with an input layer and servers as an entrance to the neural network. However, it considers the numerical data into a machine learning algorithm depending on the input type. They can have different representations: for instance, an RGB image will represent a cube matrix, and the monochrome image will represent a square array.
Hidden Layer
Hidden CNN layers consist of a convolution layer, normalization, activation function, and pooling layer. Let us understand what happens in these layers:
1. Convolution Layer
The working of CNN architecture is entirely different from traditional architecture with a connected layer where each value works as an input to each neuron of the layer. Instead of these, CNN uses filters or kernels for generating feature maps. Depending on the input image, it is a 2D or 3D matrix whose elements are trainable weights.
2. Batch Normalization
It is a specific math function with two parameters: expectation and variance. Its role is to normalize the values and equalize them in a particular range convenient for activation function. Remember that the normalization is carried out before the activation function.
The primary purpose of normalization is to deduce the training time and increase the system performance. It provides the ability to configure each layer separately with minimum dependency on each other.
3. Activation Function
The activation function is a kind of barrier which doesn’t pass any particular values. Many mathematical functions use computer vision with neural networks algorithms for this purpose. However, the alternative image recognition task is Rectified Linear Unit Activation function(ReLU). It helps to check each array element and if the value is negative, substitutes with zero(0).
4. Pooling Layer
The pooling layer helps to decrease the size of the input layer by selecting the average value in the area defined by the kernel. The pooling layer is a vital stage. If it is not present, the input and output will lead in the same dimension, which eventually increases the number of adjustable parameters, requires much more computer processing, and decreases the algorithm’s efficiency.
Output Layer
The output layer consists of some neurons, and each of them represents the class of algorithms. Output values are corrected with a softmax function so that their sum begins to equal 1. The most significant value will become the network’s answer to which the class input image belongs.
Challenges of Image Recognition
Here are some common challenges faced by image recognition models:
1. Viewpoint Variation
In real-life cases, the objects within the image are aligned in different directions. When such images are given as input to the image recognition system, it predicts inaccurate values. Therefore, the system fails to understand the image’s alignment changes, creating the biggest image recognition challenge.
2. Scale Variation
Size variation majorly affects the classification of the objects in the image. The image looks bigger as you come closer to it and vice-versa. It changes the dimension of the image and presents inaccurate results.
3. Deformation
As you know, objects do not change even if they are deformed. The system learns from the image and analyzes that a particular object can only be in a specific shape. We know that in the real world, the shape of the object and image change, which results in inaccuracy in the result presented by the system.
4. Inter-class Variation
Particular objects differ within the class. They can be of different sizes, shapes but still represent the same class. For instance, chairs, bottles, buttons all come in other appearances.
5. Occlusion
Sometimes, the object blocks the full view of the image and eventually results in incomplete information being fed to the system. It is nceessary to develop an algorithm sensitive to these variations and consists of a wide range of sample data.

The training should have varieties connected to a single class and multiple classes to train the neural network models. The varieties available will ensure that the model predicts accurate results when tested on sample data. It is tedious to confirm whether the sample data required is enough to draw out the results, as most of the samples are in random order.
Limitations of Neural Networks for Image Recognition
Neural networks follow some common yet challenging limitations while undergoing an image recognition process. Some of those are:
- Due to limited hardware availability, massive data makes it difficult to process and analyze the results.
- Since the vague nature of the model prohibits the application in several areas, it is difficult to interpret the model.
- As the development requires a considerable amount of time, the flexibility of the model is compromised. However, the development can be more straightforward using frameworks and libraries like Keras.
Role of Convolution Neural Networks in Image Recognition
Convolution Neural Network (CNN) is an essential factor in solving the challenges that we discussed above. CNN consists of the changes in the operations. The inputs of CNN are not the absolute numerical values of the image pixels. Instead, the complete image is divided into small sets where each set acts as a new image. Therefore, the small size of the filter separates the entire image into smaller sections. Each set of neurons is connected to this small section of the image.
