How to Improve Data Quality with Effective Governance Practices
Explore how data quality governance helps ensure clean, reliable, and compliant data across your organization.
Data Analytics and Business Intelligence
How to Improve Data Quality with Effective Governance Practices
Explore how data quality governance helps ensure clean, reliable, and compliant data across your organization.
Table of contents
Table of contents
Introduction
Data Quality Governance Frameworks
Staying Compliant with Data Privacy Laws
Practical Steps to Strengthen Data Governance and Improve Data Quality
Common Data Quality Governance Challenges and How to Solve Them
Conclusion
FAQs
Introduction
Accurate and well-managed data forms the foundation for sound business decisions. Inaccurate or inconsistent data often results in costly business errors. According to a 2021 report by Gartner, poor data quality costs companies an average of $12.9 million every year. IBM's earlier estimate put the total loss for the U.S. economy at a staggering $3.1 trillion.
To avoid such losses, businesses use data governance frameworks and structured approaches that set clear rules for how data is collected, managed, and shared. These frameworks help maintain consistency and improve trust in data across teams.
Alongside data quality governance, compliance ensures that data is handled according to laws and industry standards. Together, they play a key role in keeping data quality high. This blog discusses how governance and compliance support better data, offers best practices to follow, and explores the common challenges companies face and how to overcome them.
Data Quality Governance Frameworks
A well-defined data quality governance framework lays the foundation for how an organization manages, protects, and uses data. It brings structure through policies, roles, tools, and processes that help maintain high data quality and ensure compliance with regulations. Below are the key components of a strong data governance setup:
1. Defined Framework and Principles
Start by setting up a clear structure for your data governance efforts. Explain the purpose, goals, and rules so everyone understands how and why it’s being done.
2. Policies and Procedures
Write down standard steps for handling data: how it's collected, stored, secured, and shared, so it stays aligned with business needs and legal rules.
3. Data Quality Management
Implement systems to check if your data is accurate, complete, and reliable. Regular checks, cleanups, and clear quality standards help keep it in good shape.
4. Data Catalog and Metadata
Build a searchable catalog that helps teams find and understand the needed data. Include details like where the data comes from and how it should be used
5. Security and Privacy Controls
Keep data safe from misuse and follow privacy laws. Use access control, encryption, and masking to protect sensitive information.
6. Integration and Interoperability
Make sure different systems can share and use data smoothly by using standard formats and integration tools.
7. Change Management
Handle updates to data definitions or rules through a clear review process. Data stewards usually help keep things consistent.
8. Training and Awareness
Regularly train your teams so they understand their role in handling data properly and follow best practices.
9. Performance Monitoring
Track how well your governance efforts are working. Use these insights to fix gaps and improve over time.
Roles and Responsibilities
A strong data quality governance team brings together data admins, stewards, custodians, and everyday users, each playing a key role in keeping data reliable, secure, and easy to use. Their roles and responsibilities are:
Data Administrators oversee the entire governance program and ensure it's running smoothly.
Data Stewards act as the link between business and IT, setting data standards and resolving issues.
Data Custodians manage the storage, access, and movement of data within systems.
Data Users like analysts, marketers, or executives, use data to make decisions and drive business outcomes.
Data Quality Tools and Technology
Many organizations use data quality and governance tools to automate tasks such as tracking changes, managing permissions, or creating data catalogs. These tools improve consistency and make it easier to stay compliant.
When roles, rules, processes, and tools all come together, data becomes a trusted asset. It supports smarter decisions, reduces risks, and builds a data-driven culture across the organization.
Staying Compliant with Data Privacy Laws
When managing data, companies must comply with key regulations that protect privacy and ensure responsible data handling. Two major ones include GDPR (General Data Protection Regulation) in Europe and HIPAA (Health Insurance Portability and Accountability Act) in the U.S. These laws define strict standards for collecting, storing, sharing, and deleting personal and sensitive data.
Businesses must keep data safe and private to comply with regulations and protect it from misuse or breaches. This means only letting the right people see it, locking it with encryption, and tracking its use. Regular checks help identify and resolve issues before they escalate.
Ignoring regulations can result in hefty fines and reputational harm. On the other hand, compliance builds customer trust and strengthens your organization’s security. It’s not just about avoiding penalties; it shows your commitment to data privacy.
