Generative AI workloads are exploding from LLMs to image synthesis, driving up cloud usage as organizations train and serve massive models with soaring compute demands.
Traditional security models, however, struggle to keep pace. They were built for static applications, not dynamically evolving AI systems that constantly retrain and adapt. In such environments, old-school defenses fail to address data drift, model retraining risks, or the shared responsibility between data science and operations.
In this blog, we’ll explore the purpose of the MLOps maturity framework, how to evaluate your current MLOps capabilities, identify key barriers, and essential tools that can help you scale safely and reliably.
What is MLOps Maturity?
MLOps Maturity assesses the quality of the capabilities people, processes, and technology possess for deploying and monitoring ML applications in production.
Purpose of MLOps Maturity Frameworks
MLOps maturity frameworks serve as strategic blueprints that help organizations move from chaotic, manual ML practices to robust, automated, and scalable operations.
Many organizations follow a unified, vendor-agnostic model to assess their maturity across people, processes, and technology, enabling leaders to benchmark their current state and plan a structured roadmap.
Maturity models also standardize the MLOps lifecycle and clarify the roles, tools, and costs associated with each level.
By defining maturity stages, organizations can align their organizational capabilities, skill investments, and infrastructure to ensure reliable, reproducible, and cost-effective ML deployments, avoiding rework, misalignment, and wasted effort.
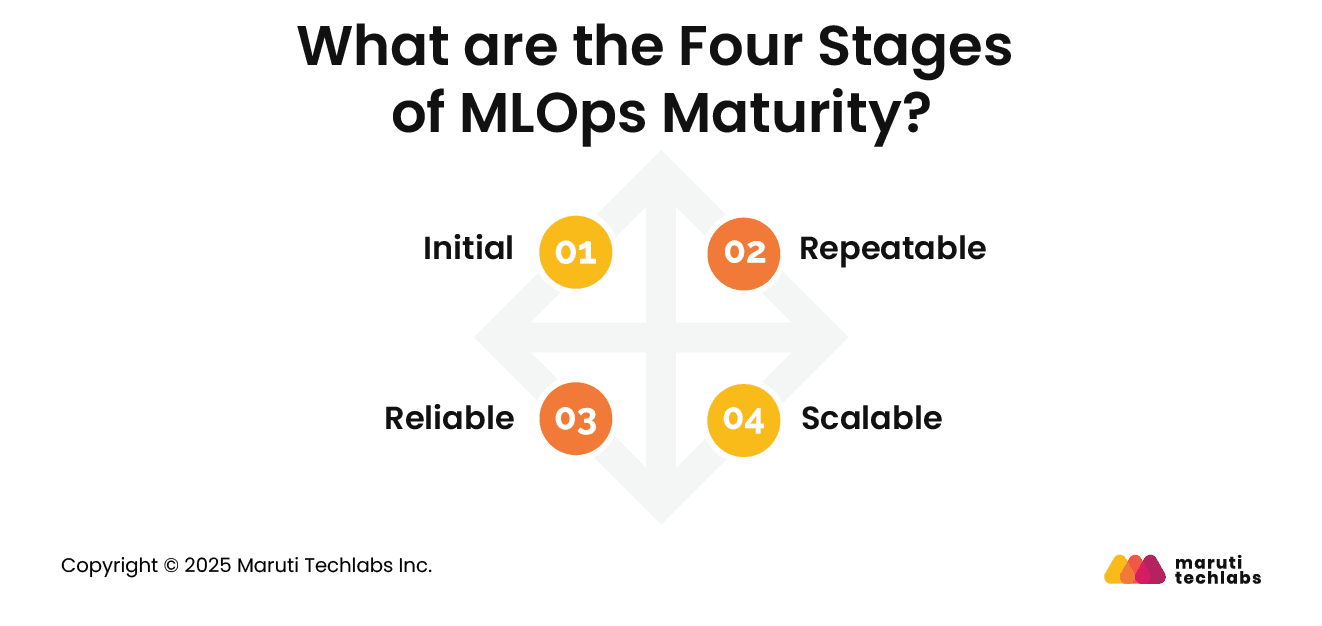
What are the Four Stages of MLOps Maturity?
MLOps usually develop in steps, and each stage shows how well a team can build and run ML models in real workflows. Let’s explore the four main stages of MLOps maturity.
1. Initial
Teams work in silos with limited collaboration between data scientists and engineers.
Infrastructure is minimal, often relying on local machines or small cloud setups.
Tooling is fragmented, focusing on individual ML steps without interoperability.
Experiments succeed independently but lack consistent deployment processes.
2. Repeatable
Version control enables structured code management and team collaboration.
Early automation reduces manual work for routine tasks such as data preparation.
Knowledge from past projects begins to be documented and shared.
Standardized workflows emerge, forming basic pipelines for training and deployment.
3. Reliable
CI and CD pipelines are fully implemented for predictable, fast releases.
Monitoring and alerting systems track model health and detect issues in real time.
Governance practices strengthen compliance, privacy, and security controls.
Automated retraining and reduced manual intervention increase operational stability.
