How To Avoid Failures In AI Systems With Resilient Microservices?
Explore how resilient microservices enable reliable, scalable, and high-performance AI systems.
Artificial Intelligence and Machine Learning
How To Avoid Failures In AI Systems With Resilient Microservices?
Explore how resilient microservices enable reliable, scalable, and high-performance AI systems.
Table of contents
Table of contents
Key Takeaways
Introduction
Why Microservices Should be Resilient?
6 Benefits of Executing Resilience Patterns
Top 8 Challenges with Implementing Resilience Patterns
5 Strategies to Build Resilient Microservices
Conclusion
FAQs
Key Takeaways
Resilient microservices are crucial for building reliable, high-performance AI systems.
Implementing resilience patterns improves availability, scalability, and user experience.
Top implementation challenges include managing complexity, tuning configurations, and ensuring data consistency.
Cascading system failures can be prevented with strategies like circuit breakers and bulkhead patterns.
Continuous testing and monitoring strengthen system adaptability and long-term stability.
Introduction
Dealing with unexpected failures is one of the toughest challenges in modern software systems, particularly in the distributed environments that power AI-infused products.
Developers spend significant time writing and testing exception-handling code, but true resilience goes beyond that. A resilient microservice must detect failures, recover quickly, and restart on another machine without disrupting performance or data integrity.
This demands reliability not only in computation but also in how data is stored and recovered, ensuring consistency and availability. The problem becomes even more complex during application upgrades, when systems must decide whether to continue with a new version or roll back safely while maintaining overall stability.
This blog explores the significance of resilience in microservices for AI systems, the primary challenges developers encounter, and the most effective strategies for constructing systems that can self-heal, adapt, and maintain continuous, intelligent performance even in the face of failures.
Why Microservices Should be Resilient?
Resilience is a fundamental trait, not optional, in microservice architecture. AI systems face issues such as partial failures, latency, and cascading effects that can disrupt all services.
Building resilient service from the ground up ensures your AI systems handle failures gracefully. Resilient microservices maintain availability and reliability while withstanding and recovering from failures.
To manage failures effectively, one can use techniques such as bulkheads, circuit breakers, and exponential backoff retries. This helps deliver a better user experience and reduce system downtime.
Investing in resilience yields long-term returns. It enhances customer satisfaction, stability, and decreases the impact of outages. However, developing resilient microservices requires robust monitoring, sound design, and adjustments informed by real-world scenarios.
