Learn tactics that can help you select the perfect LLM from the numerous options in 2026.
Artificial Intelligence and Machine Learning
How to Choose the Right LLM in 2026?
Learn tactics that can help you select the perfect LLM from the numerous options in 2026.
Table of contents
Table of contents
Introduction
Evaluation Metrics for Code Generation LLMs
7 Best LLMs for Coding in 2026
5 Essential Steps to Select an LLM Framework
How Do You Pilot & Evaluate LLMs Internally?
Conclusion
FAQs
Introduction
Choosing the right large language model in 2025 feels like navigating a vast, ever-expanding galaxy. You're surrounded by countless powerful open-source models available on platforms like Hugging Face alongside an intense, behind-the-scenes race among AI giants to push the limits of scale and capability.
The result? An array of choices that vary widely in strengths, trade-offs, and costs. This brief guide cuts through the noise. It covers important aspects related to LLM model selection, like essential steps, internal evaluation, and the top LLMs to look out for in 2024.
Evaluation Metrics for Code Generation LLMs
Before you choose the models, it’s essential to decide on metrics relevant to developers. A code generative LLM's performance can’t be agreed on one benchmark score, such as HumanEval. So, it demands a holistic evaluation that includes:
1. Architecture: Mixture-of-Experts (MoE) vs Decoder-only transformers and how it affects inference cost and parallelism.
2. Instruction Mapping: The model’s ability to follow multi-step instructions and maintain chronology with specific constraints.
3. Training Datasets: Availability of premium open-source repositories, test cases, README files, and real-world documentation.
4. Language Support: The different languages LLM supports, such as Go, Python, JavaScript, Rust, Java, and domain-specific languages such as YAML or Terraform.
5. Context Window Length: Capability to analyze multi-file projects, extensive configuration files, or interconnected code logic.
6. Tool Integrations: Cursor IDE, JetBrains, CLI tooling compatibility, and plugin availability for VS Code.
7. Inference Latency: Real-world usability inside editors or during CI/CD operations.
8. Benchmarks: MBPP, HumanEval, and CodeContests benchmarks for comparing reasoning, syntax, and task completion.
9. Licences & Cost: Token pricing, model availability via APIs or downloadable weights, and open source vs commercial licenses.
10. Extensibility: Prompt engineering flexibility, fine-tuning support, and compatibility with orchestration layers like LlamaIndex, GoCodeo, and Langchain.
7 Best LLMs for Coding in 2026
With rapid advancements in AI, large language models are becoming indispensable for developers, streamlining coding, debugging, and even automating workflows. Here are the top LLMs that you should keep an eye out for in 2025.
1. GPT-4.5 Code Interpreter (OpenAI)
GPT is a proprietary transformer-based model with instructions tuned for multi-modal tasks, including code generation, refactoring, and debugging. GPT 4.5 is currently the most acclaimed AI platform for multi-language and multi-domain reasoning.
It’s adept at handling deeply nested dependency graphs, facilitating high-fidelity completions across modern frameworks like React, Prisma, & Express. The platform is performant with long-context scenarios when clubbed with agents that can chain intelligent prompts.
2. Bidirectional Encoder Representations from Transformers (BERT) by Google
BERT is renowned for its ability to understand bidirectional context and produce adequate output for numerous NLP tasks, including language understanding and text classification.
3. Claude 3 Opus (Anthropic)
Claude 3 works on a constitutional transformer architecture offering long-term memory, multi-turn consistency, and safety. It supports languages such as Rust, Go, Python, JavaScript, C, Kotlin, and more with over 2000 tokens.
This extensive support makes the platform perfect for documentation-linked logic and cross-file reasoning. Claude 3 is proficient with scenarios that demand explainability.
For instance, if you want to generate changes for a regulatory-compliant backend, the platform offers contextual justifications with the code. It’s the perfect fit for sectors needing traceability.