Now, these images are considered similar to the regular neural network process. The computer collects the patterns and relations concerning the image and saves the results in matrix format.
The process keeps repeating until the complete image is given to the system. The output is a large matrix representing different patterns that the system has captured from the input image. The matrix is reduced in size using matrix pooling and extracts the maximum values from each sub-matrix of a smaller size.
During the training phase, different levels of features are analyzed and classified into low level, mid-level, and high level. The low level consists of color, lines, and contrast. Mid-level consists of edges and corners, whereas the high level consists of class and specific forms or sections.
Hence, CNN helps to reduce the computation power requirement and allows the treatment of large-size images. It is susceptible to variations of image and provides results with higher precision compared to traditional neural networks.
What are the Use Cases of Image Recognition?
Deep learning image recognition is a broadly used technology that significantly impacts various business areas and our lives in the real world. As the application of image recognition is a never-ending list, let us discuss some of the most compelling use cases on various business domains.
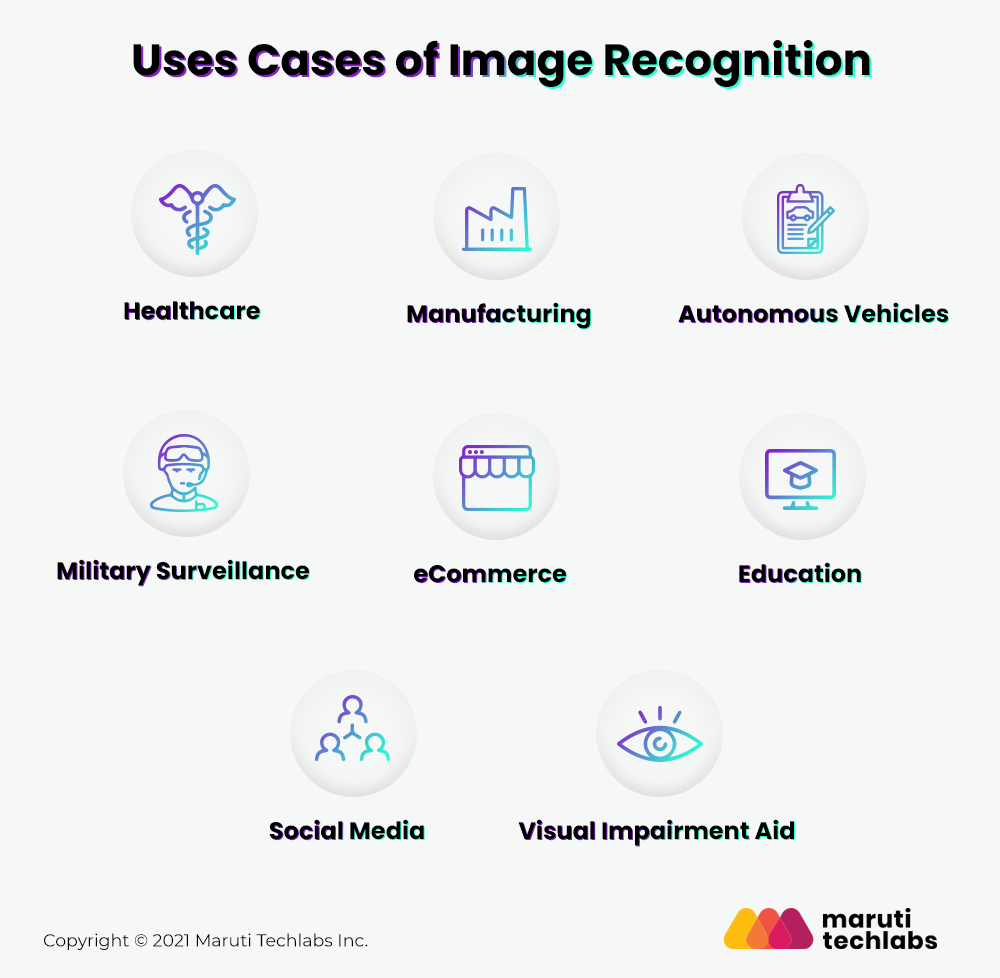
1. Healthcare
Despite years of practice and experience, doctors tend to make mistakes like any other human being, especially in the case of a large number of patients. Therefore, many healthcare facilities have already implemented an image recognition system to enable experts with AI assistance in numerous medical disciplines.