It’s also essential to validate resilience, using techniques like chaos engineering. Giants like Uber and Netflix have also employed this method to identify weaknesses and enhance their systems. Your microservices can handle adversity by proactively testing and refining resilience measures.
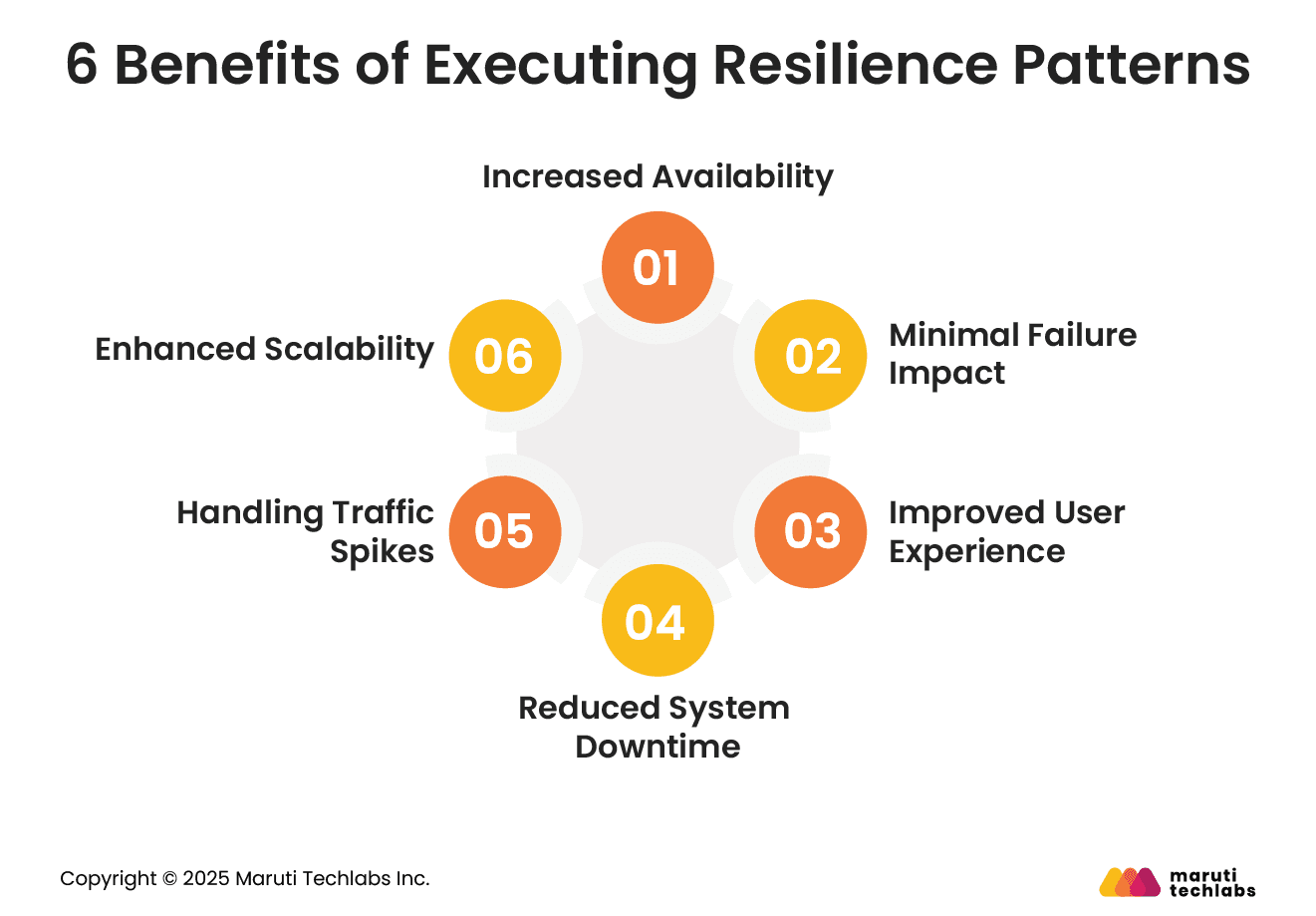
6 Benefits of Executing Resilience Patterns
AI systems are bound to experience unexpected loads or failures at some point. Therefore, implementing resilience patterns can increase stability, availability, and performance.
Let’s take a look at the key benefits these patterns bring.
1. Increased Availability
Single service failures can affect entire systems. This can be avoided by using resilience patterns, such as timeouts and circuit breakers. Systems can maintain higher uptime and accessibility by isolating and recovering from failures.
2. Minimal Failure Impact
The impact of failures can be minimized using techniques like fault isolation. This eliminates the cascading effect, disrupting your entire AI system.
3. Improved User Experience
Even if a few services are unavailable, your microservices can still function well with resilience patterns such as fallbacks, caching, and retries. This offers faster response times while ensuring fewer disruptions.
4. Reduced System Downtime
Complete outages are a rare sight for AI systems that have implemented resilience patterns. Techniques such as retries, circuit breakers, and auto-recovery ensure that minor issues don’t escalate into full-scale outages.
5. Handling Traffic Spikes
Resilience patterns ensure that traffic spikes are handled effectively with techniques such as queue-based load leveling and load shedding. It prevents systems from getting overwhelmed by handling high-priority tasks first.
6. Enhanced Scalability
Resilience patterns ensure smooth operations and avoid bottlenecks under varying workloads, facilitating independent scaling of services. Systems can dynamically adjust to traffic, easing scalability.
Top 8 Challenges with Implementing Resilience Patterns
Adding resilience is not just a technical decision. It affects cost, latency, design choices, and long-term maintainability. Here are the key challenges organizations face while implementing resilience patterns.
1. System Complexity
Resilience patterns increase system complexity. Maintaining and managing each pattern designed for specific failures can complicate the overall architecture.
2. Configuration Tuning
Parameters used in resilience patterns, such as retry intervals and timeout durations, require precise configuration to ensure optimal performance. Inadequate tuning can cause excessive delays or failures.
3. Latency & Overhead
Introducing resilience patterns demands some operational overhead. For instance, circuit breakers need constant monitoring. In addition, these patterns increase the latency of AI systems.
4. Data Consistency
When failures occur, maintaining data consistency becomes difficult. Multiple services can have varied versions of the same data or an inconsistent state, with patterns such as fallbacks or retries.
