Why Multimodal AI is Better than Single-Modal AI Models?
Explore how to boost business insights and decisions with Multimodal AI over single-modal systems.
Artificial Intelligence and Machine Learning
Why Multimodal AI is Better than Single-Modal AI Models?
Explore how to boost business insights and decisions with Multimodal AI over single-modal systems.
Table of contents
Table of contents
Introduction
What is Singlemodal AI?
What is Multimodal AI?
Top 4 Benefits of Multimodal AI Models
Difference Between Multimodal AI and Single-Modal AI
Where Does Multimodal AI Outperform Single-Modal AI?
Top 8 Widely Used Multimodal AI Models
5 Major Concerns with Multimodal AI
Conclusion
FAQs
Introduction
The importance of versatility in AI systems cannot be overstated. Traditional single-modal AI systems typically process one type of data, such as text, images, or audio, which limits their ability to comprehend complex, real-world scenarios.
Multimodal AI addresses these limitations by integrating multiple data types, enabling a more comprehensive understanding.
For instance, combining text, images, and audio enables AI systems to interpret context more accurately, leading to more nuanced interactions and informed decisions.
This blog explores the evolution of multimodal AI, highlighting key differences and applications. This article provides a comprehensive overview of how multimodal AI surpasses single-modal AI and is effectively shaping the future of artificial intelligence.
What is Singlemodal AI?
Single-modal concerns the data source used to develop the AI algorithm. So in this case, a single source is leveraged to create AI’s algorithm.
Although single-modal AI is limited due to a unified source, it was considered the standard until the advent of multimodal machine learning.
What is Multimodal AI?
Multimodal AI is a machine learning model that can process and integrate data from multiple sources or modalities. The different data types include audio, images, video, text, and other sensory inputs.
Traditional AI models are designed to handle a single type of data. Unlike them, multimodal AI can process and analyze different data inputs to gain a comprehensive understanding and share more robust outputs.
For instance, multimodal AI is capable of generating a summary of a landscape photo when given as input. Or it could understand the written description of a landscape and develop a relevant image.
Top 4 Benefits of Multimodal AI Models
Multimodal AI models can process and understand multiple types of data simultaneously, unlocking capabilities that single-modal AI cannot. Let’s understand the benefits a multimodal AI model offers over a single-modal AI.
1. Contextual Understanding
Multimodal AI systems are adept at understanding phrases and words used with Natural Language Processing (NLP). It does this by browsing through related keywords and concepts.
This enables the model to grasp the context and provide an appropriate response. Upon integration with multimodal AI models, NLP models can leverage visual and linguistic data to understand the context.
2. Enhanced Accuracy
Advanced multimodal models mix text, videos, and images to enhance accuracy. They are proficient in examining input data, increasing prediction accuracy across tasks.
They employ various modalities to enhance picture captioning. Multimodal AI can better grasp speaker emotions by merging speech and facial features, aiding NLP’s capabilities.
3. Ideal Interactions
The limitations (text and speech) of AI models acted as a barrier to facilitating a natural user experience. In contrast, multimodal AI better understands user intent using text, visual, and voice cues.
It offers text and audio recognition features to learn the meaning of commands when integrated with virtual assistants.
4. Added Capabilities
Image, text, and audio recognition capabilities make multimodal AI a unique technology. They add to the effectiveness and accuracy of task accomplishment.
Multimodal LLMs, capable of understanding faces and audio, can efficiently identify people.
Assessing audio and visual signals, the model can distinguish between things and people with similar voices and appearances.
