Avoid These 15 AI Training Pitfalls for Better Accuracy
Discover 15 frequent AI training mistakes and simple ways to prevent them for better results.
Artificial Intelligence and Machine Learning
Avoid These 15 AI Training Pitfalls for Better Accuracy
Discover 15 frequent AI training mistakes and simple ways to prevent them for better results.
Table of contents
Table of contents
Introduction
What is AI Model Training?
Why AI Models Are Valuable for Enterprises
How to Train an AI Model
15 Common AI Model Training Mistakes and How to Fix Them
Conclusion
Introduction
Studies show that 70% of companies see little to no impact from AI, and 87% of data science projects never make it to production. Even as AI adoption grows, many businesses still struggle to move from a proof-of-concept to a working, production-ready solution. The problem often isn’t the technology itself, but the approach to training AI models.
Training an AI model is more than just feeding it data and expecting accurate results. It’s the process where the system learns, adapts, and improves, but only if done right. Small mistakes during training can snowball into big problems, leading to wrong predictions, unreliable results, and wasted time and money.
Many companies rush through this stage to achieve quick results, often skipping key steps such as data cleaning, selecting appropriate checks, or fine-tuning the model, which can lead to models that fail in real-world use.
In this article, we’ll look at the most common mistakes businesses make when training AI models and how you can avoid them. The goal is to help you build models that are not just accurate in theory but effective, scalable, and reliable in practice.
What is AI Model Training?
AI model training is the process of teaching a system how to make accurate predictions or decisions based on data. It’s an iterative process, meaning it happens in repeated cycles like feed data, check results, make improvements, and repeat. The success of training depends heavily on two things: the quality of the data and the method used to train the model.
In most cases, data scientists lead the process, but with the rise of low-code and no-code tools, even business teams can take part. The goal is to create a mathematical model that can handle a wide range of real-world situations, including unusual patterns, errors, or incomplete information.
Training starts with selecting the right algorithm and preparing the initial dataset. The model uses this data to learn patterns and relationships. Once the first version is ready, its output is tested to measure accuracy. If the results are off, adjustments, known as fine-tuning, are made. This may involve adding more data, balancing the dataset, or tweaking algorithm settings.
Over time, the model is trained on new and more diverse data, enabling continuous learning and improvement. This ensures the AI not only performs well in test environments but also adapts effectively to real-world scenarios it has not previously encountered.
Training a model isn’t a one-time process but a continuous one that shapes how well the AI performs in the future. Using quality data, thorough testing, and regular updates keeps it reliable and ready for new challenges.
Why AI Models Are Valuable for Enterprises
AI helps businesses work smarter by automating routine tasks and uncovering insights that might otherwise be missed. It can process vast amounts of data quickly, highlight unusual patterns, and turn unstructured information, such as scanned documents or receipts, into usable records.
When trained well, AI models deliver both short- and long-term value. In the short term, they can speed up processes and free teams to focus on higher-impact work. Over time, they can reveal hidden trends, support better decision-making, and even open doors to new products or services.
Data is at the heart of every organization, flowing in from operations, sales, marketing, and more. AI uses this data to support decisions across almost any business area. For example, in manufacturing, a trained AI model could forecast shipping times, predict defects, suggest pricing changes, and optimize supply chains.
The real value comes from proper training and application. This means knowing the problem you want to solve, having reliable data sources, and ensuring the right infrastructure is in place. With those elements, AI models can become a trusted tool, helping enterprises turn everyday data into lasting business value.
