How to Manage your Data Science Project: An Ultimate Guide
An ultimate guide to managing your data science project, helping you transform your data into customer insights.
Data Analytics and Business Intelligence
How to Manage your Data Science Project: An Ultimate Guide
An ultimate guide to managing your data science project, helping you transform your data into customer insights.
Table of contents
Table of contents
5 Key Concepts of Data Science Management
What is the CRISP-DM Process Model? Why Do You Need It?
Advantages of CRISP-DM
Key Stages of a Data Science Project
Product Management Tips for Data Science Project
How to Lead Data Science Teams
Habits of Successful Data Science Manager
Challenges and Mitigation Strategies
Conclusion
A growing number of data science projects has led to an increase in the demand for data science managers. It is natural to think that any project manager can do the job or that a good senior data scientist will make an excellent data science manager. But this is not necessarily true.
Data science management has become an essential element for companies that want to gain a competitive advantage. The role of data science management is to put the data analytics process into a strategic context so that companies can harness the power of their data while working on their data science project.
Data analysis and management emphasizes aligning projects with business objectives and making teams accountable for results. It means ensuring that each team is in place, whether under the same office or as a distributed team. It also ensures that the team members are provided with appropriate roles and people contributing towards the project’s success.
Remember, data science management is about transforming data into valuable customer insights and ensuring that these insights are acted upon appropriately by all stakeholders across the organization. Therefore, Data science without effective management is like playing chess without knowing how to move your pieces.
This guide will dive into some key focus areas for data science projects. You will understand the differences between different stages and how to tackle them effectively depending on your end goal with the project. We’ll also go over some strategies for optimizing data science projects and areas that may be considered challenging due to their complexity.
5 Key Concepts of Data Science Management
Below are the five key concepts that every data science manager should consider to manage their project effectively:
1. Engage stakeholders
For any project to be successful, the team must understand and follow the concept of “work smarter, not harder.” The initial step for any data science management process is to define the team’s appropriate project goal and metrics, i.e., a data science strategic plan. Defining goals and metrics will help the team deliver the correct value to the product and the client.
The primary responsibility of a data science manager is to ensure that the team demonstrates the impact of their actions and that the entire team is working towards the same goals defined by the requirements of the stakeholders.
2. Manage people
Being a good data science manager involves managing the project and managing people on the team. An ideal data manager should be curious, humble, and listen and talk to others about their issues and success.
Regardless of how knowledgeable the person is, everyone in the team should understand that they will not have answers to all the project’s problems. Working as a collective team will provide far better insights and solutions to the challenges that need to be addressed than working as an individual.
3. Know data science
Being a data science manager does not mean having expert data science knowledge or previous experience. All you need is a better understanding of the workflow, which can lead you towards the success of each project phase.
Knowledge of the data science project lifecycle is not enough. Understand the challenges you might encounter while working on the project. For instance, preparing your data for the project can be quick or take up to 70% of your efforts. To address this challenge, set up the project timeline before working on the same.
4. Define the process
Practical data science management requires an effective data science process. Therefore, a good data science manager should define the proper procedure and the correct mixture of technology to get maximum impact with minimum effort.
This process is always finalized after discussion and approval of the team working on the project. This discussion should include the selection of frameworks such as CRISP-DM, which will facilitate the structure and communication between stakeholders and the data science team.
5. Don’t assume great data scientists make great managers
There is always the misconception that having excellent technical knowledge enhances the data science management process. But the reality is different. It is often noticed that data scientists repeatedly fail to translate their technical excellence in management.
Also, not all data scientists can lead the teams and work as project managers. For instance, many data science professionals fear losing their technical skills, which they might not use if they shift towards leading and managing the team working on the project. Hence, if they are provided with the manager role, they will skimp on data science management.
