Private LLMs vs Open-Source Models: How to Choose the Right One?
Learn how to choose the right LLM for your business to ensure secure, scalable, high-impact AI.
Artificial Intelligence and Machine Learning
Private LLMs vs Open-Source Models: How to Choose the Right One?
Learn how to choose the right LLM for your business to ensure secure, scalable, high-impact AI.
Table of contents
Table of contents
Key Takeaways
Introduction
Private vs Open Models: What Sets Them Apart and Why It Matters?
When to Use Open-Source LLMs: Use Cases & Risks
Risks of Using Open-Source LLMs
When to Use Private LLMs: Use Cases & Risks
Risks of Using Private LLMs
Building a Hybrid LLM in 6 Steps
Conclusion
FAQs
Key Takeaways
Choosing the right LLM directly impacts ROI, scalability, data control, and business efficiency.
Private LLMs ensure stronger security, compliance, and performance for sensitive enterprise workloads.
Open-source LLMs offer flexibility, transparency, and cost-effective customization for diverse use cases.
Hybrid LLM strategies balance control and scalability by combining private and open-source strengths.
Governance, monitoring, and architecture design are essential to building reliable, future-ready LLM systems.
Introduction
The rapid rise of generative AI is reshaping how businesses innovate. A recent Bain & Company analysis of enterprise AI adoption trends highlights how difficult these decisions have become for large organizations. In its study, Bain found that companies using AI effectively outperform peers by wide margins. This context sets the stage for understanding why model selection matters.
But simply adopting LLMs isn’t enough. The choice of deployment model strongly affects ROI, the level of control you have over your data, and your ability to scale efficiently.
A key decision for enterprises today is whether to build a private LLM in a controlled environment or leverage an open-source model, each with trade-offs in cost, flexibility, and security.
This blog provides a clear, practical comparison to help you select the right approach for your organization.
Private vs Open Models: What Sets Them Apart and Why It Matters?
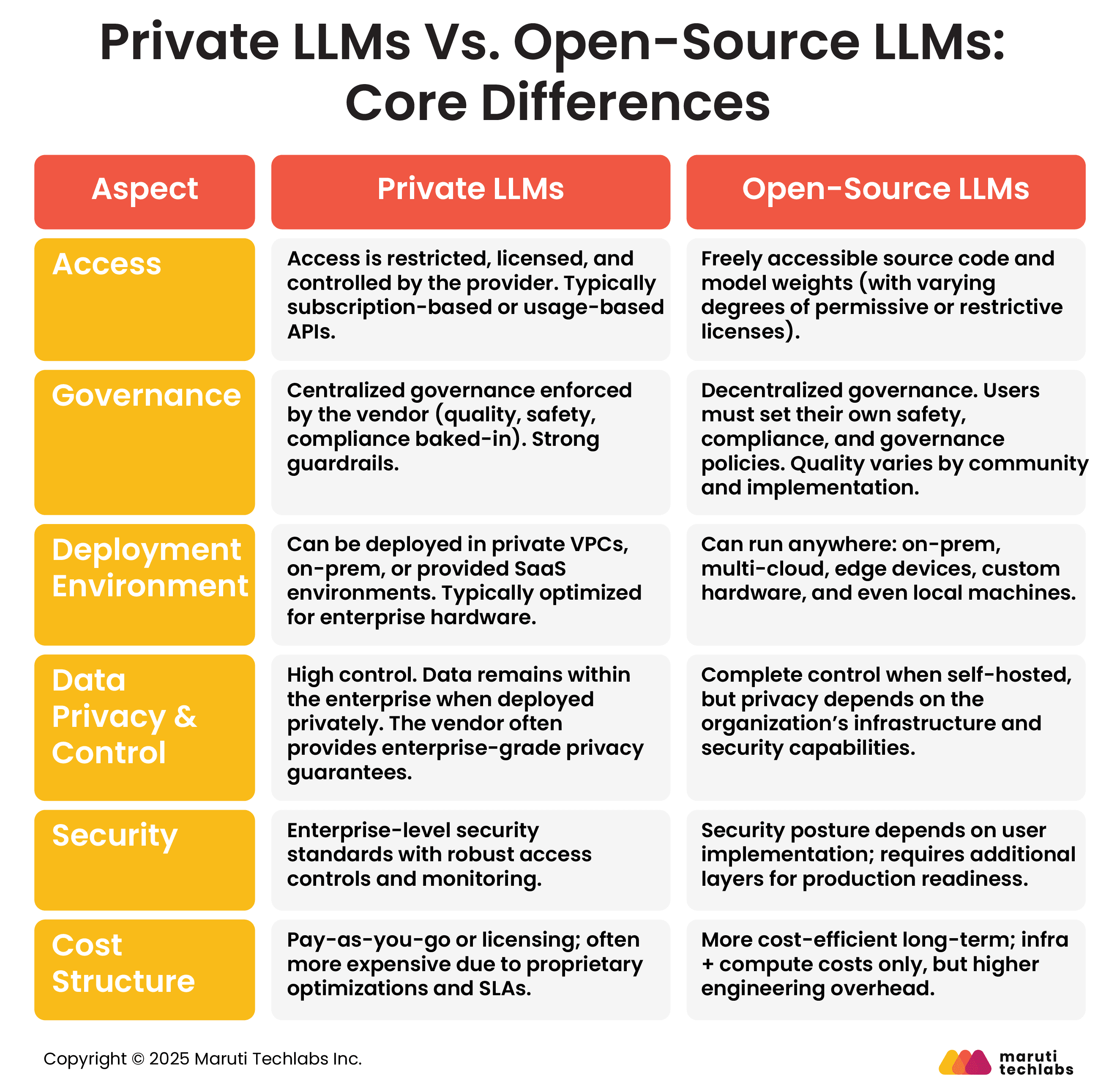
What is a Private LLM?
A Private LLM, also known as a proprietary large language model, is powered by artificial intelligence and is deployed by a company within its infrastructure using servers or a private cloud.
Unlike public LLMs like Gemini, ChatGPT, or Claude, private LLMs are trained on specific business data. In addition, they don’t share a user’s data with external services.
What is an Open-Source LLM?
Open-source LLMs are free and available to everyone. They can be modified, used for any purpose, and distributed.