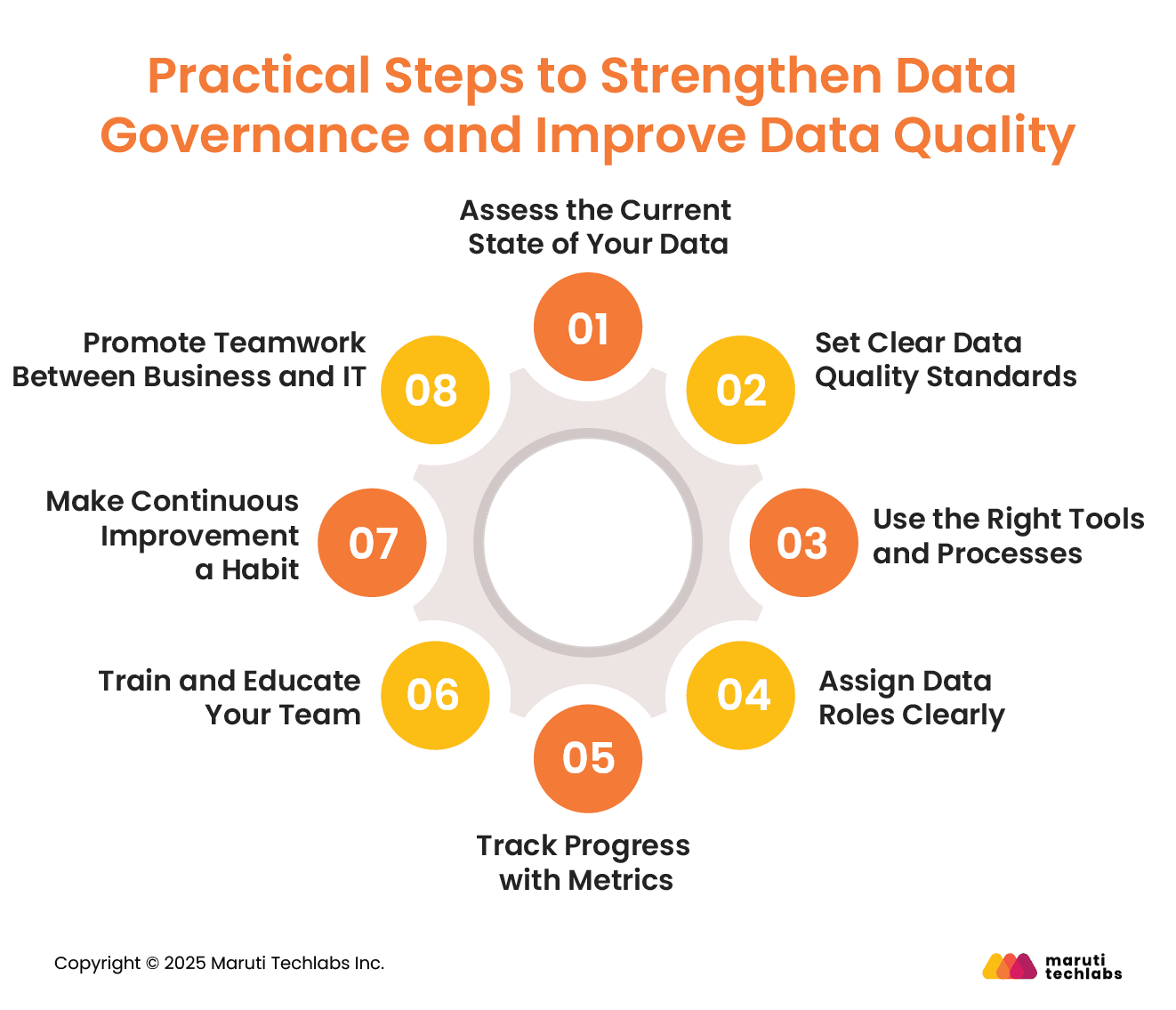
Practical Steps to Strengthen Data Governance and Improve Data Quality
Building a strong data quality governance program starts with knowing where your data stands today and taking consistent steps to improve it over time. Here are some practical actions to help you get there:
1. Assess the Current State of Your Data
Begin by analyzing your existing data to spot common issues like errors, duplicates, or missing values. This will give you a clear picture of what needs fixing and set a baseline to measure future improvements.
2. Set Clear Data Quality Standards
Decide what “good data” looks like in your organization. Define what makes data accurate, complete, and consistent. Then, make sure everyone understands and follows these standards.
3. Use the Right Tools and Processes
Choose data quality and governance tools that help profile, clean, and validate data. Build simple workflows that regularly check data for problems and fix them before they spread.
4. Assign Data Roles Clearly
Appoint data stewards and owners responsible for keeping data clean and reliable. They should know how to handle data issues and work closely with teams to ensure quality.
5. Track Progress with Metrics
Set clear goals for data quality and monitor them regularly. Use automated checks and reports to see where things are working and where they need improvement.
6. Train and Educate Your Team
Help your team understand why data quality matters. Training sessions can show how bad data hurts the business and what role each person plays in keeping it accurate.
7. Make Continuous Improvement a Habit
Data quality governance is not a one-time effort. Keep reviewing your data quality and governance tools, processes, and standards. Use feedback to make improvements and adapt to changing needs.