4. Code Llama 70B (Meta)
Code Llama is fine-tuned for code generation with a permissive license using a decoder-only open-source transformer. It offers language support for Java, Bash, Python, JavaScript, and more, with over 100,000 tokens that provide architecture-level patching.
Code Llama is an excellent platform for companies requiring complete control. Unlike GPT-4.5, Code Llama isn’t syntactically perfect but integrates seamlessly with vLLM, TGI, or Llama.cpp. Additionally, it can be fine-tuned for company codebases, providing consistent output for internal libraries, APIs, and design systems.
5. DeepSeek-Coder V2
DeepSeek is an instruction-tuned platform trained on high-quality code and documentation using 2T+ tokens. It supports over 80 languages, including platforms like Terraform, Ansible, VHDL, and more.
DeepSeek addresses the needs of commercial models and raw open-source systems. It can work across backend, DevOps, and blockchain domains within a single interface, thanks to its multilingual functionality. DeepSeek can also plug directly into testing or deployment workflows with its structured response formats.
6. Phind-CodeLlama-34B-Instruct
Phind-CodeLlama is an instruction-tuned open-weight LLM variant of Code Llama. With support for languages like Python, C++, and more, it offers a context window of 32K-65K, depending on the interface engine.
If you’re a software engineer interacting in chat-driven environments, Phind is what you should opt for. Additionally, it possesses conversational capabilities with structured code generation, which is ideal for CLI bots or VS Code extensions.
7. Gemini Code Assist (Google)
Gemini is a renowned AI tool from Google that enhances developer productivity across the Google Cloud Platform and Android Studio. It offers language support for SQL, Kotlin, Python, Dart, and more.
If you’re working within the GCP + Android ecosystem, Gemini offers various valuable functionalities. It can produce frontend templates and consistent infrastructure code using assets such as design mockups, deployment configurations, and environment variables.
5 Essential Steps to Select an LLM Framework
Here are five quick steps that you should follow to select the perfect LLM framework aligning with your business needs.