5. Cascading Failures
If not configured correctly, introducing patterns such as timeouts and retries can exacerbate the issue. For instance, retrying failed requests can cause problems, such as cascading failures across the system, if numerous services are under stress.
7. Testing Patterns
As one needs to test a variety of failed scenarios, effectively performing testing for resilience patterns can be cumbersome. Testing for different failure scenarios is difficult, but essential resilience mechanisms perform as expected under real-world scenarios.
8. Resource Usage
Performing root cause analysis is complex. Especially when implementing resilience patterns such as timeouts, circuit breakers, and retries. Resilience mechanisms can mask failures. This makes it challenging to identify the underlying issue.
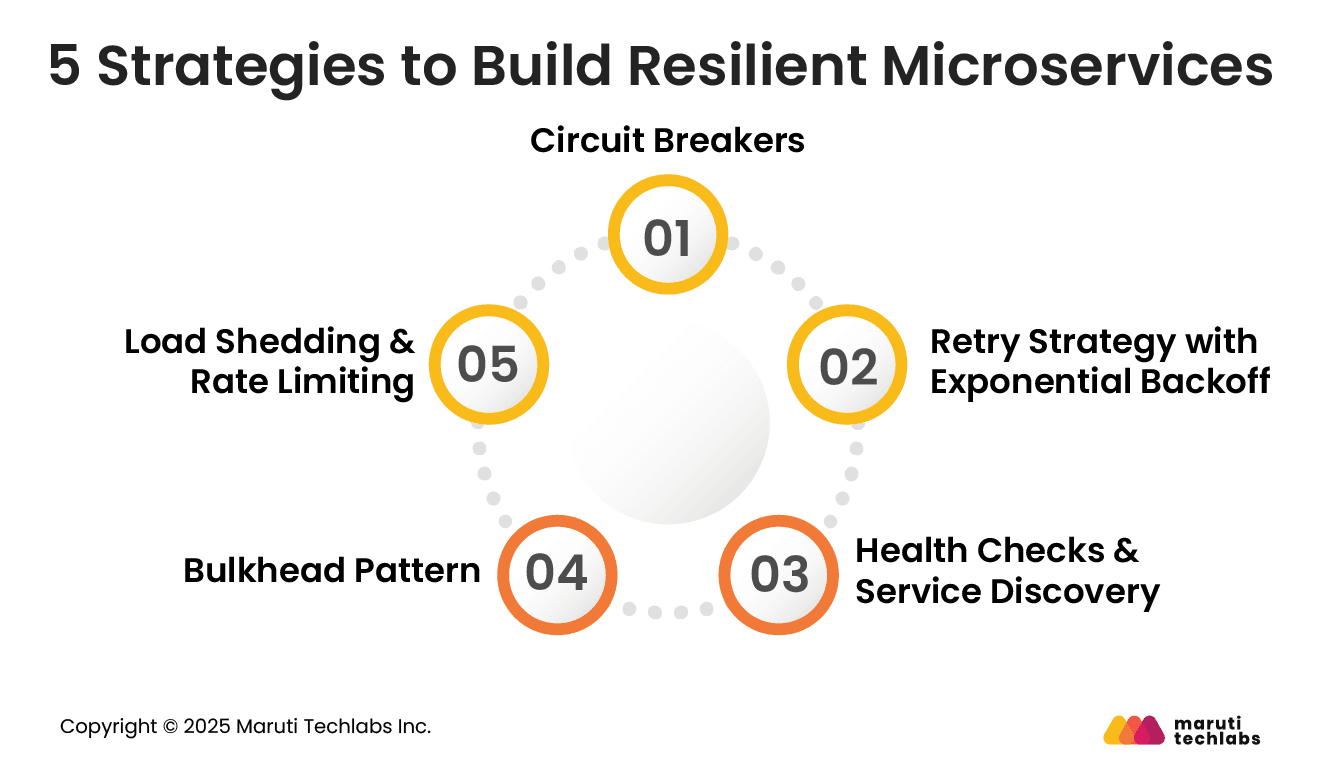
5 Strategies to Build Resilient Microservices
Let’s understand the top strategies that organizations can leverage to introduce resilience patterns within their microservices.
1. Circuit Breakers
Cascading failures can be prevented using circuit breakers. Circuit breakers mimic the behavior of electric switches. They prevent system overloads by pausing calls to failing services.
They also mitigate the failure spread to other system parts by eliminating excessive retries to unresponsive services. However, for them to be effective, the thresholds and timeouts must be configured correctly.