8. Promote Teamwork Between Business and IT
Encourage open communication between business users and technical teams. When everyone shares responsibility for data, it leads to better understanding, fewer errors, and stronger results.
Together, these practices help create a culture where clean, reliable data supports every decision your organization makes.
Common Data Quality Governance Challenges and How to Solve Them
As companies grow, they get data from many places, and managing all of it gets harder. There are things like keeping it safe, making sure it’s correct, and helping teams use the right data. These can be tricky. Here are some common problems in data quality governance and easy ways to deal with them:
1. Managing Data Across Silos
When data is stored in separate systems or departments that don’t talk to each other, it becomes difficult to get a complete and accurate view. Teams may end up working with outdated or conflicting data, leading to poor decisions.
Solution: Implement a central data catalog that brings data from different sources together in one place. This will help break down silos, improve access, and ensure everyone is working from the same version of the truth.
2. Ensuring Real-Time Data Accuracy
With new data constantly being created, keeping it accurate and up to date is a real challenge. Inconsistent data can affect reports, dashboards, and business insights.
Solution: Use automated tools for data profiling, validation, and cleansing. Set up regular checks to catch and fix errors early. Automation also helps save time and reduces the risk of human mistakes.
3. Sustaining Ongoing Monitoring and Improvement
Many organizations establish governance rules but neglect to monitor them. Over time, these rules can become outdated or ignored.
Solution: Set clear data quality metrics and build systems to monitor them regularly. Encourage teams to review and update data processes often and create feedback loops to improve continuously.
4. Ensuring Data Security and Compliance
Data privacy laws like GDPR, HIPAA, and CCPA require strict control over who accesses sensitive information. Without proper governance, there’s a risk of data leaks or fines for non-compliance.
Solution: Implement strong access controls and encryption to ensure only authorized individuals can access sensitive data. Use monitoring tools that track data usage and automatically flag potential issues before they become serious.
5. Scaling Governance as Your Business Grows
As the volume of data increases and more users join, your initial governance setup might not be enough. What worked for a small team may not work for a growing enterprise.
Solution: Choose data quality and governance tools and processes that can scale with your needs. Revisit and update your governance strategy regularly to keep pace with growth, technology changes, and regulatory updates.
By recognizing these common challenges and acting on them with the right tools, roles, and mindset, organizations can create a strong and scalable data governance framework. This not only protects data but also makes it more useful for decision-making.
Conclusion
Data governance is not a one-time project; it’s an ongoing process that grows with your business. Continuous improvement comes from setting clear policies, validating data regularly, training teams, and maintaining accurate documentation. Monitoring data quality metrics and creating feedback loops helps catch issues early and drive steady enhancements.
By taking small but consistent steps, like using data cleansing tools or offering workshops on data quality, organizations can build a strong foundation for trustworthy, high-quality data.
At Maruti Techlabs, we work closely with businesses to strengthen their data governance through practical, scalable data engineering solutions. If you're looking to improve how your organization handles and trusts its data, we’d be glad to support you.
ETL stands for Extract, Transform, Load. It is a data integration process used to collect data from multiple sources, transform it into a suitable format or structure, and then load it into a target system, such as a data warehouse or database. ETL helps organizations clean, organize, and centralize their data to support reporting, analytics, and decision-making processes more efficiently.
2. Is Python an ETL tool?
Python itself is not an ETL tool, but it can be used to build custom ETL pipelines. With libraries like Pandas, SQLAlchemy, and Apache Airflow, Python provides powerful capabilities to extract, transform, and load data. It’s a flexible choice for developers who want to create tailored ETL workflows rather than use pre-built, drag-and-drop ETL platforms like Talend or Informatica.
3. What is an ETL example?
An example of ETL is collecting sales data from multiple branch databases (Extract), converting the currencies to USD and standardizing date formats (Transform), and loading the cleaned data into a central data warehouse (Load). This allows a business to view and analyze its total sales performance across regions consistently, supporting better reporting and strategic planning.
4. What is the best ETL tool?
The best ETL tool depends on your specific needs, such as scalability, budget, and ease of use. Popular tools include Apache NiFi, Talend, Informatica, AWS Glue, and Apache Airflow. Python-based frameworks are widely used for simpler or custom solutions.
Cloud-native tools like Fivetran and Stitch are great for modern, low-maintenance ETL. The ideal choice balances performance, flexibility, and integration.
5. What is an ETL pipeline?
An ETL pipeline is a sequence of steps that automate the Extract, Transform, and Load process. It moves raw data from source systems through transformation rules and loads it into a storage destination like a data warehouse or data lake. ETL pipelines are typically scheduled to run at regular intervals and are designed to handle large volumes of data reliably and efficiently.
About the author
Pinakin Ariwala
Pinakin is the VP of Data Science and Technology at Maruti Techlabs. With about two decades of experience leading diverse teams and projects, his technological competence is unmatched.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!