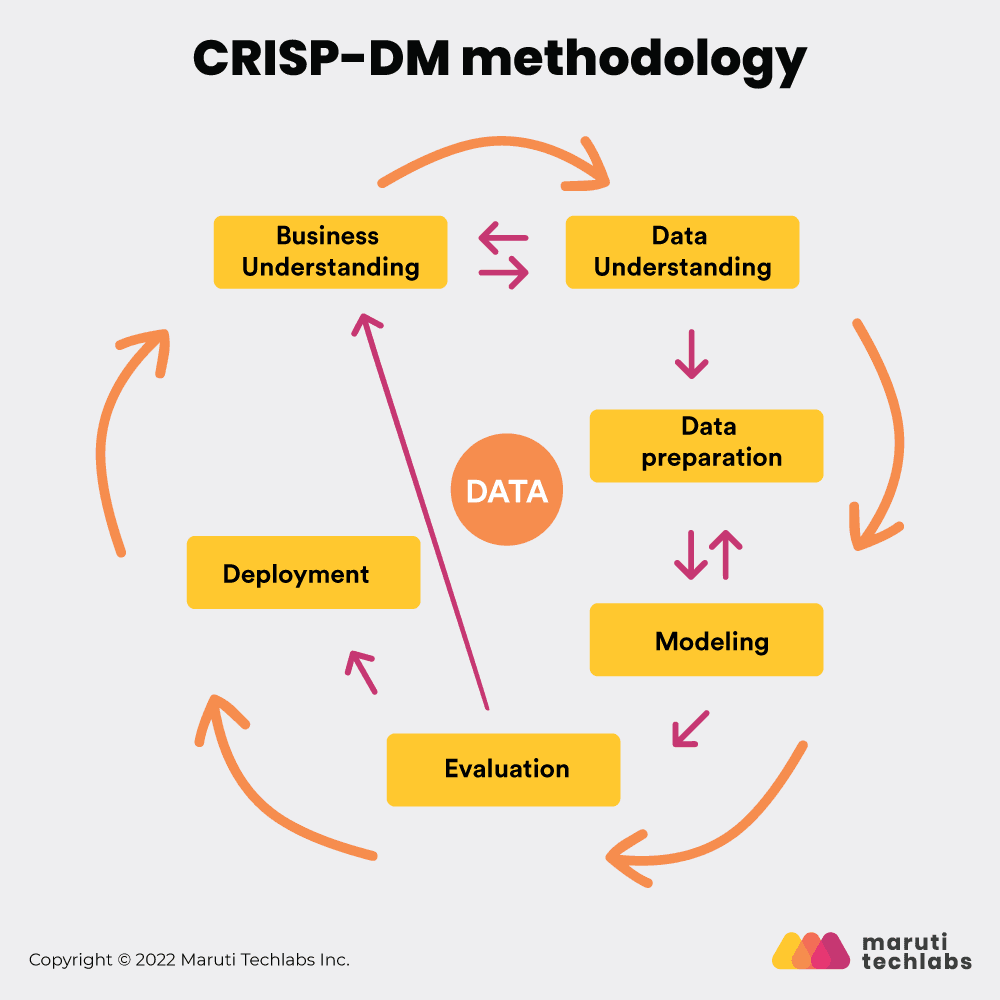
What is the CRISP-DM Process Model? Why Do You Need It?
One of the essential tasks of data science management is ensuring and maintaining the highest possible data quality standards. Companies worldwide follow various approaches to deal with the process of data mining.
However, the standard approach for the same was introduced in Brussels in 1999. This method is generally known as the CRISP-DM, abbreviated as Cross-Industry Standard Process for Data Mining.
The CRISP-DM methodology is as follows:
Business Understanding
Data Understanding
Data preparation
Modeling
Evaluation
Deployment
Each of the above phases corresponds to a specific activity that usually takes you and your team one step closer towards your project goal.
Advantages of CRISP-DM
The primary advantage of CRISP-DM is that it is a cross-industry standard. You can implement it in any DS project irrespective of its domain or destination.
Below are some of the advantages offered by the CRISP-DM approach.
