Kubernetes for LLMs: How to Deploy, Challenges & Considerations
Discover what makes Kubernetes the perfect platform for deploying LLMs.
Artificial Intelligence and Machine Learning
Kubernetes for LLMs: How to Deploy, Challenges & Considerations
Discover what makes Kubernetes the perfect platform for deploying LLMs.
Table of contents
Table of contents
Introduction
What are Large Language Models?
10 Steps to Deploy Private LLMs on Kubernetes
Top 8 Challenges with Deploying LLMs on Kubernetes
Conclusion
Introduction
Large language models (LLMs) have transformed the field of Natural Language Processing in recent years. From GPT-3 to PaLM, these models possess the capability to summarize documents, answer questions, generate human-like text, and much more. Although interacting with these LLMs is easy, training them is a cumbersome task. Their computational requirements, monitoring, and maintenance demand extensive resources and money.
In addition, these models are bound to grow in size and capability. Therefore, it’s crucial to choose the right platform that facilitates the development, deployment, and scaling.
One of the platforms that has emerged as a game-changer for deploying LLMs is Kubernetes. It enables the development and deployment of reliable, scalable, highly available, portable, and secure applications.
In this article, we explore why Kubernetes is an excellent choice for LLM deployments, outline the deployment steps, and discuss the challenges one would face when deploying.
What are Large Language Models?
“Large Language Models (LLMs) are deep learning models that are trained on vast amounts of refined data, instilling the capability of understanding and producing natural human-like text and other types of content to perform a varied range of tasks.”
Why Deploy LLMs on Kubernetes?
Deploying LLMs on Kubernetes ensures scalability, efficient resource utilization, and simplified management of complex AI workloads.
Confidential computing, encrypted data writes, and anchor scans protect sensitive LLM workloads.
Enables secure multi-team consolidation with centralized oversight and high availability.
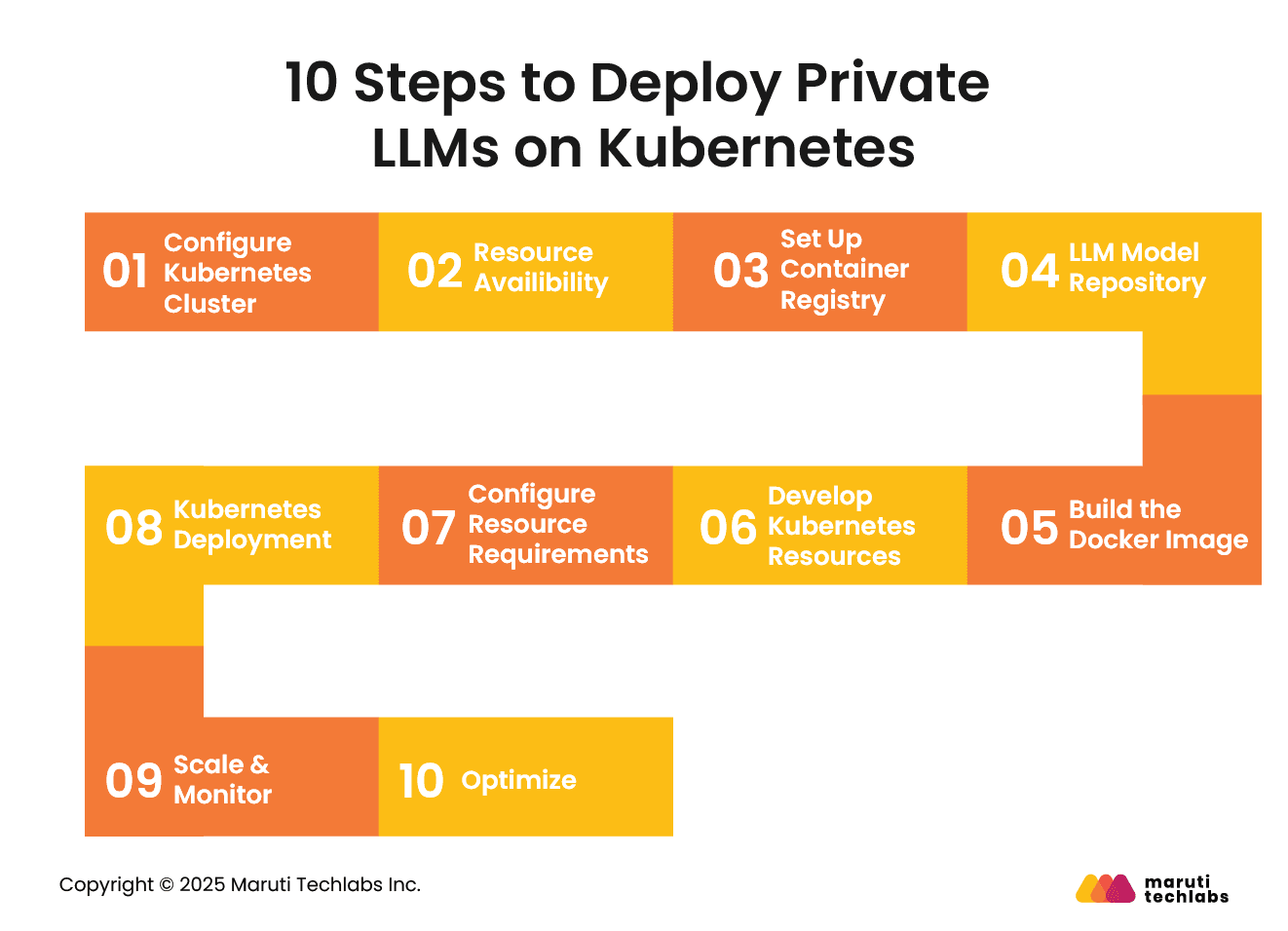
10 Steps to Deploy Private LLMs on Kubernetes