One needs to determine the number of failures before the circuit breaker trips. Also, the wait time before it retries.
2. Retry Strategy with Exponential Backoff
Retry strategies with exponential backoff are another crucial resilience technique. It helps handle momentary failures without affecting other services.
It works by exponentially increasing wait times between retries. This decreases the load on services that are already struggling.
You can add ‘jitter’ to introduce randomness in retry intervals. This prevents multiple clients from retrying at the same time, which can otherwise create additional load and worsen the failure.
Depending on your service type, you should select appropriate failure models and adjust backoff intervals when designing retry strategies.
3. Health Checks & Service Discovery
Maintaining resilience depends heavily on including health checks and service discovery. Service discovery routes requests to healthy instances, enabling services to find and communicate with each other dynamically.
Timely health checks make sure only operational services receive traffic. This prevents requests from being routed to unhealthy or unavailable services.
4. Bulkhead Pattern
The bulkhead pattern limits failures to specific components, preventing them from spreading to other systems. Allocating distinct resources, such as connection pools or threads, to different functions can prevent failures in one area by exhausting resources that others need.
To minimize the impact of failure, separate critical and non-critical functionality when applying the bulkhead pattern. This enhances microservice resilience, as critical functions can continue unaffected even if a non-critical service fails.
5. Load Shedding & Rate Limiting
Rate limiting prevents system overload by limiting service requests during peak demand periods. By learning from performance indicators such as CPU usage or response times, real-time adaptive rate limiting dynamically adjusts these limits. This eliminates the possibility of services getting overwhelmed during traffic spikes.
Load shedding maintains system stability by dropping low-priority requests during peak traffic. This prevents complete system failure by shedding non-essential load and freeing up resources for crucial functions.
Building resilience into microservices demands thoughtful design choices, precise configurations, and ongoing validation through real-world scenarios. As systems grow and AI workloads intensify, resilience patterns help teams manage uncertainty more effectively and sustain consistent performance under changing conditions.
Conclusion
While resilience patterns boost availability and help minimize the impact of failures, teams still need to tackle challenges like growing system complexity and the risk of cascading issues.
Tools like circuit breakers, bulkheads, and load shedding make it easier to spot problems early and stop small failures from snowballing. In the end, resilience is not just about getting through disruptions. It is about helping intelligent systems adapt in real time.
To design and scale AI-driven architectures that are built for performance, flexibility, and dependability, partner with Maruti Techlabs.
Through our Software Product Engineering services, we help you architect and optimize resilient microservices that power the next generation of intelligent, dependable AI products.
Connect with us to discover how we can transform your monolithic architecture into resilient and future-ready microservices.
FAQs
1. What distinguishes an “AI-infused product” in the context of microservices?
AI-infused products embed intelligence directly into workflows through data-driven decisioning, model inference, and automation.
In microservices, this means modular AI components handle tasks like prediction, personalization, or anomaly detection independently yet seamlessly across the architecture.
2. Which architecture patterns support resilience and high performance in AI microservices?
Patterns like circuit breakers, bulkheads, load shedding, and CQRS ensure fault isolation and responsiveness.
Event-driven architecture and asynchronous messaging improve scalability, while sidecar and saga patterns enhance resilience during data processing and service coordination.
3. How do you partition domain boundaries for AI microservices (data ingestion, model serving, analytics)?
Partition domains by function data ingestion for collection and preprocessing, model serving for inference, and analytics for insights.
Each domain operates independently with defined APIs, enabling scalability, faster updates, and minimal cross-service dependency.
4. How do you monitor, version, and manage models within a microservices setup to ensure reliability?
Use MLOps practices, model registries for versioning, CI/CD for automated deployment, and observability tools for drift detection.
Continuous monitoring tracks accuracy and latency, ensuring models remain consistent, reliable, and rollback-ready within microservice ecosystems.
5. How should asynchronous vs synchronous communication be used in AI microservices for performance?
Use asynchronous communication for data pipelines, event-driven inference, and batch processing to improve throughput.
Apply synchronous calls sparingly for real-time requests requiring immediate responses, balancing responsiveness with scalability and fault isolation.
Pinakin Ariwala has over 20 years of experience in AI/ML, data engineering, and software development. He has led AI and machine learning projects across industries, including agriculture, finance, and healthcare, and has been featured on the Clutch Leaders Matrix podcast discussing real-world AI/ML applications.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!