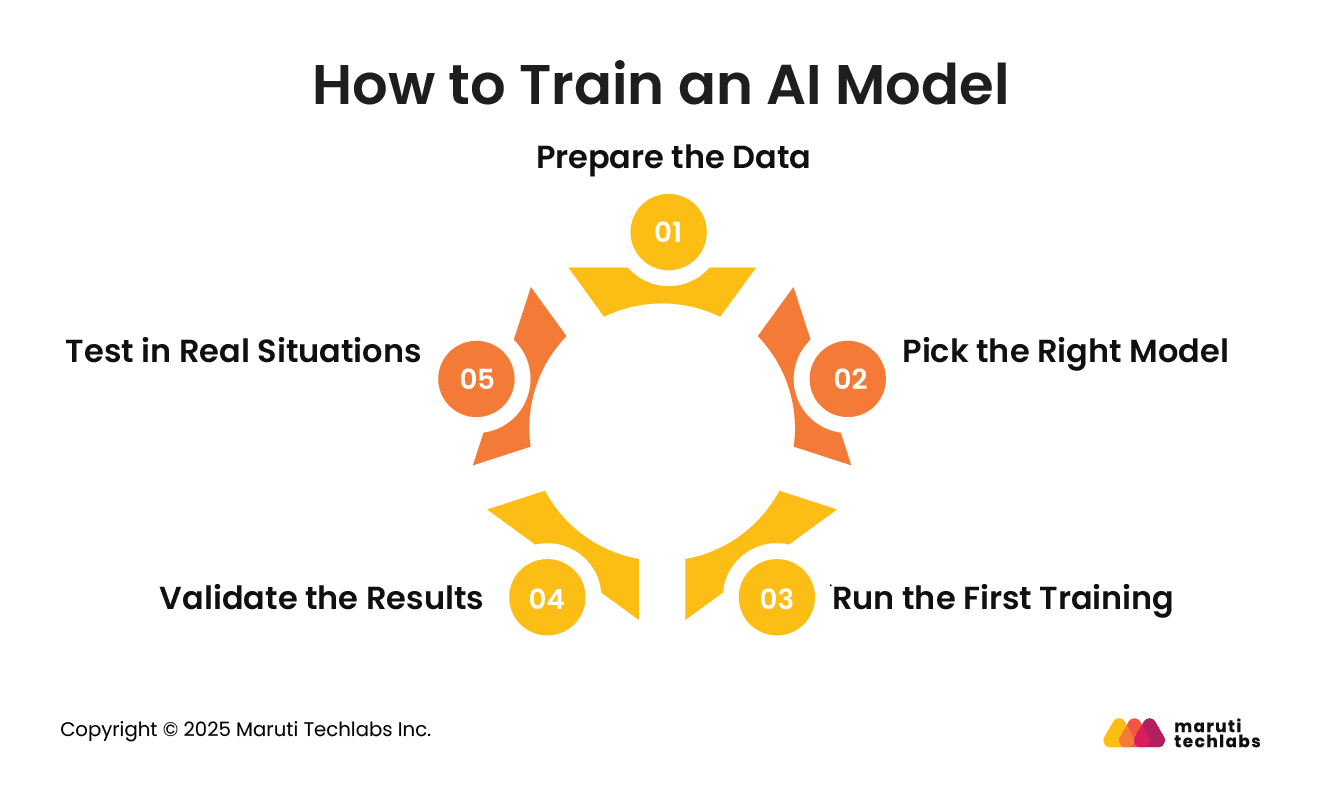
How to Train an AI Model
Training an AI model involves following the right steps to ensure it remains accurate and performs well in real-world situations. Here’s how to go about it:
1. Prepare the Data
Start by collecting data that reflects real-life scenarios. Clean it up, remove errors, and make sure it’s consistent before you move ahead.
2. Pick the Right Model
Choose a model and algorithm that match your goals. Consider what you want it to achieve, how complex it should be, and the resources you have.
3. Run the First Training
Begin simple. Teach the model the key patterns you want it to learn before adding complexity. Check if it’s giving reasonable results.
4. Validate the Results
Test the model on new data it hasn’t seen before. This helps you see if it can handle fresh information and make accurate predictions.
5. Test in Real Situations
Try it with real-world data. If it meets your accuracy standards, it’s ready. If not, tweak and train again until it performs reliably.