Here are the top 10 steps that one must follow to deploy LLMs efficiently and effectively on Kubernetes.
1. Configure Kubernetes Cluster
The initial step would be to configure the Kubernetes cluster. Post-configuration, run it on on-premise or cloud platforms such as Amazon Elastic Kubernetes Services (EKS), Google Kubernetes Engine (GKE), and Azure Kubernetes Service (AKS).
2. Resource Availability
It’s imperative that a Kubernetes cluster has GPU access, either physical or cloud-based.
3. Set Up Container Registry
The next step is to establish a container registry to save LLM Docker images. Some examples of container registry include Azure Container Registry (ACR), Google Container Registry (GCR), Docker Hub, and Amazon Elastic Container Registry (ECR).
4. LLM Model Repository
Train required models or leverage different sources to prepare a summary of pretrained LLM model files. Use Docker or a container runtime to containerize LLM applications.
5. Build the Docker Image
Build Dockerfiles with specific environments and dependencies required for LLMs. Use Docker to create the image from the Dockerfile. Transfer the created image to a container registry.
6. Develop Kubernetes Resources
Manage the pods running LLM by defining Kubernetes deployments. Expose LLM pods to other areas of the cluster or external clients by establishing services. Leverage Secrets for sensitive information, such as API keys and ConfigMaps, to manage configuration data.
7. Configure Resource Requirements
The following Kubernetes resources need adequate configuration to offer optimized performance.
Requests: List the minimum resources required for the LLM application. Kubernetes guarantees these resources.
Limits: Define the maximum CPU and memory an LLM application can use, preventing a single pod from monopolizing cluster resources.
Horizontal Pod Autoscaling: Automatically increase or decrease the number of pods based on real-time CPU or memory usage.
Vertical Pod Autoscaling: Dynamically adjust CPU and memory requests for running pods according to actual usage patterns.
Resource Quotas: Set caps on total CPU, memory, and other resources per namespace to ensure fair allocation across teams and workloads.
