How To Establish Domain Ownership in a Data Mesh Architecture?
Explore the challenges & best practices to establish domain ownership in a data mesh architecture.
Data Analytics and Business Intelligence
How To Establish Domain Ownership in a Data Mesh Architecture?
Explore the challenges & best practices to establish domain ownership in a data mesh architecture.
Table of contents
Table of contents
Introduction
Why is Domain Ownership a Core Principle of Data Mesh Architecture?
How Domain Ownership Enables AI/ML at Scale in Data Mesh Architectures?
6 Key Steps to Define & Operationalize Domain Ownership in Data Mesh Architecture
6 Common Challenges with Establishing Domain Ownership in Data Mesh Architecture
Top 6 Best Practices for Implementing Domain Ownership in Data Mesh Architecture
Conclusion
FAQs
Introduction
Today, data is an ever-growing asset that often expands exponentially. Managing and leveraging such vast data for decision-making is challenging.
Organizations that struggled to collect data are now facing the problem of data silos and efficiently managing it. Here’s where the concept of data mesh helps enhance operational efficiency. Let’s begin by understanding what a data mesh is.
“Data Mesh is the process of decentralizing data in a centralized storage system like a data lake or data warehouse. It’s a modern domain-oriented architecture.”
In a data mesh, data is collectively gathered but is stored independently according to its business domain, like marketing, sales, operations, and more.
Domain ownership is of paramount importance in a data mesh. In other words, each domain or department within an organization is responsible for gathering, processing, organizing, and managing data. The domain owner possesses the ownership of their respective datasets.
This article offers essential insights on the importance of domain ownership in data mesh, how it enables AI/ML development at scale, its challenges, and its implementation.
Why is Domain Ownership a Core Principle of Data Mesh Architecture?
Here are 4 significant reasons why domain ownership is paramount in a data mesh.
1. Clear Accountability
Domain ownership establishes clear boundaries regarding who is responsible for a specific data domain. This eliminates the ambiguity observed with centralized data repositories. The owners of the domain are accountable for the generated data and derived insights.
2. Streamlined Data
Decentralization shifts the responsibility to domain owners for discovering, sharing, and sorting their datasets. This divides the accountability for conducting these activities, ensuring an efficient data flow across the organization.
3. Context-Rich Data Products
Domain owners are expected to clean, enrich, and present data, retaining its business context. This not only enhances data operability but also makes it analytically ready for other teams. The context-rich data is meaningful and easy to understand for all other teams.
4. Agility & Scalability
Decentralization introduces agility to quickly adapt to changing requirements and scalability to the data infrastructure, removing bottlenecks. Subsequently, it facilitates innovation while adhering to enterprise-wide data strategies.
How Domain Ownership Enables AI/ML at Scale in Data Mesh Architectures?
Domain ownership plays a crucial role in scaling AI/ML across your enterprise. A well-known approach is for data science teams to act as consumers of domain-owned data products.
They leverage numerous data sets for data exploration and feature engineering to develop AI/ML models. At times, domain teams also create their models merging their data with other to curate rich features.
This setup presents challenges like:
Data science teams may lack the deep domain knowledge demanded by complex feature engineering.
Extra efforts are required when teams independently create similar features.
Inconsistent feature sets impact model reproducibility and require continuous updates as data products evolve.
Models shared in formats like ONNX often become black boxes, making cross-domain integration harder.
On the contrary, a domain-driven feature engineering strategy addresses the above challenges by:
Providing high-quality contextualized data products.
Enhance feature engineering, enabling reusable features and minimizing effort duplication across teams.
Enable scalable collaboration as features and models become discoverable and composable across domains.