1. Flexibility
Teams new to data science project flow often make mistakes at the beginning of a project. When starting a project, data science teams typically suffer from a lack of domain knowledge or ineffective models of data evaluation. Therefore, a project can succeed if its team reconfigures its strategy and improves its technical processes.
The CRISP-DM framework is flexible, enabling the development of hypotheses and data analysis methods to evolve. Using the CRISP-DM methodology, you can develop an incomplete model and then modify it as per the requirement.
2. Long-term strategy
The CRISP-DM process model, an iterative and incremental data science management approach, allows a team to create a long-term strategy depending on the short iterations. A team can create a simple model cycle during the first iterations to improve upon later iterations. This principle allows one to revise a strategy as more information and insights become available.
3. Functional templates
The CRISP-DM model improves the chances of developing functional templates for development and data science management.
The best approach to reap maximum benefits from CRISP-DM implementation is to create strict checklists for each project phase.
Key Stages of a Data Science Project
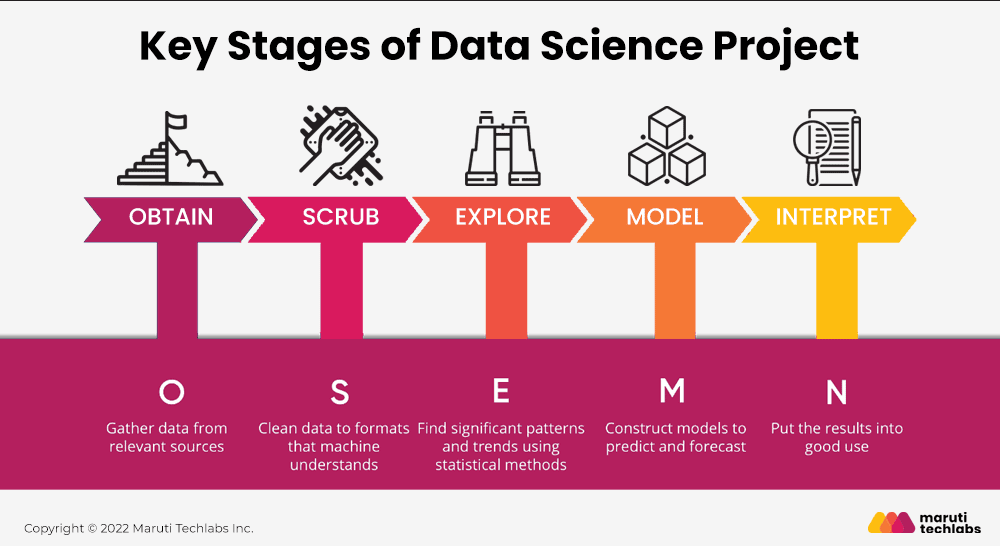
There is no defined process to deal with while working on data science management. However, there is a renowned framework every company chooses to follow for data science management. This framework is known as the OSEMN framework.
The OSEMN framework is a standardized approach to analyzing data. It is recommended for any data set, large or small, and any purpose, from environmental safety to marketing. Each letter in the acronym OSEMN stands for the specific process conducted while analyzing your data in the given sequence.
Let us look at those generalized steps of the OSEMN framework to make your data science management task easy and effective.
1. Obtaining data
It is the initial and most straightforward step of the data science lifecycle. The fundamental goal of this step is to collect data from various sources, and all you need is the query database skills to fetch the data and use it for processing.
Generally, the product manager or project manager is responsible for managing this initial step of the data science lifecycle. Based on the nature of your project, you can use various techniques to collect data.
For example, social media like Twitter and Facebook allow users to connect to their web servers and access the data. Therefore, all you need is to access the Web API of users and crawl through their data.
Regardless of data collection, these steps should consist of:
Identifying the project risks
Align stakeholders with the data science team
Define the potential value of forthcoming data
Encourage team members to work towards the same goal
Create and communicate a flexible and high-level plan
Get buy-in for the project
2. Scrubbing data
The next step is scrubbing and filtering data. That means if you do not purify your data with irrelevant and useless information, the analysis results will not be accurate and mean nothing. Therefore, this step elaborates the “Garbage in, garbage out” philosophy.