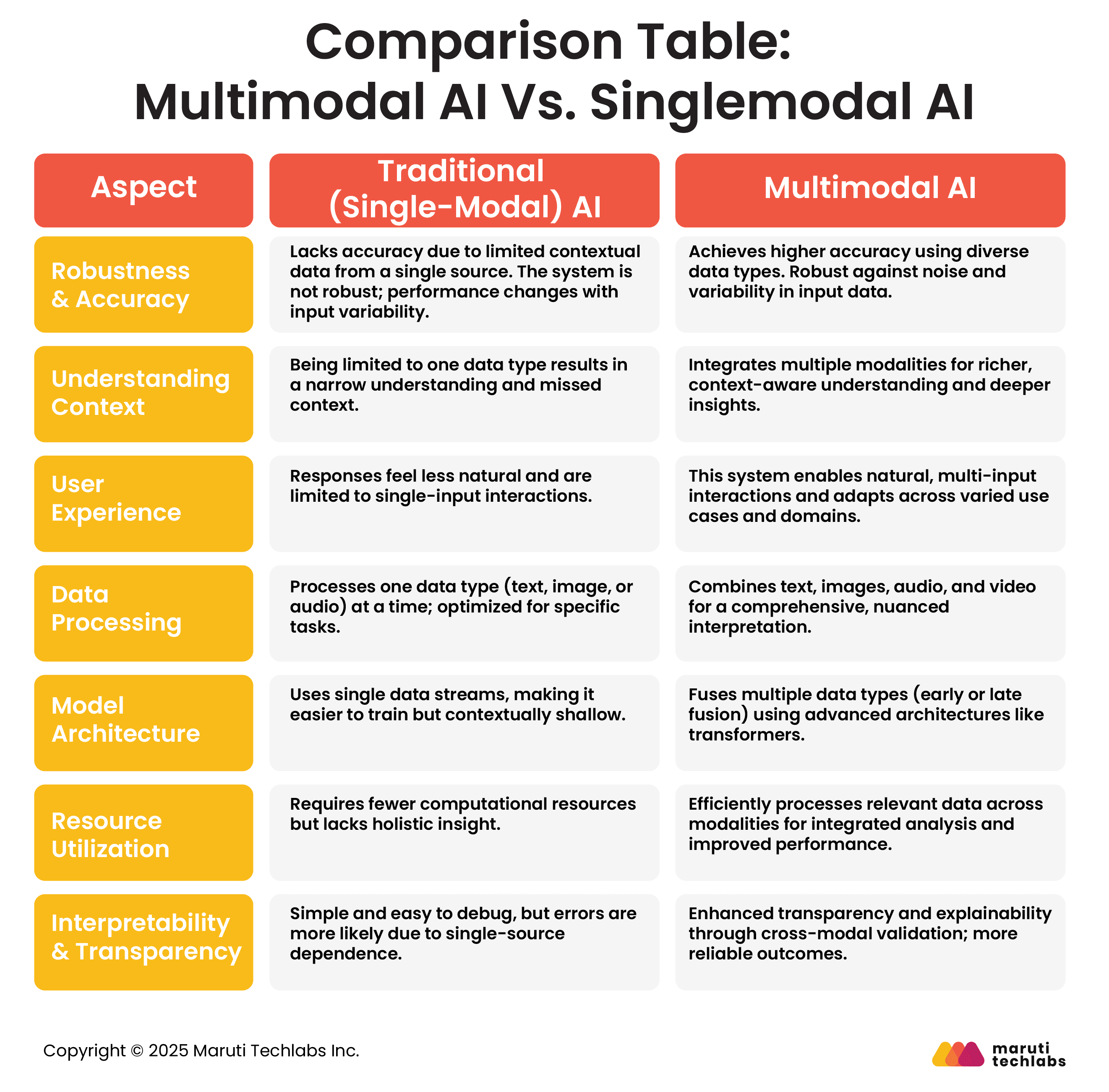
Difference Between Multimodal AI and Single-Modal AI
While traditional AI focuses on one type of data at a time, multimodal AI can integrate insights from multiple data sources for a comprehensive understanding. Here’s how multimodal AI compares with traditional AI in creating accurate models.
Where Does Multimodal AI Outperform Single-Modal AI?
By combining information from different data types, multimodal AI can tackle complex problems that single-modal AI struggles with. Here are some aspects or areas where multimodal AI outperforms single-modal AI.
1. Recognizing Emotions
Multimodal AI analyzes video, text, and audio together to understand emotions more accurately. It assesses facial expressions, voice tone, and words in customer interactions to provide empathetic responses.
Single-modal AI relies on a single data type, often resulting in reduced accuracy and performance.
2. Health Diagnosis
Multimodal AI combines medical images, patient records, and genetic data to deliver precise diagnoses and personalized treatments, such as merging X-rays, MRIs, and medical history for better insights.
Traditional AI, limited to one data type, risks less accurate outcomes.
3. Chatbots/Virtual Assistants
Multimodal AI processes voice, text, and visual inputs for seamless, natural interactions, similar to Google Assistant or Alexa, utilizing voice and camera data for enhanced assistance.
Traditional AI, limited to one input type, struggles with complex or context-rich queries.
4. Autonomous Vehicles
Multimodal AI combines data from cameras, LIDAR, radar, and GPS to enhance safety and navigation by utilizing multiple sensors to detect obstacles for autonomous driving.
Traditional AI, which relies on a single data type, performs less accurately in complex conditions.
5. Education
Multimodal AI combines text, video, audio, and simulations to create personalized learning experiences, similar to online platforms that adapt lessons to each student’s style and pace.
Traditional AI, limited to a single data type, struggles to support varied learning needs effectively.
6. Surveillance & Security
Multimodal AI combines video, audio, and motion sensor data to enable more intelligent threat detection, allowing surveillance systems to identify risks and reduce false alarms accurately.
Traditional AI, limited to a single data source, often produces more errors and misses detections.
Top 8 Widely Used Multimodal AI Models
Let’s explore the top multimodal AI models used globally.
GPT-4o (OpenAI): This model understands text, images, and audio together, making conversations feel smooth and context-aware. It can describe pictures, understand tone, and respond naturally, just like talking to a person.
Claude 3 (Anthropic): Designed to handle text and images, Claude 3 excels at interpreting visual details, such as charts, graphs, and photos, with high precision, making it particularly useful for both analytical and creative tasks.
