How Data Mesh Drives Better Collaboration with Decentralized Data
Explore how Data Mesh architecture enables scalable, decentralized & domain-driven data management.
Data Analytics and Business Intelligence
How Data Mesh Drives Better Collaboration with Decentralized Data
Explore how Data Mesh architecture enables scalable, decentralized & domain-driven data management.
Table of contents
Table of contents
What is a Data Mesh?
4 Core Principles of Data Mesh
Top 6 Benefits of Implementing Data Mesh
The 3 Biggest Challenges with Data Mesh
3 Real-World Applications of Data Mesh
Conclusion
FAQs
What is a Data Mesh?
“A Data Mesh is a type of architecture that shifts away from centralized unisource data storage, decentralizing data ownership and treating data as a product. This architecture follows a domain-oriented design where specific departments manage data, taking accountability for data security, quality, and availability. “
Traditional centralized data architectures collect and store data in a data lake or warehouse. As organizations grow and have multiple data sources, this can lead to bottlenecks, governance, and scalability issues.
How Traditional Architectures Differ from Data Mesh?
Here are the primary differences between traditional architecture and a data mesh.
1. Single Centralized Platform Vs. Federated Self-Service Platforms
As data scales, centralized platforms can create hindrances. Data Mesh works on federated self-service tools, allowing independent management and data accessibility and promoting alignment with shared governance protocols.
2.Monolithic Vs. Domain-Oriented Design
Centralized architectures use a one-size-fits-all system for all the data. Data Mesh observes an approach where different teams manage domain-specific pipelines, enabling tailored solutions and better scalability.
3. Data-as-an-Asset Vs. Data-as-a-Product
Conventional systems treat data as a central asset for storage and reporting. Data Mesh treats data as a product. The domain teams are responsible for quality, discoverability, documentation, and usability.
4. Centralized Vs. Decentralized Ownership
One team manages centralized data, causing bottlenecks. Data mesh empowers domain teams to manage data, decentralizing ownership.
5. Scaling Challenges
Performance and coordination are major issues as data grows in centralized systems. On the other hand, distributed responsibilities across domains make scaling easy for Data Mesh. In addition, it reduces responsibilities, fostering growth and innovation.
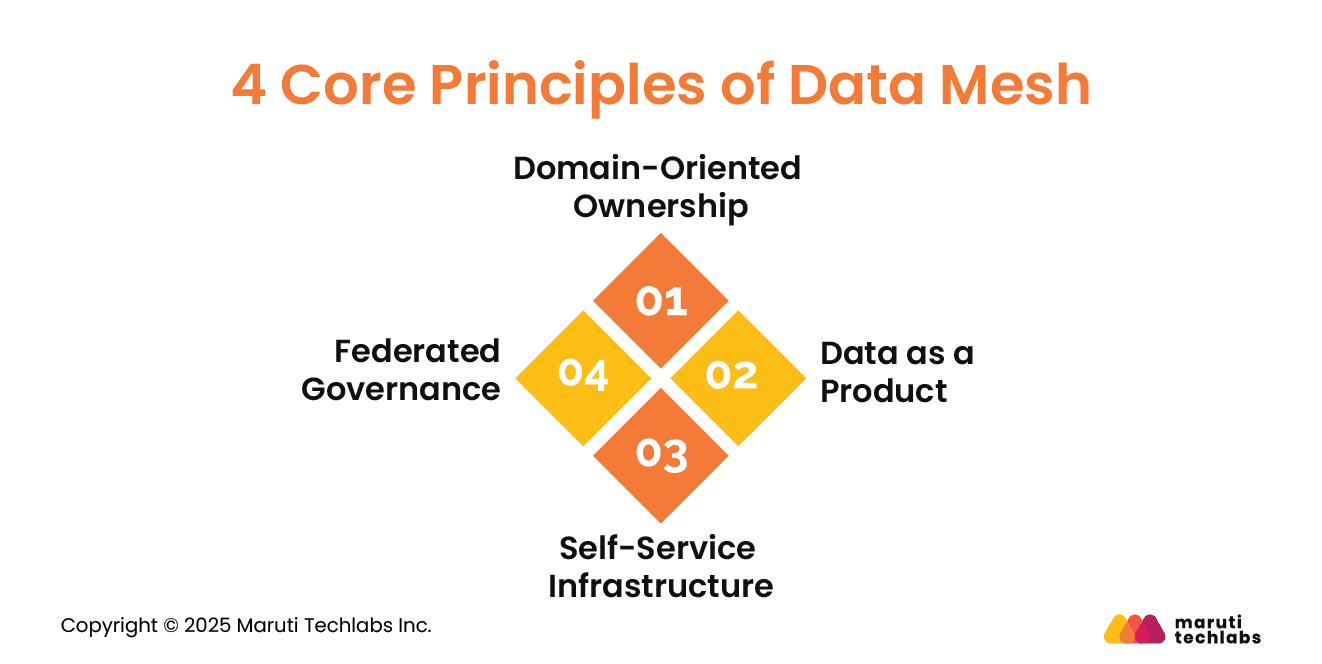
4 Core Principles of Data Mesh
Here are the 4 essential principles of Data Mesh.