The term ‘open-source’ concerns the LLM’s code and architecture. They’re accessible to the public. So, researchers and developers can modify and use the model as they wish.
Comparing Private LLMs with Open-Source LLMs
When to Use Open-Source LLMs: Use Cases & Risks
Organizations can leverage open-source LLMs for any project that can be helpful for their employees. Its most prevalent use cases include:
1. Text Generation
Open-source LLMs enable the development of apps with language-generation capabilities, such as writing blogs, stories, or emails.
2. Code Development
Developers can create applications, enhance security, and discover errors using open-source LLMs trained on existing code and programming languages.
3. Virtual Learning
With open-source tools, learning can be personalized to match different styles.
4. Content Summarization
Open-source LLMs are adept at extracting summaries from long articles, reports, and complex datasets, offering key insights at your fingertips.
5. AI-Powered Chatbot
AI-based chatbots can engage in natural, human-like conversations, understand and answer questions, and offer recommendations.
6. Translations
Open-source LLMs can provide accurate translations across multiple languages when trained on multilingual datasets.
7. Sentiment Analysis
Sentiment analysis is crucial for maintaining brand reputation and analyzing customer feedback. LLMs can understand the underlying tone to determine emotions or sentiments.
8. Content Filtration
LLMs are best at discovering harmful content online, which helps maintain a safe online environment.
Risks of Using Open-Source LLMs
Even when LLM outputs look accurate and reliable, they can still produce “hallucinations” or incorrect information. They can also be affected by bias, security vulnerabilities, and issues around data consent.
Here are the risks associated with using open-source LLMs.
Hallucinations result from models trained on inaccurate or incomplete data. It can also occur because they can predict the next word based on context, without understanding the meaning.
Bias occurs when the training data lacks diversity or fails to represent the full range of real-world scenarios.
Some open-source models are trained on large scraped datasets that may not include explicit user consent, creating uncertainty about data provenance and legal compliance.
Attackers can misuse open-source LLMs by fine-tuning them for harmful purposes such as phishing, automated fraud, social engineering, or generating deceptive content at scale.
Security issues also include leaking Personally Identifiable Information (PII).
When to Use Private LLMs: Use Cases & Risks
Private LLMs are best suited for workflows where data sensitivity, compliance, and brand consistency matter. Here are a few ideal use cases for using private LLMs.