After gathering all the data in the initial step, the primary purpose is to identify what data you need to solve the underlying problem. You also need to convert the data from one form into a standardized format, apart from cleaning and filtering the data.
During this life cycle phase, try to extract and replace the missing data values on time. Doing this will help you avoid errors when merging and splitting the data columns while processing it.
Remember not to spend much time over this phase of the life cycle. Investing a lot of time under cleaning the data will ultimately delay the project deadlines without proven values.
3. Exploring data
Once you clean your data, it is time to examine it for processing and draw out the relevant results. Data scientists combine exploratory and rigorous analysis methods to understand the data.
Firstly, to achieve this, inspect the properties and forms of given data and test the features and variables in correlation with other descriptive statistics. For example, doctors explore the risks of a patient getting high blood pressure depending upon their height and weight. Also, note that some variables are interdependent; however, they do not always imply causations.
Lastly, perform the data visualization to identify significant trends and patterns of your data. Simply putting your data in the form of a bar or line chart will enable you better to picture the importance and interdependency of the data.
To deal with data exploration effectively, python provides in-built libraries like Numpy and Pandas. Moreover, you can also use GGplot2 or Dplyr when working with R programming. Apart from these, basic knowledge of inferential statistics and data visualization will be the cherry on the cake.
4. Modeling data
This step of the data science lifecycle is most exciting and essential as the magic happens here. Many data scientists tend to jump on this stage directly after gathering the data from various sources. Remember that doing this will not provide you with accurate output.
The most important thing to do while modeling your data is to reduce the dimensionality of your data set. Identifying the correct data to process the underlying problem is essential to predict the suitable working model of your data science project.
Apart from reducing the data set, train your model to differentiate and classify your data. Also, identify the logic behind the cluster classification inside your data model, which enables you to effectively reach out to the target audience with the content of their interests.
For instance, you can classify the group of subscribers over Netflix depending on their search history and the type of genre they usually prefer to watch. Simply put, the basic idea behind this phase is to finalize the data set and business logic to process your data and share it across your organization.
5. Interpreting data
Interpreting the data refers to understanding that data in terms of a non-technical layman. It is the most crucial and final step of data management in data science. Later, the interpretation results are the answers to the questions we asked during the initial phase of the data lifecycle, along with the actionable insights to process the gathered data.
Actionable insights are the results that show the process of how data science will bring the predictive power of the model to drive your business questions and later jump to prescriptive analytics. It will enable you to learn and identify how to repeat the positive results and prevent the negative outcome from falling into.
You also have to visualize your findings and present them to your team to confirm their usefulness to your organization and won’t be pointless to your stakeholders. You can use visual tools like Charts and Tableau, which enhance your results and interpretation of the data.
Product Management Tips for Data Science Project
1. Provide deeper context
Including developers and designers in the early stages of a product definition brings out the best ideas and results for the product’s success. Putting the best minds together under the same umbrella brings understanding the user, success, constraints, architectural choices, and workarounds.
However, product management with data science has always felt like being with core development teams 25 years ago. It is tough to deal with weak understanding on both sides, specialized terminologies, and misconceptions such as “data science is easy.”
To deal with market problems in such situations, you require to be aggressive about defining the below context:
Identify the key constraints and detailed use cases for your data science team. Point out the players and their roles in the project.
Analyze the business goals and success metrics to boost the license revenue from new customers and reduce the churn rate. Identify the actions required to deal with customer care and increase customer satisfaction.
Share your user research and validation assets with the team and organization. For instance, user complaints about the poor user interface, revenue projections, and whatever connects the team members with the end-user.
2. Remember that the data science projects are uncertain, and our judgment may be wrong
It is pretty easy to assume the outcomes before having an upfront investigation. When dealing with the data sets to predict the future using machine learning and AI models, the real world comes in the way of providing dirty data, entirely apparent results, and poor prediction scores.