1. Domain-Oriented Ownership: The data is owned by teams that use it directly.
2. Data as a Product: Each domain considers and treats data as a product, ensuring usability, accessibility, and discoverability.
3. Self-Service Infrastructure: A shared platform enhances data availability while decreasing reliance on one team.
4. Federated Governance: Standardized practices ensure consistency, interoperability, and compliance across domains.
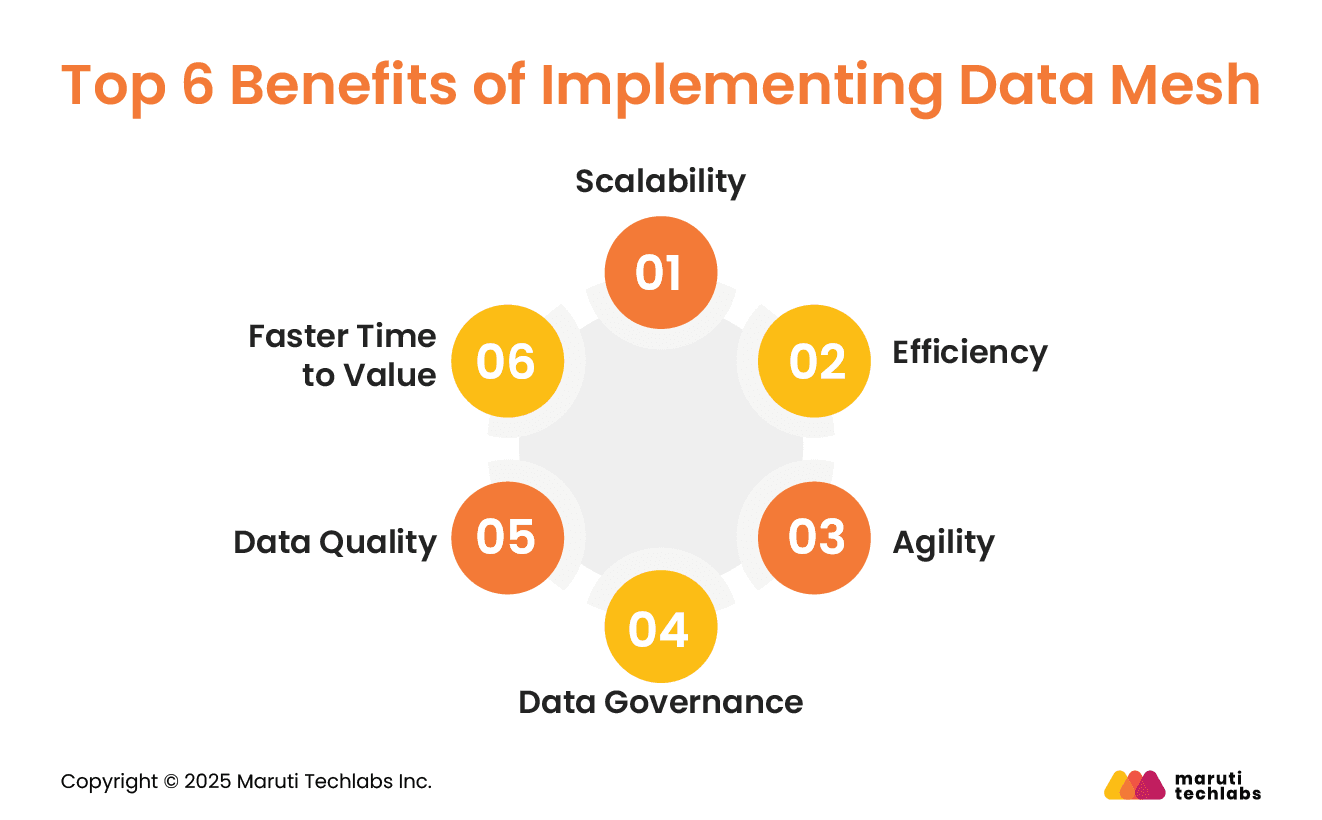
Top 6 Benefits of Implementing Data Mesh
Here are the most well-known benefits of implementing Data Mesh.
1. Scalability
Data mesh divides data into smaller domains that can be reused across the organization. Independent data products allow engineers to merge these blocks and create complex solutions. This adds to the scaling capabilities of data products compared to traditional monolithic architectures.