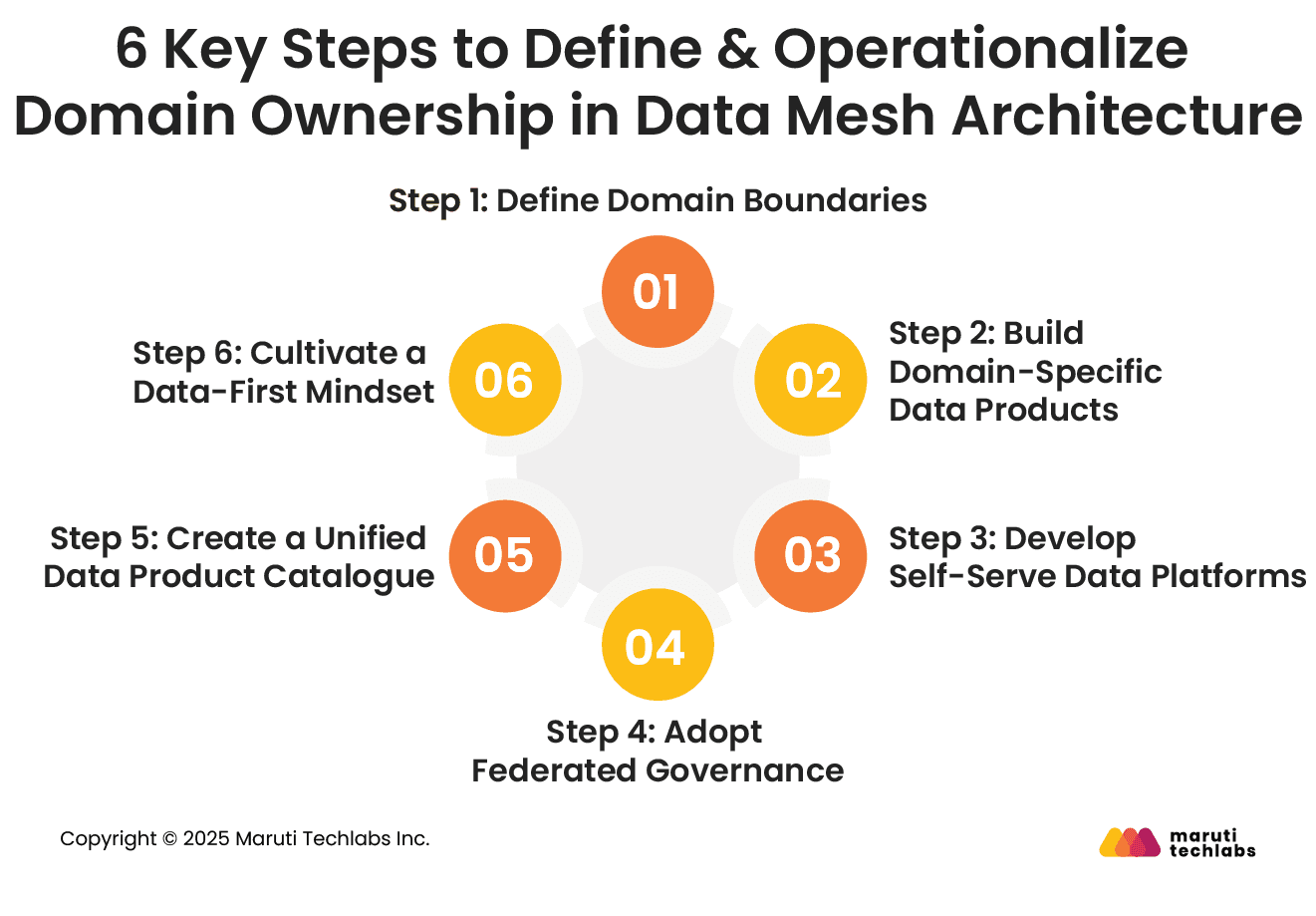
6 Key Steps to Define & Operationalize Domain Ownership in Data Mesh Architecture
Implementing data mesh is a cumbersome process that requires extensive planning and a step-wise approach. Here are six steps to implement domain ownership in a data mesh.
Step 1: Define Domain Boundaries
Set clear boundaries between domains based on business departments, processes, and data ownership by collaborating with stakeholders.
Step 2: Build Domain-Specific Data Products
Encourage each domain to identify and define its data products. This includes data detailing, API’s they expose, and setting clear quality benchmarks.
Step 3: Develop Self-Serve Data Platforms
Offer a self-serve data infrastructure to domain teams that has essentials like tools, frameworks, and governance mechanisms for effective data product management.
Step 4: Adopt Federated Governance
Give autonomy to domain teams to make localized decisions while having in place a federated governance model that has global standards, policies, and best practices.
Step 5: Create a Unified Data Product Catalogue
Improve data discoverability for each domain’s data assets by building a data product catalogue including metadata, usage instructions, and access guidelines.
Step 6: Cultivate a Data-First Mindset
Inculcate a culture of data literacy and collaboration in your organization. Encourage domain teams to leverage data as an asset to drive business value.