For instance, you expect that the machine learning model can help us predict the stock market’s future based on historical data and public disclosures. Instead of proposing the same to your board of meetings directly, it is wise to prove the theory of how you can outthink the marketers and competitors on this prediction.
3. Choosing/ accessing data sets is crucial
The success and failure of the data science project depend upon the actual data sets and not on the intentions or intuitions. There is the possibility that some data sets are better than others, i.e., more filtered or more accessible.
Moreover, organizations may often hide the data behind the regulatory walls, and you may have trouble accessing it. Therefore, investigate the ownership and permission for organizations’ internal data at the beginning of the project. Also, get in touch with external sources which may have acceptable use along with the identifiable consumer data and end-user permission.
4. Describe the accuracy required and anticipate handling “wrong” answer
It is always said that level of accuracy is essential conversation at the very start of any data science project. We spend lots of time and effort identifying “somewhat better than a coin flip” accuracy; however, this is not enough when we put lives at risk in medical prediction applications with numerous false negatives.
Every data science project will have something that surprises us, whether the answer is entirely wrong or teaches us something new about the real world. All you need is a plan for human review of results and escalation to humans when outcomes seem incorrect.
5. “Done” means operationalized, not just having insights
Data scientists coming from a new academic environment consider the success of product development when models meet the target audience and accuracy. The basic idea of product development is to be operationalized and incorporate the model and insights into working software.
Being operationalized in data science can be challenging for the first time. Remember that it is unnecessary for product managers to have all the answers but instead have the right team in the room to identify and solve the given problems and issues. For instance, the fraud detection system should decide further actions in real-time if the transaction is suspected to be compromised at any given moment.
How to Lead Data Science Teams
Some data scientists contribute individually and can effectively lead the data science project despite not having the required skills or training. So the question is: What abilities make a data scientist successful?
Many volumes, including Harvard Business Review, have tried to cover the answer to this question. Let us study a few of the particular points which will enhance your power as the manager to lead the data science project:
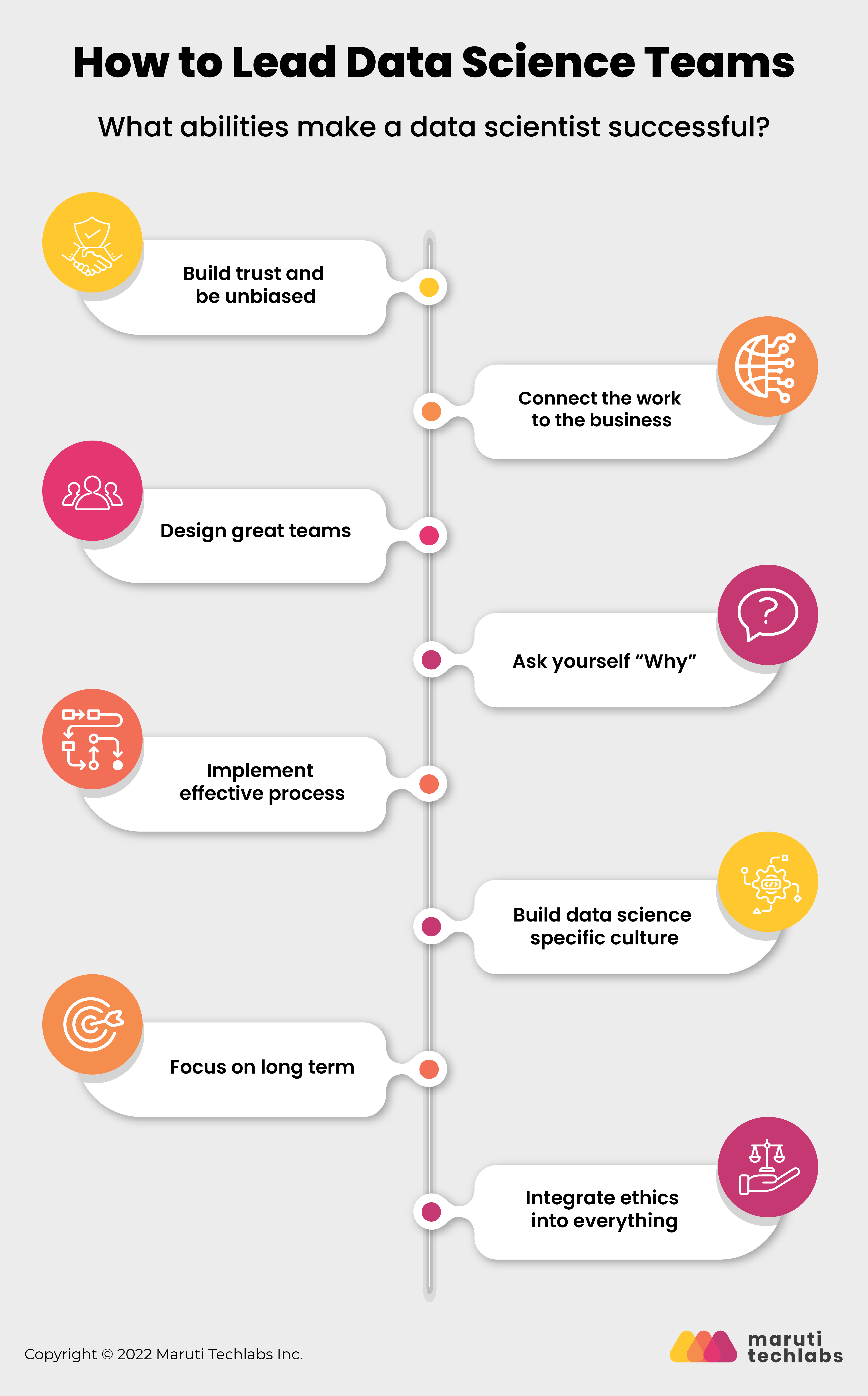
1. Build trust and be unbiased