2. Efficiency
Treating data as a product ensures quick changes and eliminates the need for significant alterations in the data pipeline. Subsequently, it improves data management efficiency.
In addition, as data management tasks can be conducted across multiple domains, decentralizing data can add to its efficiency.
3. Agility
Centralized data teams generally face greater challenges when addressing new requirements or changes. A data mesh architecture doesn’t need centralized approval, empowering domain teams to respond promptly and decisively to changes. This flexibility offers great convenience in today's ever-evolving digital landscape.
4. Data Governance
Centralized teams often struggle to maintain standards and quality across disparate data sources, making data governance complex and burdensome. In contrast, data mesh distributes team responsibility, leading to effective and efficient data governance.
5. Data Quality
As data is divided, expert data engineers find it easier to maintain it, avoiding neglect over time. As the stakeholders are accountable for upholding quality, monitoring and management activities are done more proactively.
6. Faster Time to Value
Due to the self-serve data infrastructure, data teams don’t need to wait for approvals. This fosters independent management and creation of data pipelines. This helps companies deliver new data products and services more efficiently, resulting in faster insights and decision-making. This offers a competitive advantage in today’s changing business landscape.
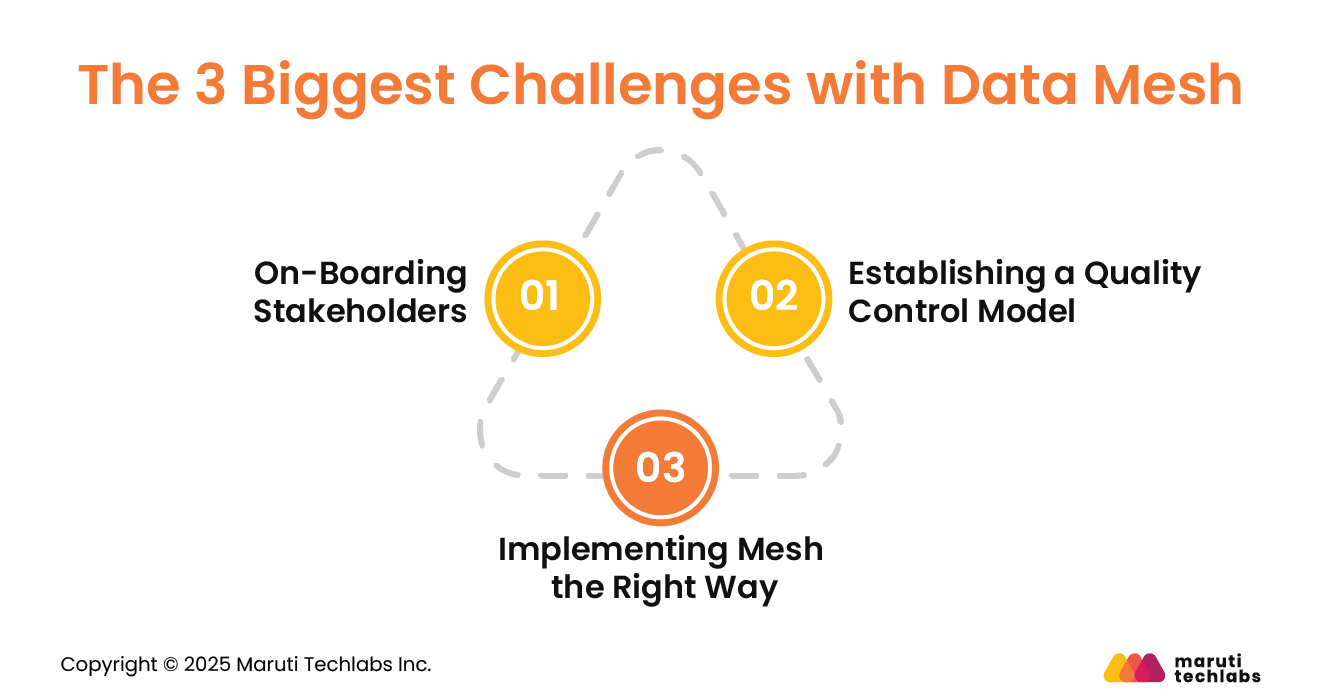
The 3 Biggest Challenges with Data Mesh
No matter what IT service providers promise, there is no such thing as a frictionless tech transformation. So, if your company is prone to using a centralized data platform, transitioning to a data mesh will present some challenges. Let’s observe the top 3 challenges you’ll face when making this switch.
1. On-Boarding Stakeholders
As observed with any other change you want to bring about in an organization, it can only be implemented if all stakeholders agree. Here are a few hurdles that you would have to overcome.
Data mesh demands dividing ownership amongst different business domains. This will add to the work of business workers who might not appreciate it.
If your central data team feels threatened in their job, you can expect pushback or resistance to make this change.