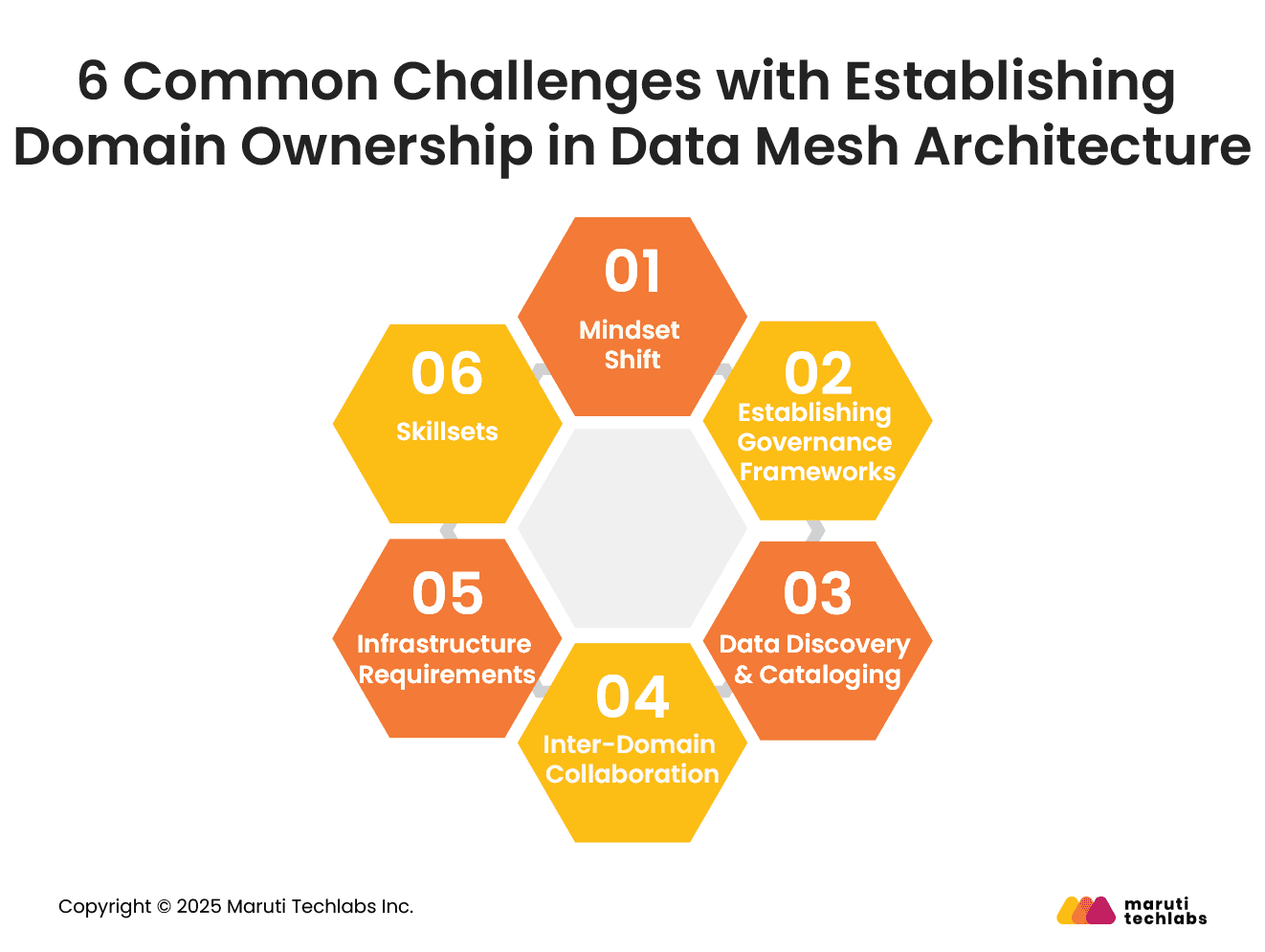
6 Common Challenges with Establishing Domain Ownership in Data Mesh Architecture
Decentralizing a data strategy can initiate a transformative change in how a business manages and utilizes its data. Like any other technological shift, this also presents a set of challenges that must be addressed to ensure a successful implementation.
Here’s a list of 6 such challenges.
1. Mindset Shift
Making a switch from a conventional centralized data approach to a decentralized data mesh demands a change in mindset. It requires reconsidering data ownership, sharing, and collaboration.