Trust, loyalty, and authenticity are the critical constraints of good management. In a field like data science, where the confusion lies around the discipline, your team members need to believe that you have their back.
Having employees back does not mean defending them at any cost. You have to make them believe that you value their contributions. The best method to achieve this is by providing the team members with an exciting project to work on and not overburdening them with unclear requirements.
2. Connect the work to the business
Identifying the clear business goals behind the project is the most crucial part of any data science management technique. It is ideal for project managers to align the team’s work with the broader context of organizational strategies.
The best way to connect your work with business is to know what your stakeholders need and how they’ll use the final results. Also, make sure that your team is regularly invited to the product strategies and meetings to provide inputs into the process and make it creative.
3. Design great teams
Data science is the sexiest job of the 21st century. It is where the managers fail to tradeoff between the short and long-term goals for the success of the data science project. Being the data manager, you will receive lots of applications with each day passing, and therefore, it is wise to be picky in filtering these applications incorrectly.
When dealing with the hiring process, the managers encounter many misconceptions, which ultimately set them back from the substantial growth they deserve—for instance, hiring the one with excellent technical skills only. On the contrary, every candidate working as a data scientist requires social skills like communication, empathy, and technical skills for leading the project towards great success.
4. Ask yourself “Why”
It is generally observed that we jump right into doing “what” needs to be done without answering “why” it needs to be done. It is examined that great leaders like Simon Sinek inspire their team with the actual purpose of their work. Doing so will enable them to dive deeper into the project’s aim and consistently motivate them to achieve the goal.
5. Implement effective process
The practical data science processes and workflow does not necessarily mean implementing the specific agile frameworks. Instead, it would help if you managed your team to educate on the necessity of particular work, discover the practical process that fits the work’s unique need, and lead the path of continuous improvement.
Looking at Jeff’s survey talking about their process, about 80% of data scientists say that they “just kind of do” the work that needs to be done, ultimately leading to reduced productivity and increases in risk factors.
6. Build data science specific culture
There is often a misconception of data science being the same as software development. Even though these fields overlap remarkably, data scientists have a clear mindset compared to typical software developers.