1. Intelligent Document Processing
Private LLMs make it easy to turn complex documents into structured knowledge. Teams can quickly search records, contracts, or compliance forms and get accurate answers. Everything stays secure inside the organization.
2. Customer Support
Private LLMs can power chatbots that handle sensitive questions. All data stays in-house to meet GDPR or HIPAA requirements. Customers get quick, personalized answers while staff focus on bigger issues.
3. Internal Knowledge Assistants
Data from CRMs, wikis, and project tools is unified into a single, accessible interface. Employees can ask questions naturally and get verified, context-aware answers. This saves time and preserves institutional knowledge.
4. Code Generation & Software Development
Internal codebases are used to generate function stubs, tests, or service layers. Development cycles are faster, code quality is higher, and proprietary logic stays protected inside the company.
5. Finance & Audit Automation
Private LLMs read financial records, spot anomalies, and create audit summaries quickly. All sensitive data stays inside the company’s secure environment. Teams finish audits faster with more confidence in the results.
Risks of Using Private LLMs
Before implementing private LLMs, it’s important to understand the potential risks and challenges that come with managing them.
Even with internal data, you need solid AI governance to make sure sensitive information is used responsibly and stays safe.
If the company’s own training data is skewed or unbalanced, the model may learn and amplify these biases.
Regulatory compliance (e.g., for GDPR or CCPA) still requires ongoing effort, even when data doesn’t leave the company environment.
Continuous monitoring, evaluation, and fine-tuning are needed to prevent ethical issues and hallucinations.
Building a Hybrid LLM in 6 Steps
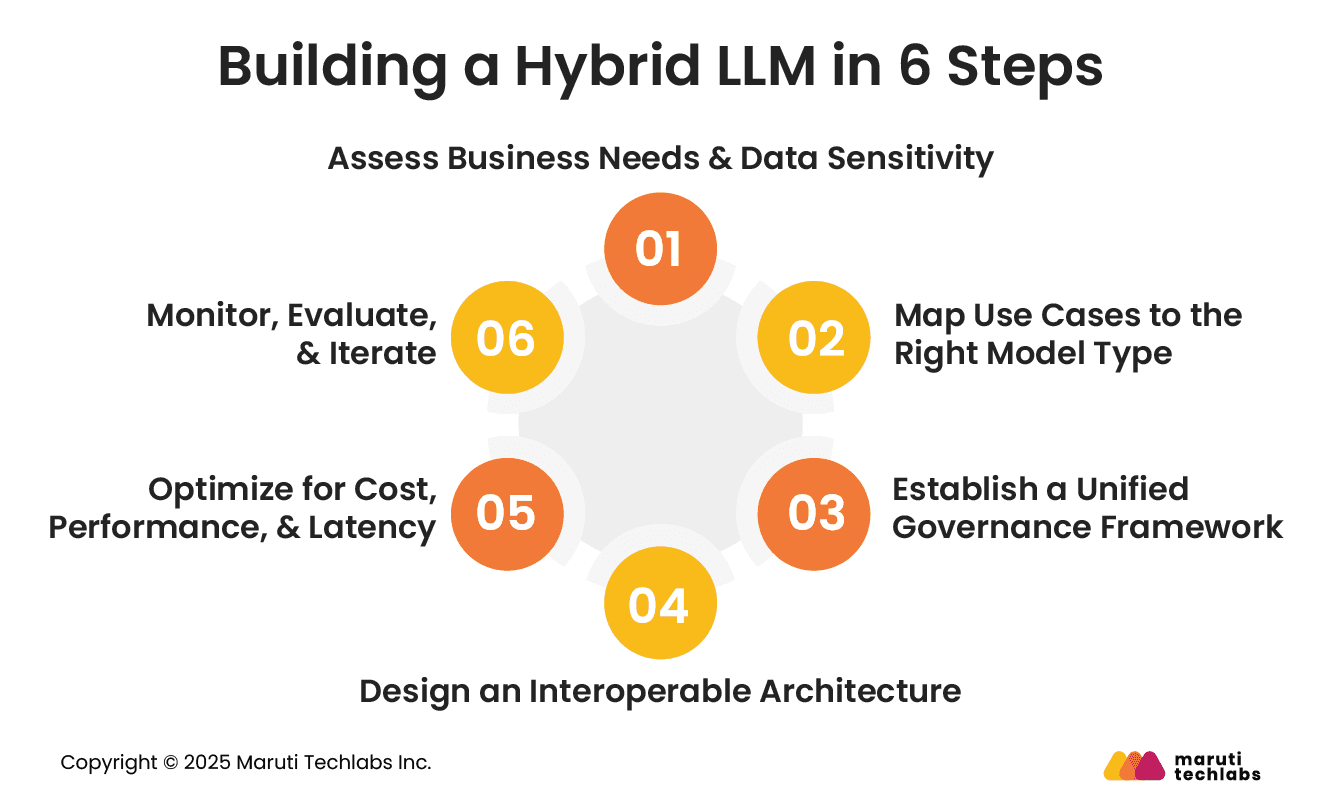
Here are six easy steps that can help you create your own hybrid LLM.