Step 1: Define Tasks for LLM
Defining task requirements is the primary step when starting your selection process for an LLM framework. This requires you to learn the task you want to perform, such as document analysis, chatbot conversations, summarization, or Q&A.
Your next job is to assess the complexity level, starting from standard responses, to intermediate tasks like calculations, to advanced tasks like contract analysis. In addition, it’s essential to specify the data type that the LLM will process, whether it supports texts, texts with images, or multi-modal inputs combining text, audio, and pictures.
Step 2: Map Relevant Benchmarks for Use Cases
The second step in selecting an LLM framework is to evaluate benchmarks. They provide an objective way to compare models based on task-specific strengths.
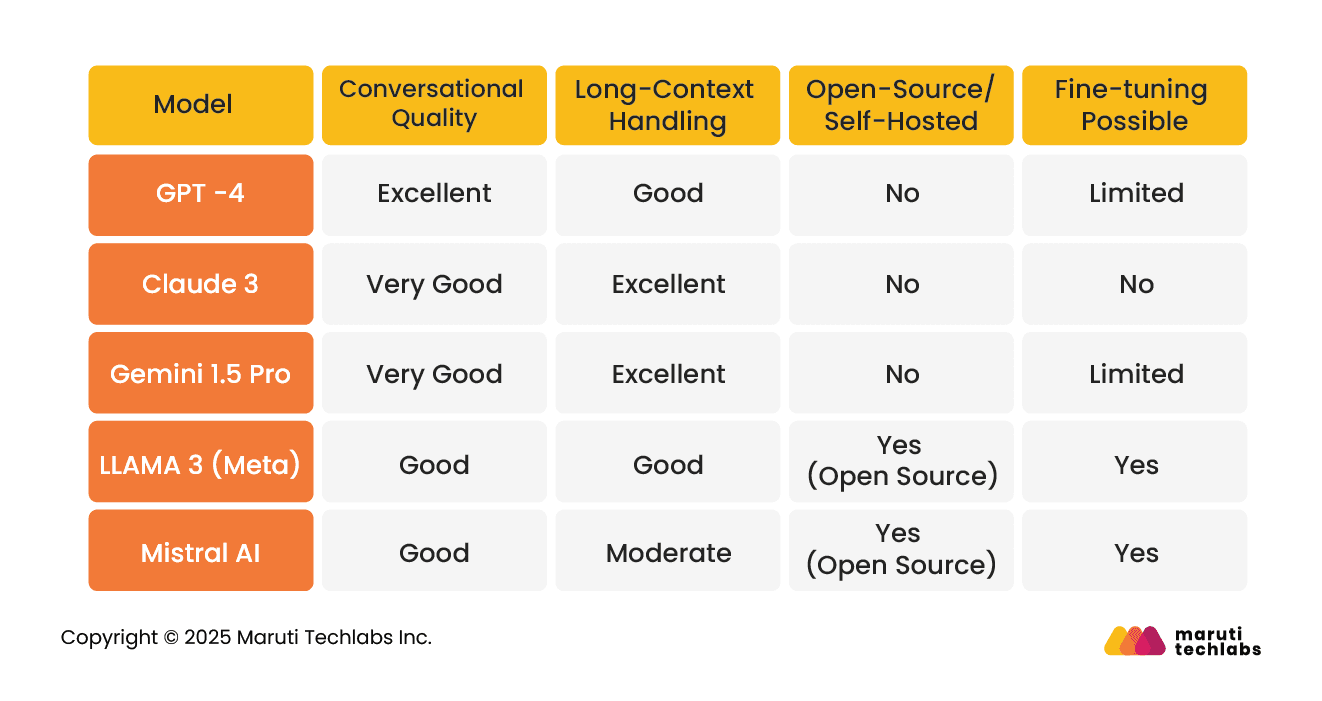
Different benchmarks emphasize various capabilities, making it important to align them with the chatbot’s needs. For an insurance chatbot, the key focus should be on general knowledge (MMLU), conversational quality (MT-Bench), and long-context understanding (LongBench).
Benchmarks are crucial because no single model excels at everything. For instance, GPT-4 demonstrates strong reasoning and coding ability, Claude 3 is highly effective at handling long-context document reading, and LLAMA 3 can deliver strong results if fine-tuned for domain-specific use cases.
Step 3: Use Benchmark Performance to Shortlist Models
Here’s how you can analyze models based on their performance across tasks:
Step 4: Evaluate Factors Beyond Performance
Here are a few aspects to keep in mind that go beyond the performance of your model.
Data Privacy & Regulatory Compliance: A critical aspect for organizations offering insurance, banking, healthcare, and legal services.
Cost Efficiency: Do you prefer self-hosted pricing or API-based (pay-per-use).
Customization: Does an out-of-the-box model suffice your needs, or does it require domain-specific fine-tuning?
Multimodal Support: Evaluate if this is a current requirement or a futuristic one?
Latency & Speed: Does your service need quick/instant replies or can it tolerate slight delays?