MRI, CT, and X-ray are famous use cases in which a deep learning algorithm helps analyze the patient’s radiology results. The neural network model allows doctors to find deviations and accurate diagnoses to increase the overall efficiency of the result processing.
2. Manufacturing
Analyzing the production lines includes evaluating the critical points daily within the premises. Image recognition is highly used to identify the quality of the final product to decrease the defects. Assessing the condition of workers will help manufacturing industries to have control of various activities in the system.
3. Autonomous Vehicles
Image recognition helps autonomous vehicles analyze the activities on the road and take necessary actions. Mini robots with image recognition can help logistic industries identify and transfer objects from one place to another. It enables you to maintain the database of the product movement history and prevent it from being stolen.
Modern vehicles include numerous driver-assistance systems that enable you to avoid car accidents and prevent loss of control that helps drive safely. Ml algorithms allow the car to recognize the real-time environment, road signs, and other objects on the road. In the future, self-driven vehicles are predicted to be the advanced version of this technology.
4. Military Surveillance
Image recognition helps identify the unusual activities at the border areas and take automated decisions that can prevent infiltration and save the precious lives of soldiers.
5. eCommerce
eCommerce is one of the fast-developing industries in today’s era. One of the eCommerce trends in 2021 is a visual search based on deep learning algorithms. Nowadays, customers want to take trendy photos and check where they can purchase them, for instance, Google Lens.
Ecommerce makes use of image recognition technology to recognize the brands and logos on the image in social media, where companies can accurately identify the target audience and understand their personality, habits, and preferences efficiently.
6. Education
Different aspects of education industries are improved using deep learning solutions. Currently, online education is common, and in these scenarios, it isn’t easy to track the reaction of students using their webcams. The neural networks model helps analyze student engagement in the process, their facial expressions, and body language.
Image recognition also enables automated proctoring during examinations, digitization of teaching materials, attendance monitoring, handwriting recognition, and campus security.
7. Social Media
Social media platforms have to work with thousands of images and videos daily. Image recognition enables a significant classification of photo collection by image cataloging, also automating the content moderation to avoid publishing the prohibited content of the social networks.
Moreover, monitoring social media text posts that mention their brands lets one learn how consumers perceive and interact with their brand and what they say about it.
8. Visual Impairment Aid
Visual impairment, also known as vision impairment, is decreased ability to see to the degree that causes problems not fixable by usual means. In the early days, social media was predominantly text-based, but now the technology has started to adapt to impaired vision.
Image recognition helps to design and navigate social media for giving unique experiences to visually impaired humans. Aipoly is one such app used to detect and identify objects. The user should point their phone’s camera at what they want to analyze, and the app will tell them what they are seeing. Therefore, the app functions using deep learning algorithms to identify the specific object.
Factors to be Considered while Choosing Image Recognition Solution
The most crucial factor for any image recognition solution is its precision in results, i.e., how well it can identify the images. Aspects like speed and flexibility come in later for most of the applications.
The company can compare the different solutions after labeling data as a test data set. In most cases, solutions are trained using the companies’ data superior to pre-trained solutions. If the required level of precision can be compared with the pre-trained solutions, the company may avoid the cost of building a custom model.
Users should avoid generalizations based on a single test. A vendor who performs well for face recognition may not be good at vehicle identification because the effectiveness of an image recognition algorithm depends on the given application.