1. Assess Business Needs & Data Sensitivity
Begin by identifying which workflows require high accuracy, strict data privacy, or custom domain knowledge. Classify data sensitivity to determine which tasks should rely on private LLMs versus public/open-source models.
2. Map Use Cases to the Right Model Type
Use private LLMs for workloads involving confidential data, regulated environments, or proprietary knowledge.
Use public or open-source LLMs for creative tasks, broad knowledge queries, and scalability-heavy applications.
3. Establish a Unified Governance Framework
Create centralized governance covering data access, security, versioning, auditing, and compliance.
Ensure both public and private model pathways follow the same safety, monitoring, and responsible AI standards.
4. Design an Interoperable Architecture
Build a modular architecture that uses APIs, embeddings, vector databases, and orchestration layers to enable seamless switching between private and public models.
Ensure shared components, such as prompt templates and evaluation pipelines, work across both.
5. Optimize for Cost, Performance & Latency
Use private LLMs for low-latency, high-control tasks and offload large-scale or non-sensitive processing to public LLMs to reduce cost.
Continuously benchmark performance across both environments.
6. Monitor, Evaluate & Iterate
Implement continuous monitoring for drift, accuracy, hallucinations, and security gaps.
Update models, retrain on new data, and refine prompts to keep the hybrid ecosystem adaptive and reliable.
Conclusion
Choosing between private LLMs and open-source models ultimately comes down to balancing control, customization, security, and cost.
Private LLMs offer stronger governance, enterprise-grade compliance, and safer handling of sensitive data. On the contrary, open-source models provide unmatched flexibility, transparency, and the ability to tailor them deeply to your domain.
The right choice depends on your business needs, risk tolerance, and your organization's readiness to operationalize AI responsibly and at scale.
If you’re unsure which Generative AI approach suits your organization, Maruti Techlabs can help you evaluate, design, and implement the right AI ecosystem with our end-to-end Generative AI Development Services.
Ready to make the right AI decision? Connect with us today to start your transformation journey.
FAQs
1. What are the advantages of using a private LLM for business?
Private LLMs give enterprises control over data locality and security, since the model runs within their own infrastructure.
They offer tailored accuracy by training on company-specific datasets and provide predictable performance without third-party API latency.
2. Should LLMs be open source?
Open-source LLMs provide transparency, flexibility, and community collaboration.They allow organizations to inspect model internals, tune behavior, and avoid vendor lock-in.
But both open-source and proprietary LLMs carry risks, including bias, security issues, and inaccuracies.
3. Can open-source LLMs be fine-tuned like private LLMs?
Yes, open-source LLMs allow anyone to download weights, modify architecture, and fine-tune models for domain-specific tasks.
This flexibility is one of their biggest strengths compared to restrictive proprietary systems.
4. What is the difference between open-source and private LLMs?
Open-source LLMs provide publicly accessible code and model weights for customization.
Private LLMs, by contrast, run within an enterprise’s own infrastructure, using proprietary or internal data for training and inference.
5. How much does it cost to use private LLMs vs open-source models?
Private LLMs often reduce ongoing vendor-licensing costs and avoid API charges, especially for high-volume or low-latency use.
Open-source LLMs eliminate license fees but involve infrastructure costs (compute, storage) and require investment in deployment.
Pinakin Ariwala has over 20 years of experience in AI/ML, data engineering, and software development. He has led AI and machine learning projects across industries, including agriculture, finance, and healthcare, and has been featured on the Clutch Leaders Matrix podcast discussing real-world AI/ML applications.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!