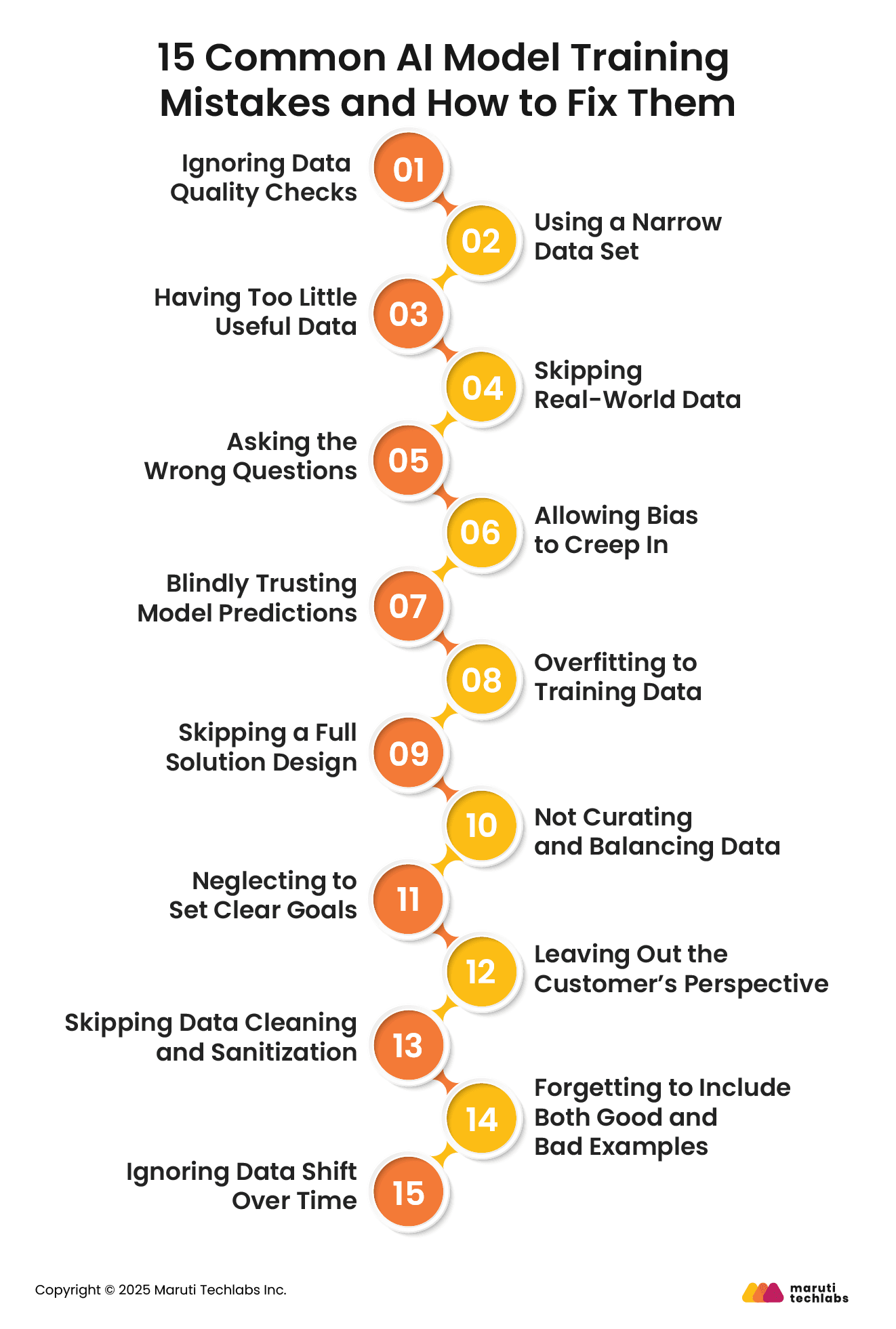
15 Common AI Model Training Mistakes and How to Fix Them
Training an AI model is not just about giving it data to learn from. Even small mistakes can lead to the model providing incorrect answers, wasting time, or failing in real-life applications. The good news is that many of these mistakes can be avoided if you know what to watch for.
Below are 15 common mistakes made during AI training and simple ways to fix them.