You need to establish authority on different data domains. Overlapping business roles can make finalizing the business domains and their subsequent managers cumbersome.
Not everyone is equally motivated to learn new tech. Especially if you have non-tech-savvy seniors, they might feel overwhelmed with this transition.
2. Establishing a Quality Control Model
Unlike a central data team, a data mesh relies on domain owners to uphold the data quality. So, you’re placing your bets on individuals who can be strangers to each other, don’t have similar priorities, or even share the same terminology.
If you don’t consider these differences, data quality can be compromised in the long run.
3. Implementing Mesh the Right Way
A data mesh isn’t a replacement for your central data fabric. Distributing ownership amongst business teams doesn’t imply working in isolated silos without considering the bigger picture.
Data siloes are a considerable risk with data mesh, where teams don’t share data and only focus on their data. This problem arises when businesses use custom-built tools not designed for the data mesh.
Many suggest assigning each team responsibility for a portion of the existing system. But this can be challenging, especially when teams rely on different cloud tools and even more so in today’s landscape, where multi-cloud environments are the norm.
3 Real-World Applications of Data Mesh
Here are the top 3 applications of data mesh in the real world.
1. Intuit
Intuit wanted to build a smarter, more personalized product experience through data-driven systems. However, teams like analysts, engineers, and scientists often encountered barriers to data discoverability, clarity, ownership, and access.
Uncertainty around responsibilities, such as who manages a dataset or approves access, led to inefficiencies and duplication. To tackle this, Intuit embraced a data mesh approach, allowing data workers to take full ownership of the data systems they design, develop, and maintain.
This shift introduced the concept of “data products”: well-defined, reusable datasets aligned to specific business needs. Each data product has clear ownership, documentation, quality metrics, and operational accountability.
2. JP Morgan & Chase
As part of its cloud-first modernization strategy, JP Morgan & Chase sought to reduce infrastructure costs, promote data reuse, and open innovation avenues.
To enable this, they implemented a data mesh architecture. Each business unit was treated as a distinct data domain and was empowered to manage its own data lake environment.
This included complete control over data producer and consumer accounts. Despite decentralization, the company enforced strict governance through standardized policies and a centralized metadata catalog that ensured consistency, lineage tracking, and data trustworthiness.
3. Delivery Hero
Facing challenges with data accessibility, quality, security, and scalability, Delivery Hero saw potential in data mesh as an organizational framework and not just a technical solution.
By decentralizing ownership, they aimed to enhance accountability and a data-driven culture. They built domain-specific data platforms on Google Cloud Platform, equipping each with necessary resources like BigQuery, Kubernetes, CloudSQL, and networking components.
This empowered each team to manage and scale its data infrastructure independently, while maintaining consistency and governance.
Conclusion
Data mesh holds the future of enterprise data strategy. However, its USP lies in achieving the right balance between decentralization and control. As organizations grow more data-rich and cloud-diverse, traditional centralized models struggle to keep up with demands for scalability, agility, and real-time access.
Data mesh provides a practical way to give domain teams ownership of their data while still maintaining shared governance and ensuring that systems can work together smoothly. However, successful implementation requires deep expertise in architecture, governance, and cloud-native technologies.
That’s where Maruti Techlab’s Data Engineering Services can help. We help enterprises modernize their data infrastructure by designing scalable mesh-ready architectures, enabling domain-level autonomy, and building pipelines that support secure, trusted, and discoverable data products.
From strategy to execution, we empower businesses to break silos, improve time-to-insight, and align their data strategy with evolving business needs. Connect with us today to explore new ways to manage data proactively.
FAQs
1. Why is data mesh obsolete?
Data mesh isn’t obsolete, but critics argue it's hard to implement at scale. Without strong governance and infrastructure, it can create data silos, fragmented tools, and increased complexity.
2. What is a data mesh vs a data lake?
A data lake centralizes raw data storage, while a data mesh decentralizes ownership and treats data as a product, enabling domain teams to manage, publish, and consume data independently.
3. What are the key principles of a data mesh model?
Key principles include domain-driven ownership, data as a product, self-serve infrastructure for data teams, and federated governance for standardization, interoperability, and quality control.
4. What are the primary challenges of adopting a data mesh framework?
Challenges include organizational resistance, lack of data ownership clarity, need for mature infrastructure, governance enforcement, and ensuring interoperability across domains without recreating data silos.
5. Where is data stored in a data mesh?
In a data mesh, data is stored within domains, often in distributed or cloud environments. Each domain manages its storage while ensuring discoverability and access through standardized interfaces.
Pinakin Ariwala has over 20 years of experience in AI/ML, data engineering, and software development. He has led AI and machine learning projects across industries, including agriculture, finance, and healthcare, and has been featured on the Clutch Leaders Matrix podcast discussing real-world AI/ML applications.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!