4. Scalable
Cloud infrastructure supports scaling models and workloads across teams and projects.
Advanced data management systems, such as data lakes or warehouses, handle growing data volumes.
Microservices architecture enables modular ML components that scale independently.
AI becomes integrated into enterprise operations with policies, standards, and cross-business adoption.
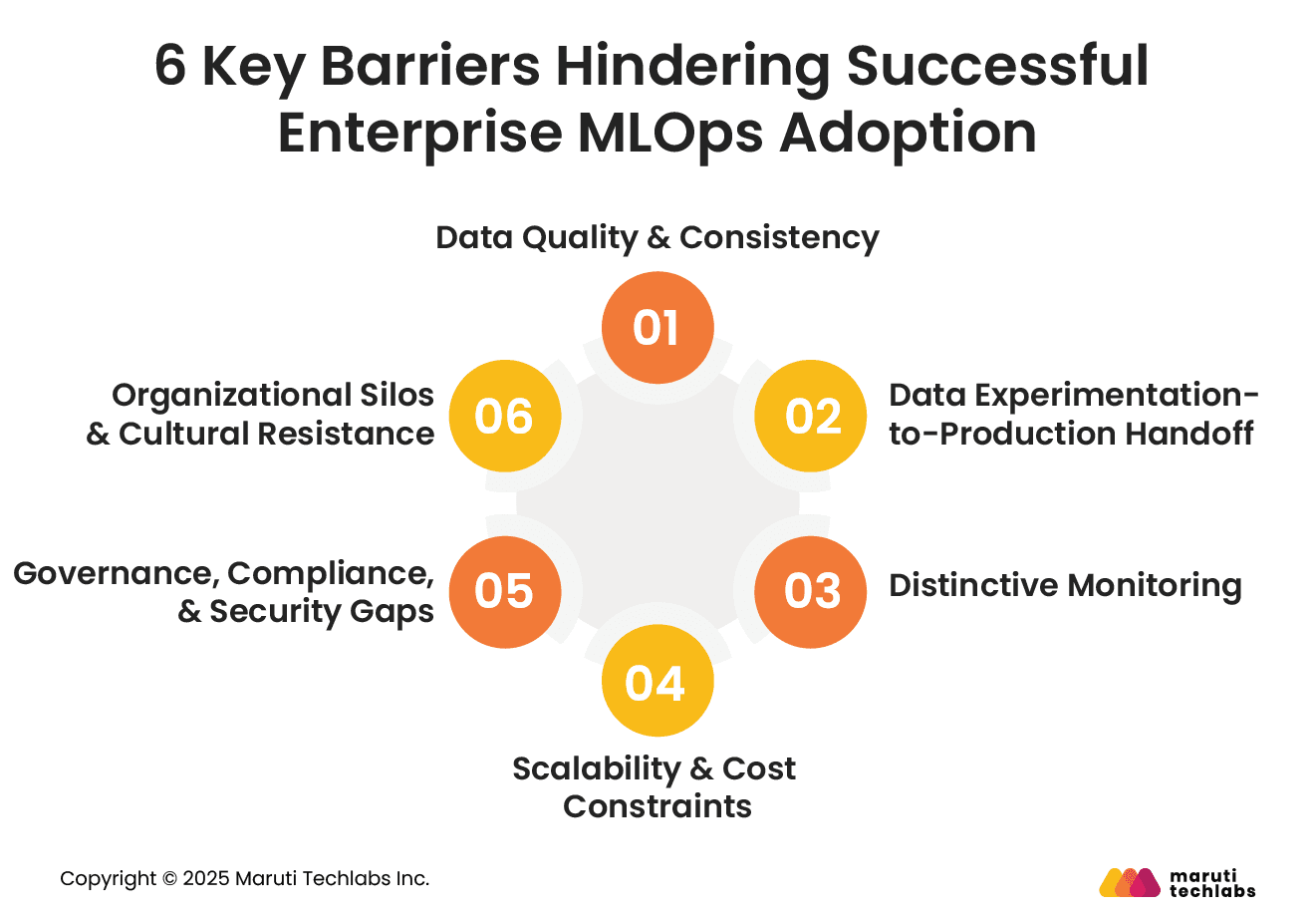
Many enterprises struggle to scale MLOps due to recurring obstacles that slow progress and limit real-world impact. Here is a list of the critical challenges organizations face in adopting MLOps.
1. Data Quality & Consistency
Enterprises struggle with inconsistent, incomplete, and low-trust data that directly impacts model reliability. Missing values, formatting inconsistencies, and duplicates often lead to unpredictable model behavior.
As data distributions shift due to changing customer patterns or external conditions, models degrade silently. Handling both batch and real-time data pipelines further increases complexity, requiring more mature data engineering foundations.
2. Data Experimentation-to-Production Handoff
Data scientists often build prototypes in isolated notebook environments, while production systems demand robust, scalable code, creating friction and long deployment delays.
Rewriting experimental code introduces bugs, and mismatches in environments create reproducibility issues. Tracking datasets, artifacts, and hyperparameters across versions adds complexity that traditional DevOps tools aren’t built to manage effectively.