Node Selectors & Affinity Rules: Schedule pods to specific nodes using labels, with options for co-location or separation based on workload needs.
Persistent Storage: Use Persistent Volumes (PV) and Persistent Volume Claims (PVC) to provide reliable, long-term storage for application data.
8. Kubernetes Deployment
Deploy LLM using Kubectl to apply Kubernetes configuration files. Ensure everything goes as planned by closely monitoring the deployment process.
Apply Network Policies: Control traffic flow within the cluster to safeguard LLM workloads.
Enforce Workload Isolation: Separate components so only authorized traffic occurs between pods.
Use Encrypted Communication: Protect in-transit data between the LLM and external systems with TLS or similar protocols.
Configure RBAC: Define roles and permissions to restrict resource access and actions to authorized users only.
9. Scale & Monitor
Track resource usage and performance metrics using tools like Prometheus and Grafana.
Scale Resources Dynamically: Modify pod counts and resource allocations according to insights to manage fluctuating workloads.
Implement Backup & Recovery: Establish reliable processes to safeguard data and enable fast restoration after failures.
Audit Access Logs: Continuously examine logs to identify and respond to suspicious or unauthorized activity.
10. Optimize
Ensure effective and efficient operation of LLMs with timely resource and performance optimization.
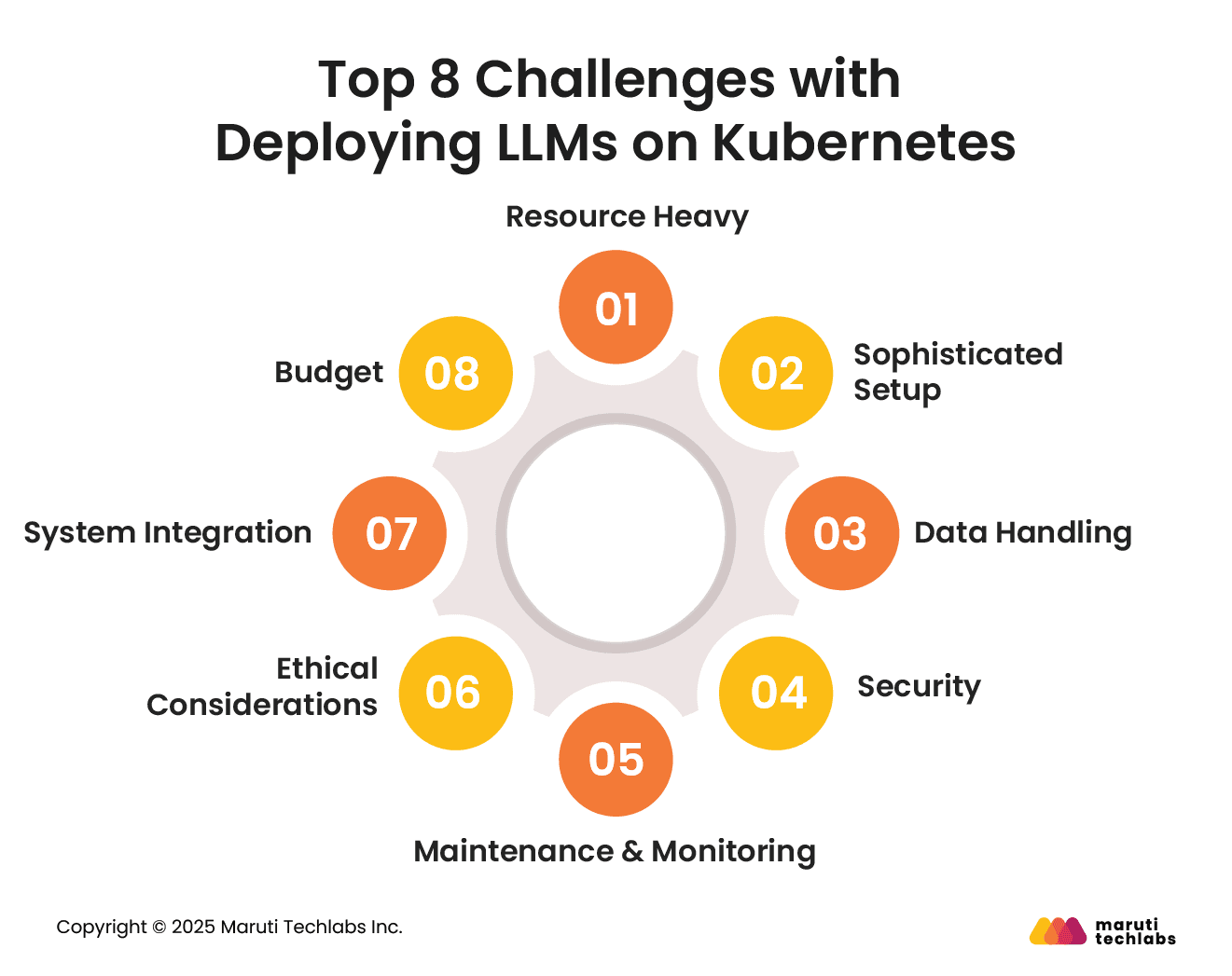
Top 8 Challenges with Deploying LLMs on Kubernetes
Deploying LLMs on Kubernetes presents unique challenges, including resource bottlenecks and scaling complexities, which teams must address to ensure reliable performance.
Here are the challenges and limitations one would face while deploying LLM on Kubernetes.
1. Resource Heavy
LLMs demand extensive computing resources, such as high CPU and GPU usage. It’s challenging to have adequate resources to handle these demands with a Kubernetes cluster.
2. Sophisticated Setup
Defining resource requests and limits, implementing auto-scaling, and establishing network governance policies are among the complex configurations required when deploying Kubernetes for LLM.
3. Data Handling
Training and inference activities for LLMs require large datasets. Managing these datasets, storage, and transfer is critical to ensure smooth operations.
4. Security