2. Establishing Governance Frameworks
Transitioning to this approach can cause issues with sustaining data quality, security, and compliance. One must find the right balance between establishing data governance frameworks and ensuring data integrity.
3. Data Discovery & Cataloging
With various datasets spread across domains, it’s a challenge to find relevant datasets and know their context, quality, and availability. Therefore, it’s critical to have efficient cataloging and discovery mechanisms in place.
4. Inter-Domain Collaboration
It’s imperative that different domains willingly share and consume data products to implement data mesh successfully. Your domain teams would have to establish clear communication to foster a culture of collaboration and eliminate data siloes.
5. Infrastructure Requirements
It’s essential to invest in the proper infrastructure to observe scalability and good performance with your data mesh architecture.
6. Skillsets
To conduct a successful data mesh implementation, you would need skilled experts in data engineering, data science, and domain-specific expertise. Having the right individuals in your team is essential for the right implementation and skill development.
Top 6 Best Practices for Implementing Domain Ownership in Data Mesh Architecture
Executing domain ownership in data mesh not only requires the right tools and infrastructure but also the need to follow certain best practices. Here is a list of specific practices that can guide your teams through the process.
1. Create a Domain-Driven Design
Domain-driven design is the core of a data mesh. Therefore, it’s crucial to have pre-defined boundaries for each domain. Classify data considering different business domains, ensuring each team is aware of their responsibilities with data management, quality, and compliance.
2. Build Cross-Functional Domain Teams
Foster alignment in data standards, governance, and quality metrics by practicing timely communication and collaboration. This helps your entire organization by introducing consistency across the data mesh, enabling knowledge sharing and learning.
3. Adopt a Data Product Mindset
Emphasize data quality, usability, and accessibility by inculcating a product mindset in domain teams. A data-as-a-product mindset helps teams establish product usage guidelines, set service-level agreements, and maintain data quality.
4. Implement & Iterate
Understand the challenges and make subsequent changes in the process by implementing data mesh principles in selected domains. Leverage feedback and findings from this and plan a gradual expansion to other domains.
5. Automate Governance
Streamline compliance efforts across domains, automating tasks concerning governance like validation, access controls, and data quality monitoring.
6. Prepare a Central Data Product Catalogue
Document data assets across domains, creating a centralized data product catalogue, aiding data discovery and access.
Conclusion
Data Mesh represents a paradigm shift in how organizations approach data. It helps transition from centralized bottlenecks to a decentralized model where domain teams own, manage, and share data as a product.
This approach not only improves scalability and agility but also ensures that data remains trustworthy and actionable at every level. However, adopting Data Mesh doesn’t require a sweeping transformation from day one.
Starting small, focusing on high-value domains, and iterating based on learnings allows organizations to de-risk their journey and build a robust foundation over time. Domain ownership remains the cornerstone of success, fostering accountability, higher data quality, and faster decision-making.
At Maruti Techlabs, we help businesses unlock the true potential of their data with our expert Data Analytics Consulting and a pragmatic approach to Data Mesh adoption.
Ready to transform your data landscape? Partner with us to build scalable, future-ready data ecosystems that drive meaningful outcomes.
FAQs
1. What is a data mesh vs a data lake?
A data lake is a centralized repository for storing raw data, whereas a Data Mesh is a decentralized approach where domain teams own and manage their data as products.
2. What is data mesh and data fabric?
Data Mesh decentralizes data ownership to domains, focusing on people and processes. Data Fabric uses a centralized architecture with technology to connect data across environments seamlessly.
3. What are the 4 pillars of data mesh?
The 4 pillars of data mesh are: domain-oriented ownership, data as a product, self-serve data platform, and federated computational governance.
4. What is the difference between Microservices and data mesh?
Microservices focus on modularizing application logic, while Data Mesh applies similar decentralization principles to data ownership and management. Both promote agility and autonomy but operate at different layers.
5. What are the downsides of data mesh?
The downsides of data mesh include increased complexity, higher governance needs, and potential duplication of efforts without strong coordination and cultural readiness.
Pinakin Ariwala has over 20 years of experience in AI/ML, data engineering, and software development. He has led AI and machine learning projects across industries, including agriculture, finance, and healthcare, and has been featured on the Clutch Leaders Matrix podcast discussing real-world AI/ML applications.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!