Managing data science teams as software developers is likely to misunderstand them and frustrate them for non-productive planning exercises. It is wise to build a culture where data scientists can do their best and avoid this situation.
7. Focus on long term
Just like mentioned by Luigi from MLinProduction, “No machine learning model is valuable unless it’s deployed into production.”
For stakeholders to access the current sustainable and stable system, delivering sustainable value using predictive models is essential. To ensure your team’s work provides lasting value, you’ll have to balance what might seem like a never-ending firehose of stakeholders’ requests with the need to dedicate the time necessary to build production systems.
This production system will enable you to check incoming data, provide alerts if data is missing or out of acceptable ranges, and deliver accuracy metrics that allow the data scientists to monitor and tune the models when needed.
8. Integrate ethics into everything
Business ethics is always a tricky subject. As fast as the field starts evolving, the messier it gets. So the question is: While working on data science management, are all your team’s practices ethical?
It is wise to ensure that your teams and project outcomes are compliant with business goals and relevant laws. Remove the unfair bias results and know-how your work impacts the broader community. Remember that your assessments could mean life and death situations for others.
Habits of Successful Data Science Manager
Below are a few of the common habits that every successful data manager should incorporate while dealing with data science management:
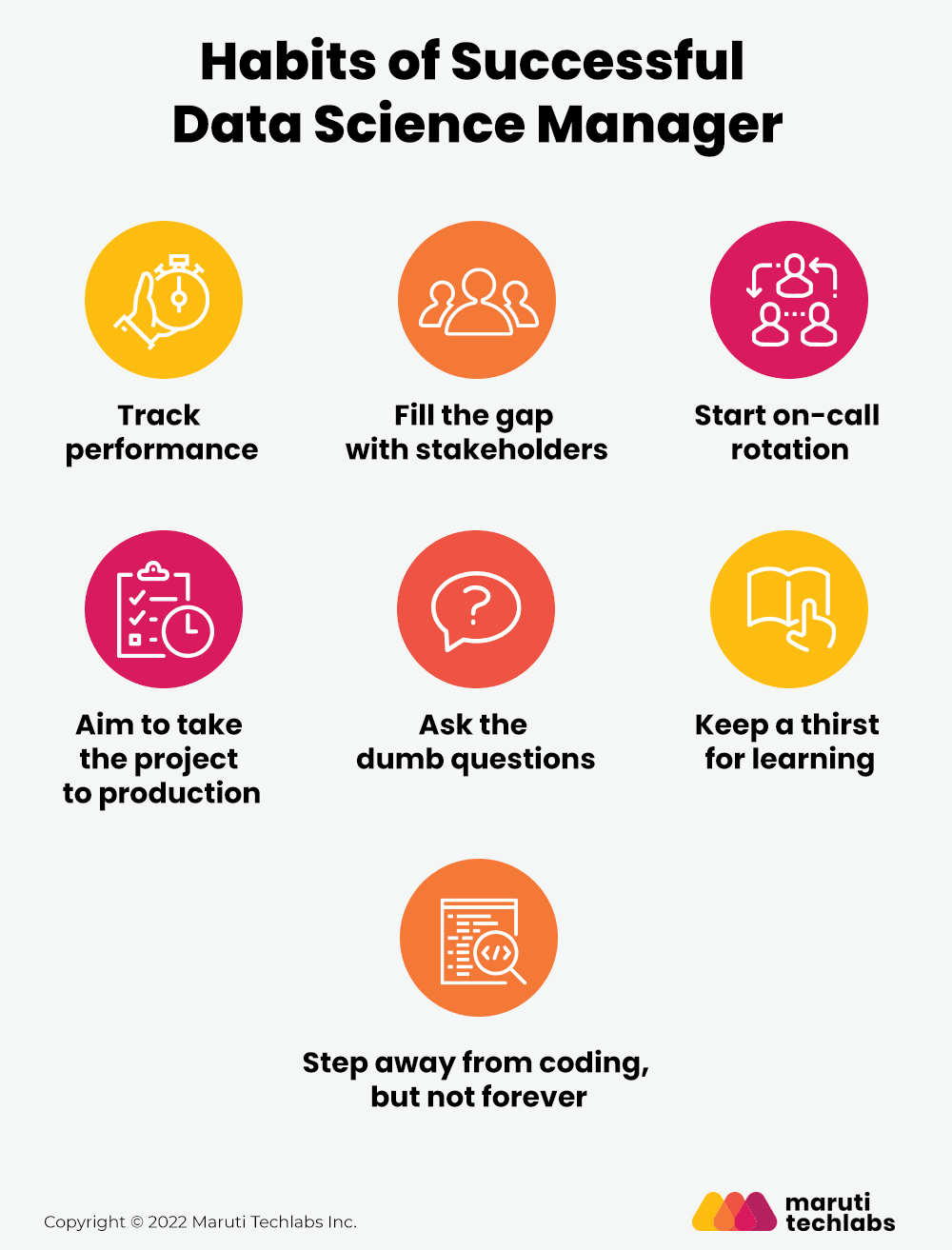
1. Track performance
2. Fill the gap with stakeholders
3. Start on-call rotation
4. Aim to take the project to production
5. Ask the dumb questions
6. Keep a thirst for learning
7. Step away from coding, but not forever
Challenges and Mitigation Strategies
Every data science manager faces many risks and challenges while dealing with data science management. A consequence of data not being available at the start of the project are severe for client and consultant; below are some of the steps that you can follow one month before the project is started:
a] Get all of the below requirements from the client before being on the project.
Access to data
NDA
Access to cloud computing account and internal repository if applicable
Identification of all stakeholders, reporting managers, and other concerned individuals in the organization.
Specify the person to contact in case of project blockers.
b] Organize a kickoff meeting for one week after gathering all the above requirements and one month before starting the project.
c] Encounter all the possible issues and situations which can lead to a block of the project