To ensure LLMs offer maximum security, it is important to comply with regulations such as HIPAA or GDPR and protect sensitive data. Security measures like access control and encryption should also be implemented.
5. Maintenance & Monitoring
Continual maintenance and monitoring are key factors to help your LLM function efficiently. This involves model updation, mitigating failures, and observing performance metrics.
6. Ethical Considerations
If your training data is biased or inaccurate, it can reflect in your LLMs, raising ethical concerns. A primary challenge with any LLM is mitigating biases and ensuring fairness.
7. System Integration
A complex process that requires precise planning and thoughtful execution is integrating your current or legacy systems with LLMs.
8. Budget
The resource-intensive process and need for specialized hardware can surge development costs beyond your expectations. It’s recommended that your organization perform an end-to-end AI readiness audit before commencing LLM development.
Conclusion
Kubernetes has emerged as a game-changer for Large Language Model (LLM) deployments, offering unmatched scalability, resource management, and security. Its ability to support both scale-up and scale-out architectures, integrate seamlessly with AI frameworks, and unify diverse infrastructure makes it the ideal choice for handling the complex demands of LLM training and inference.
As organizations scale Generative AI workloads, Kubernetes further enhances operations with built-in observability, automation, and multi-tenancy capabilities. This ensures efficient, cost-effective, and secure environments, empowering teams to innovate faster while maintaining control over resources.
If you’re looking to maximize the potential of your AI initiatives, Maruti Techlabs can help you design, deploy, and scale LLM workloads on Kubernetes for optimal performance and ROI.
Explore our Artificial Intelligence Services to learn more about what AI solutions our experts can design that cater to your business needs and future goals. Connect with us today and discover where you can leverage AI in your business workflows.
Pinakin Ariwala has over 20 years of experience in AI/ML, data engineering, and software development. He has led AI and machine learning projects across industries, including agriculture, finance, and healthcare, and has been featured on the Clutch Leaders Matrix podcast discussing real-world AI/ML applications.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!