Other such criteria include:
- Continuous learning: Every AI vendor boasts of continuous learning, but few achieve it. The solution will be learning from its incorrect predictions.
- Speed: The solution should be fast and efficient for the necessary application. While a customer-facing problem may require a response within milliseconds, a solution for internal use should be produced within a few days.
- Adaptability for the future needs: The adaptability of the solution for the future is essential. It is a wise choice to foresee the constraints of the future in advance.
- The simplicity of setup and integration: The solution should be pretty easy to set up and use. As most solutions will be API endpoints, they tend to be easy to set up.
Image Recognition Solution Providers
As you already know, many tech giants like Google, IBM, AWS offer ready-made solutions for image recognition and machine learning. Suppose your task is enormous, such as scanning, recognizing handwritten text, translating or identifying animals, plants, or animals; in that case, you can use such ready-made neural algorithms these companies provide. Tech giants offer APIs that enable you to integrate your image recognition software.
There are various advantages for the same:
- Saving time and money for building and training new neural networks model
- High accuracy of already existing models
- Access to remarkable computer powers like tensor processors and efficient work of complex neural networks
Along with these ready-made products, there are many software environments, libraries, and frameworks that help you to build and deploy machine learning and deep learning algorithms efficiently. There are also industry-specific vendors. For instance, Visenze provides solutions for product tagging, visual search, and recommendation. Other than visenze, some of the well-known are:
How did Maruti Techlabs Use Image Recognition?
We, at Maruti Techlabs, have developed and deployed a series of computer vision models for our clients, targeting a myriad of use cases. One such implementation was for our client in the automotive eCommerce space. They offer a platform for the buying and selling of used cars, where car sellers need to upload their car images and details to get listed.
The Challenge:
Users upload close to ~120,000 images/month on the client’s platform to sell off their cars. Some of these uploaded images would contain racy/adult content instead of relevant vehicle images.
Manual approval of these massive volumes of images daily involved a team of 15 human agents and a lot of time. Such excessive levels of manual processing gave way to serious time sinks and errors in approved images. This led to poor customer experience and tarnished brand image.
The Solution:
As a solution, we built an image recognition model using Google Vision to eliminate irrelevant images from the platform. The model worked in two steps:
Step 1 – Detect car images and flag the rest
- After training the model, it would classify the images into two categories – car and non-car.
- The model would identify the images of cars/vehicles, flag the rest and notify the team via Slack notifications.
- Once the image of the car was identified, the image recognition model also performed obstacle detection to detect if any other unidentified object was blocking the car’s appearance.
- The model further performed image tagging and classified images into those of cars and blocked vehicle numbers.
Step 2 – Verify car models against the details provided
- After identifying the car images, we went a step further and trained the model to verify if the car model and make in the picture, matched the car model and make mentioned by the user in the form.
- For this, we included the car make and model recognition dataset to train the image recognition model.
- The model would verify the car model in the image against that mentioned in the form based on the training. If the model did not find both to be a match, it would be flagged, and the team would be notified of the same via a Slack notification.
The Computer Vision model automated two steps of the verification process. We used ~1500 images for training the model. With training datasets, the model could classify pictures with an accuracy of 85% at the time of deploying in production.
Investing in CV with an in-house team from scratch is no easy feat. This is where our computer vision services can help you in defining a roadmap for incorporating image recognition and related computer vision technologies. Mostly managed in the cloud, we can integrate image recognition with your existing app or use it to build a specific feature for your business. To get more out of your visual data, connect with our team here.
About the author
Pinakin Ariwala
Vice President Data Science & Technology
Pinakin Ariwala has over 20 years of experience in AI/ML, data engineering, and software development. He has led AI and machine learning projects across industries, including agriculture, finance, and healthcare, and has been featured on the Clutch Leaders Matrix podcast discussing real-world AI/ML applications.