Step 5: Use Decision Matrix
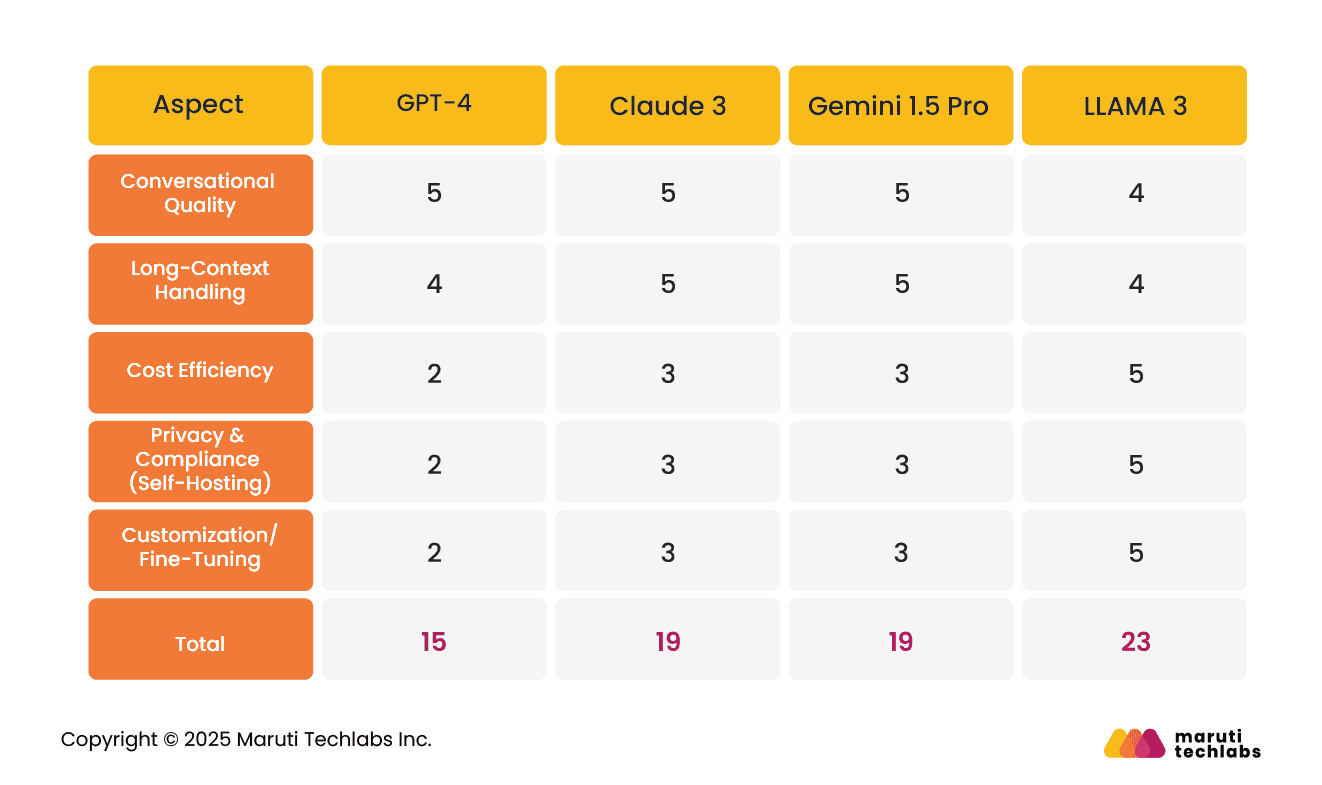
Rate all models on a scale of 1-5 for different factors, like below.
Here’s a highlight of the scorecard
Claude 3: Great conversation quality, document reading, but API-based and higher cost.
LLAMA 3: Best balance of cost, privacy, and customization (self-hosted).
It’s suggested that one not only leverages on-paper research but also uses real data to come to a decision. Here is what you can do to measure real-time data.
Have a list of 20-30 sample queries/tasks.
Measure:
Response accuracy
Answering speed
Edge case handling
Current tech stack integration
Make your final decision by examining results from your real-time scenarios, and not only benchmark papers.