3. Distinctive Monitoring
Model performance often degrades gradually due to data drift, feature shifts, or changes in user behavior, making issues hard to detect early.
Traditional monitoring focuses on infrastructure metrics, leaving ML-specific signals overlooked. Without automated retraining workflows, organizations rely on manual intervention, which increases downtime and reduces agility when conditions change.
4. Scalability & Cost Constraints
ML systems must handle fluctuating workloads, from sudden traffic spikes to GPU-heavy training cycles. Static provisioning often leads to over- or under-allocation of resources.
Supporting multi-cloud or hybrid environments adds operational overhead, particularly when models require specialized hardware or compliance-driven data locality constraints, making cost-efficient scaling a core challenge.
5. Governance, Compliance & Security Gaps
Regulations require traceability, explainability, and strict data-handling controls that many ML pipelines weren’t designed to support. Bias and fairness concerns add more pressure, especially in high-risk domains.
Meanwhile, adversarial attacks, data poisoning, and model theft expose security gaps, as traditional security practices rarely address ML-specific vulnerabilities.
6. Organizational Silos & Cultural Resistance
Misalignment between data science, engineering, and operations teams slows MLOps maturity. Each group prioritizes different metrics, creating fragmented workflows.
Skill gaps in ML engineering and MLOps tools further impede adoption. Long-established processes and tool preferences often fuel resistance, preventing organizations from shifting to collaborative, standardized ML operational practices.
10 Tools that Advance Your MLOps Maturity
As organizations advance in their MLOps journey, certain tools become essential for scaling workflows, improving reliability, and supporting mature production pipelines.
Specializes in real-time ML pipeline orchestration with ultra-low-latency inference.
Perfect for financial services and fraud detection workloads.
Achieves sub-millisecond serving performance.
Importance of MLOps Maturity Metrics and KPIs
Why It Matters?
MLOps metrics and KPIs serve as a compass for measuring progress throughout the MLOps lifecycle. They offer objective visibility into whether improvements in deployment speed, monitoring, automation, and data management are truly delivering value.
Without well-defined KPIs, organizations risk investing in tools and workflows without understanding their impact on performance, reliability, or business outcomes. Effective KPIs evolve with maturity and must align with organizational goals, not a one-size-fits-all approach.
Core Dimensions to Measure
1. People & Culture
This dimension tracks how teams adopt MLOps practices, collaborate, and embrace a data-driven mindset.
Metrics here assess alignment between data science and engineering, skill readiness, and the consistency of cross-functional workflows. Improving this dimension ensures teams can scale MLOps practices sustainably.
2. Process & Governance
This focuses on workflow standardization, reproducibility, compliance, and model lifecycle governance.
Measuring aspects such as documentation quality, approval workflows, and auditability helps determine whether processes are shifting from ad hoc to structured, enabling faster and safer deployments.
3. Technology & Automation
Technology metrics evaluate the maturity of infrastructure, deployment pipelines, observability, and automation.
These indicators reflect how efficiently the ecosystem supports experimentation, continuous delivery, monitoring, and automated retraining, key elements of advanced MLOps maturity.
Key Metrics & KPIs
At early maturity stages, KPIs establish baselines, such as the number of models in production, providing an initial view of the operational footprint. As organizations advance, metrics become more actionable.
Model deployment frequency and model accuracy on held-out datasets quantify CI/CD efficiency and model quality. At optimized stages, KPIs focus on automation and system robustness: time to detect model drift, infrastructure cost per model, and the number of models automatically retrained.
Business-level KPIs tie MLOps maturity to tangible outcomes, for instance, reduced fraud detection time in financial services or improved click-through rates in e-commerce, highlighting how strong MLOps practices directly translate to measurable business impact.
Key Takeaways
Generative AI growth demands modern MLOps practices that exceed traditional security and operations.
MLOps maturity frameworks guide organizations from chaotic experimentation to scalable, governed AI systems.
Advancing through maturity stages enhances collaboration, automation, monitoring, and enterprise-wide AI integration.
Key challenges include data quality, monitoring gaps, scalability constraints, governance issues, and cultural silos.
Metrics and KPIs ensure measurable progress across people, processes, and technology throughout the lifecycle.
Conclusion
AI and GenAI are expanding rapidly, and the ability to manage them efficiently is becoming a defining factor for enterprise success. MLOps provides the structure needed to move from scattered experiments to dependable, scalable AI systems that deliver consistent value.
When organizations strengthen collaboration, streamline workflows, and align their tools and practices, they create an environment where AI can grow with confidence.
A clear understanding of your current maturity helps you see where improvements are needed, prioritize the right investments, and accelerate adoption across teams. Building this foundation ensures your AI initiatives are stable, scalable, and ready for enterprise demand.
If you're looking to advance your MLOps capabilities or develop custom AI/ML solutions tailored to your business, we’re here to help. Connect with us to assess your maturity and shape a roadmap that transforms your AI operations into an enterprise-ready capability.
About the author
Pinakin Ariwala
Pinakin is the VP of Data Science and Technology at Maruti Techlabs. With about two decades of experience leading diverse teams and projects, his technological competence is unmatched.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!