Gemini (Google): Created by Google DeepMind, Gemini can process text, images, audio, and even video. It was known for its powerful multimodal capabilities, although its image generation feature was recently paused due to ethical concerns.
DALL·E 3 (OpenAI): Specializes in turning text prompts into detailed, artistic images. It’s excellent at understanding creative instructions and producing visuals that match specific styles or concepts.
LLaVA (Large Language and Vision Assistant): An open-source model that combines vision and language, allowing people to improve or modify it freely.
PaLM-E (Google): Integrates text and images with real-time data, enabling systems to interpret what they see and respond intelligently.
ImageBind (Meta): Connects six data types, including images, text, audio, depth, thermal, and motion, to create a rich, connected understanding of the world.
CLIP (OpenAI): Links text and images, recognizing objects or scenes based on written descriptions without extra training.
5 Major Concerns with Multimodal AI
While multimodal AI offers powerful capabilities, it also introduces unique challenges that organizations need to address. Here are the most evident challenges or concerns observed with multimodal AI.
1. Privacy Issues
Multimodal AI systems handle large amounts of personal data, including images, voices, and text. Without strong protections, this access can expose sensitive information and pose serious privacy risks.
2. Data Misinterpretation
Although these systems can combine insights from different sources, they sometimes misread complex contexts, which can lead to inaccurate or even harmful decisions.
3. Biasness
Multimodal AI can inherit and spread biases from the data it learns from. Because it processes diverse information, these biases can appear in many ways, affecting fairness and equality.
4. Complexity in Management
Managing and maintaining multimodal AI is more difficult than simpler systems. Its complexity can increase operational costs and make it harder to ensure consistent results.
5. Dependence on Technology
A heavy reliance on multimodal AI may lead to a reduction in human judgment and critical thinking, as people become increasingly dependent on technology for decision-making.
Conclusion
Multimodal AI has emerged as a transformative force in artificial intelligence, offering capabilities that far surpass those of traditional single-modal systems. By integrating text, images, audio, and other data types, it provides a richer and more context-aware understanding, making interactions more intelligent and more human-like.
Unlike conventional AI, which often struggles with single data sources, multimodal AI excels in complex scenarios such as customer service, healthcare diagnostics, autonomous driving, and personalized learning, enabling more accurate solutions.
Popular models like GPT-4o, Gemini, and DALL-E 3 showcase how versatile and powerful this technology has become. At the same time, open-source and research-focused systems like LLaVA and ImageBind continue to expand their potential.
However, challenges such as privacy concerns, bias, complexity in management, and over-reliance on technology remain essential considerations.
If you’re planning to maximize the potential of AI, you can leverage Maruti Techlabs’ specialized Artificial Intelligence Services to develop customized, intelligent, and reliable solutions tailored to your unique needs.
Get in touch with us today and explore how multimodal AI can work wonders for your business applications.
Want to assess how ready your organization is to adopt advanced AI systems like multimodal models? Try our AI Readiness Assessment Tool to evaluate your current AI maturity and uncover opportunities for growth.
FAQs
1. What is Multimodal AI?
Multimodal AI is an artificial intelligence system that processes and integrates multiple types of data, such as text, images, audio, and video.
By combining these data streams, it can understand context more deeply, provide richer insights, and perform tasks that require cross-modal reasoning, unlike traditional single-modal AI.
2. How does Multimodal AI work?
Multimodal AI uses specialized models and fusion techniques to process different data types. Early fusion combines raw inputs, while late fusion merges processed outputs.
Advanced architectures, such as transformers, align and correlate information across modalities, enabling AI to understand complex relationships and make context-aware decisions across text, vision, audio, and more.
3. Is ChatGPT an example of Multimodal AI?
Yes, specific versions of ChatGPT, like GPT-4o, are multimodal. They can process text alongside images and audio, allowing users to interact naturally through multiple inputs. This enhances understanding, context awareness, and response quality, making the AI more versatile than single-modal versions that rely on text alone.
4. What is the difference between generative AI and multimodal AI?
Generative AI focuses on creating new content, such as text, images, or music, based on learned patterns. Multimodal AI, on the other hand, integrates and interprets multiple data types to understand context or make decisions.
While generative AI can be multimodal, its primary goal is content generation, not comprehensive understanding.
5. What are the Limitations of multimodal AI?
Multimodal AI faces challenges including privacy concerns, potential bias, high computational requirements, and complex management. Misinterpretation of combined data can lead to errors.
A heavy reliance on technology may reduce human judgment, and developing robust, accurate systems requires extensive data, advanced models, and meticulous oversight.
Pinakin Ariwala has over 20 years of experience in AI/ML, data engineering, and software development. He has led AI and machine learning projects across industries, including agriculture, finance, and healthcare, and has been featured on the Clutch Leaders Matrix podcast discussing real-world AI/ML applications.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!