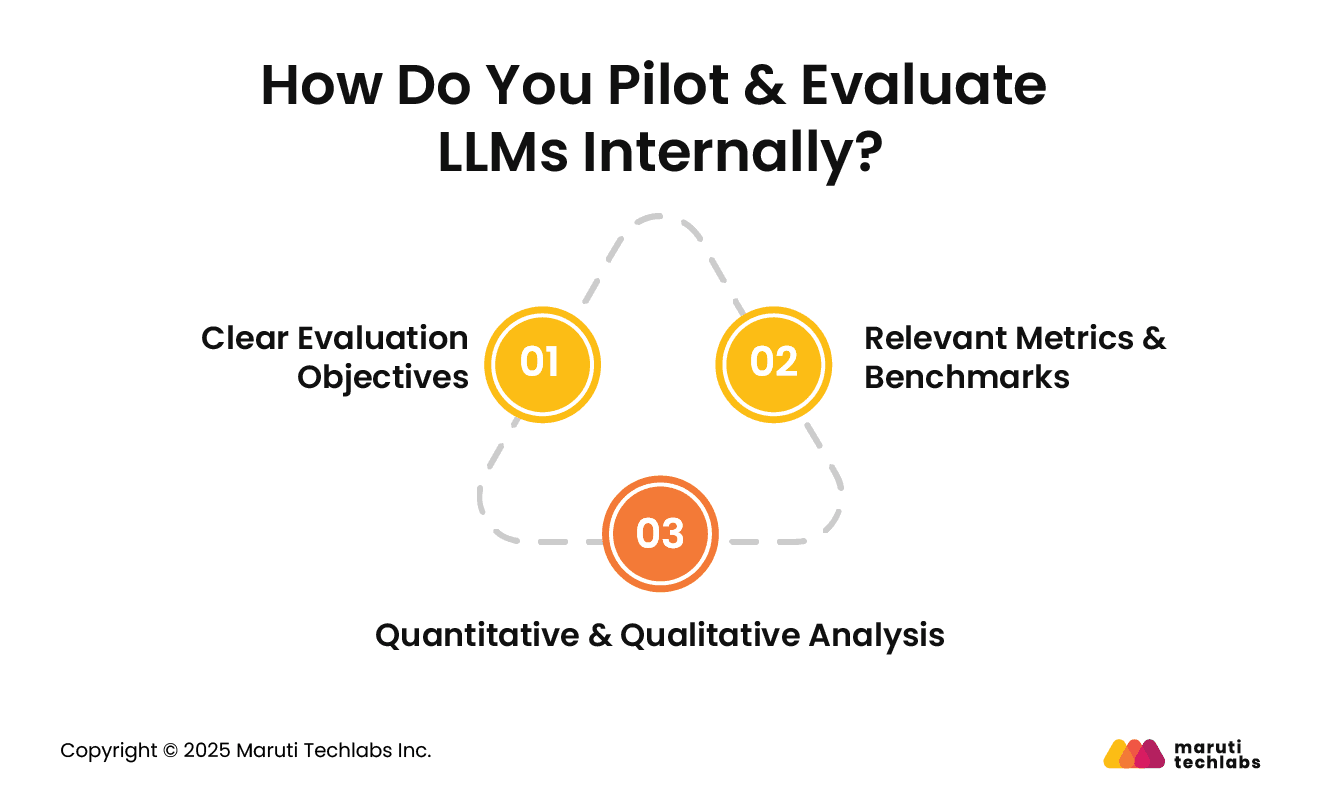
How Do You Pilot & Evaluate LLMs Internally?
The assessment of the performance and utility of LLMs can only be done using evaluation protocols. These protocols should encompass both human and automated evaluations, various benchmarks, and ethical considerations.
Here are the key considerations that you must include.
1. Clear Evaluation Objectives
Whether your intended use case is translation, summarization, or text generation, your evaluation objectives should align with it. The evaluation metrics should be selected based on your goals.
It’s only then that you can learn a model’s performance in relevant areas. It helps examine a model’s strengths and weaknesses, suggesting further improvements.
2. Relevant Metrics & Benchmarks
The chosen metrics should offer a holistic view of the model’s performance. The precision, recall, and F1 score can calculate accuracy, while ROUGE and BLEU assess the quality of text generated. The choice of metrics and benchmarks has a high influence on the outcome and subsequent fine-tuning.
3. Quantitative & Qualitative Analysis
Using automated metrics, quantitative analysis may offer a measure of the model’s performance, but it can miss the nuances across tasks. This must be complemented using quality human analysis that assesses criterias like relevance, coherence, and fluency of the output.
This balance ensures a comprehensive analysis of the model’s limitations and capabilities. The model is not only statistically performant but also creates superior-quality, meaningful outputs.