d] Be in touch with the stakeholders to ensure that everything is in place right from the start of the project.
By taking these steps, you will be able to gather all the data before the initial stage of the project and identify any blockers at the early stages of the project life cycle.
How the Data Science Process Aligns with Agile
Dealing with data science brings a high level of uncertainty.Below are several reasons for how agile methodologies align with data science.
a] Prioritization and Planning
Proper prioritization of work enables the data scientists to give a brief overview of each goal to their team members and non-technical stakeholders. The agile methodology prioritizes the data and models according to the project’s requirements.
b] Research and Development
It is difficult to identify the exact plan which can lead us to the end goal. All you need is constant experiments and research, making the work more iterative. Being iterative is perfect for such agile data science projects.
Conclusion
Businesses are increasingly adopting data science to gain insights into their customers, markets, and operations to gain a competitive advantage. However, as the data science landscape grows and its applications evolve, organizations must find ways to stay ahead of the competition by finding continuous automated and actionable features.
Data-driven applications are more tricky in comparison to deterministic software development. Knowing the concepts and fundamentals of data science management is essential, but it is even more critical to understand how to apply them in different situations.
Working with data scientists has some unique challenges to deal with. We hope you can better assist your data science team with the help of this comprehensive guide.
Our data engineering experts can guide you in structuring your data ecosystem by designing, building, and maintaining the infrastructure and pipelines that enable you to collect, store, and process large volumes of data effectively.
Our team of data scientists provides data analytics and automated solutions to help businesses gain the essence of actionable insights through an ever-expanding sea of data. Our experience in various industries allows us to tailor our project management methodology to the needs and goals of every client.
Over the past decade, working on hundreds of products has helped us develop a unique set of data science tools that help our clients assemble, combine, and endorse the right data. Our data analysis process is aligned to draw maximum impact with minimum efforts and make informed decisions for your business, ultimately taking you one step closer towards your goal.
Pinakin is the VP of Data Science and Technology at Maruti Techlabs. With about two decades of experience leading diverse teams and projects, his technological competence is unmatched.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!