1. Ignoring Data Quality Checks
Bad data can easily confuse your AI model and make it less accurate. Ensuring data is complete, accurate, and relevant is essential, with both automated tools and manual checks used to eliminate errors.
2. Using a Narrow Data Set
If data is limited to a single scenario or group, the AI will face challenges in handling other situations. Gathering examples from diverse sources and conditions makes the model more robust and adaptable.
3. Having Too Little Useful Data
Data quantity alone is not sufficient. Each category or behavior that the model must learn should be well represented. Gaps can be addressed by generating synthetic data or acquiring additional samples.
4. Skipping Real-World Data
Training only on test or lab data can make your AI unrealistic. Include real customer data, appropriately anonymized, so your model learns from actual behavior patterns.
5. Asking the Wrong Questions
A model that solves the wrong problem delivers no value. Rigorously define the prediction or classification objective before development begins.
6. Allowing Bias to Creep In
If your training data is biased, your AI might make unfair or wrong predictions. Check your data for missing groups or uneven results, and fix the balance before you start training.
7. Blindly Trusting Model Predictions
AI may not always be right. Cross-check predictions with human review, especially during early deployment, to spot where the model might be making mistakes.
8. Overfitting to Training Data
If a model performs perfectly on training data but poorly on new data, it’s overfitting. Use techniques like cross-validation and dropout layers to improve generalization.
9. Skipping a Full Solution Design
An AI model is just one part of a larger system. Plan how it will integrate with data pipelines, applications, and business processes to ensure it delivers real value.
10. Not Curating and Balancing Data
Raw data isn’t always training-ready. Balance the dataset so no single outcome is overrepresented, and ensure each class has enough examples to be learned effectively.
11. Neglecting to Set Clear Goals
Without defined objectives, you can’t measure success. Set measurable performance metrics—like accuracy, recall, or precision—before you begin training.
12. Leaving Out the Customer’s Perspective
AI that ignores user needs can fail in practice. Include customer feedback and use cases when deciding how to train and evaluate the model.
13. Skipping Data Cleaning and Sanitization
Unclean data can introduce noise and errors. Remove duplicates, fix formatting issues, and anonymize sensitive information before using it for training.
14. Forgetting to Include Both Good and Bad Examples
If you only train AI with perfect cases, it won’t know how to deal with mistakes. Provide examples of both successes and failures to ensure it can handle all situations.
15. Ignoring Data Shift Over Time
Data changes as things change in the real world. If your model learns from old data, it might give wrong results later. Keep checking your data and retrain it as needed.
Avoiding these common mistakes can save time, money, and frustration in AI development. By focusing on quality data, realistic scenarios, clear objectives, and continuous updates, you give your AI the best chance to perform well in real-world situations.
Conclusion
AI is powerful, but it is not magic. Poor training practices can lead to disappointing or even harmful outcomes. The advantage is that many of these issues can be avoided with careful planning and continuous improvement.
Start by clearly defining the objectives for the AI system. Ensure data is clean, complete, and balanced, incorporating both positive and negative examples to prepare the model for real-world scenarios. Monitor for bias and shifts in data patterns, and retrain regularly to maintain accuracy.
AI success depends not only on technology but also on the alignment of people, processes, and goals. When teams understand the purpose of AI, how it functions, and how to maintain it, outcomes become more consistent and reliable.
AI should be treated as a tool that delivers the best results when managed carefully. Training must be viewed as a continuous process rather than a one-time effort. Incorporating Custom AI Development practices, testing in real-world conditions, gathering user feedback, and ongoing refinement ensure the AI remains effective, relevant, and trustworthy over time.
If you want to avoid these common training mistakes and build AI models that deliver results, our team at Maruti Techlabs can help. Explore our AI services or contact us today to discuss how we can bring your AI ideas to life.
Pinakin Ariwala has over 20 years of experience in AI/ML, data engineering, and software development. He has led AI and machine learning projects across industries, including agriculture, finance, and healthcare, and has been featured on the Clutch Leaders Matrix podcast discussing real-world AI/ML applications.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!