Latest Developments in LLM Evaluation
Natural Language Generation (NLG) experts work on evaluation frameworks that offer a reliable assessment of LLMs. Here are some of the latest developments in this field:
1. Werewolf Arena
Introduced by Google, this framework uses the game ‘Werewolf’ to evaluate LLMs considering their abilities for reasoning, deception, and communication. It leverages dynamic turn-taking, where models await their chance to speak, like real-world conversational dynamics.
Models like Gemini and GPT were tested, revealing notable differences in their strategic and communicative approaches. This method of evaluation offers a mix of interactive and challenging benchmarks perfect for assessing the social reasoning capabilities of an LLM.
2. G-Eval
Known by the name GPT-Eval, this is a one-of-a-kind framework that uses existing LLMs like GPT-4 to assess the quality of texts generated by NLGs. This method emphasizes enhancing human alignment by evaluating the quality of generated text outputs.
Using a chain-of-thought approach and form-filling paradigm, G-Eval offers an accurate evaluation of LLM outputs. In experiments with tasks like text summarization and dialogue generation, G-Eval using GPT-4 showed a strong link to human judgments, with a Spearman correlation score of 0.514. This is much better than earlier evaluation methods. Spearman’s correlation ranges from -1 (a strong negative link) to +1 (a strong positive link).
Conclusion
Choosing the right LLM in 2025 depends on clearly defining your task, aligning with relevant benchmarks, and understanding each model’s unique strengths. Whether it’s handling FAQs, managing long policy documents, or providing conversational support, the right framework ensures both accuracy and efficiency.
No single model is best for every use case. GPT-4 excels in reasoning, Claude 3 in long-context analysis, and LLAMA 3 in domain fine-tuning. The key is matching your business needs with the model’s strengths. As you plan your AI strategy, incorporating Generative AI solutions can help accelerate experimentation, improve performance, and enable scalable adoption.Start small, test across benchmarks, and fine-tune for your domain.
Our expert Artificial Intelligence Consultants can offer you the perfect evaluation of the numerous LLMs present in the market that blend well with your business needs.
Ready to explore which LLM can elevate your operations in 2025?
To understand your organization’s current AI maturity and prepare for smooth LLM adoption, try our AI Readiness Calculator and take the first step toward an effective AI strategy.
FAQs
1. Which LLM optimization service is best for AI products?
The best optimization service depends on your product’s goals, but services like OpenAI’s fine-tuning API, Anthropic’s domain adaptation tools, or Hugging Face AutoTrain stand out. They help customize models for efficiency, cost, and accuracy while ensuring scalability, making them ideal for production-ready AI solutions.
2. Which LLM is best for coding?
Currently, GPT-4 and Claude 3 Opus are highly effective for reasoning-heavy coding tasks, while Code Llama and DeepSeek Coder perform exceptionally well in open-source environments. If domain-specific coding support and fine-tuning flexibility are priorities, Code Llama offers a strong balance between performance, adaptability, and cost-effectiveness.
3. Which LLM security tool is best?
For securing LLM applications, Guardrails AI, LlamaGuard, and Protect AI’s offerings are leading tools. They help enforce content filters, prevent prompt injection, and monitor for data leakage. Choosing the best depends on compliance needs, integration flexibility, and risk management priorities within your AI product’s lifecycle.
4. What are the best practices for fine-tuning LLMs?
Fine-tuning works best with high-quality, domain-specific data, careful prompt engineering, and validation against benchmarks. Always start with smaller models to reduce cost, monitor for overfitting, and use techniques like LoRA (Low-Rank Adaptation) for efficiency. Regular human-in-the-loop evaluations ensure accuracy, safety, and alignment with evolving requirements.
Pinakin Ariwala has over 20 years of experience in AI/ML, data engineering, and software development. He has led AI and machine learning projects across industries, including agriculture, finance, and healthcare, and has been featured on the Clutch Leaders Matrix podcast discussing real-world AI/ML applications.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!