Key Takeaways
- LLM customization is vital for business accuracy and domain relevance.
- Prompt engineering offers quick, budgeted content creation and early adoption.
- Fine-tuning provides high domain accuracy but requires vast amounts of data and costs.
- RAG balances accuracy/cost, great for dynamic, data-rich environments.
- Select the method based on your goals, data, resources, and the scale of your needs.
Introduction
LLMs are undeniably powerful, but generic models rarely meet the unique needs of every business. That’s where customization becomes essential, ensuring relevance, accuracy, and performance aligned with your goals.
There are three primary ways to tailor an LLM: Prompt Engineering, Fine-tuning, and Retrieval-Augmented Generation (RAG). Each offers distinct trade-offs in cost, accuracy, and scalability.
Five years ago, a tectonic shift redefined how we work when OpenAI released ChatGPT in 2022. It marked the dawn of a new human–machine partnership. Language became the interface, and tasks like coding, writing, and decision-making changed forever.
Today, nearly every business leverages some form of Large Language Model (LLM), yet many still struggle to unlock their full potential.
In this blog, we’ll explore these three approaches, their use cases, compare their different aspects, and help you choose the right path for effective, future-ready LLM customization.
What are the 3 Main Approaches to LLM Customization?
Enterprises seeking to maximize the value of their Large Language Models (LLMs) can utilize three optimization methods: prompt engineering, fine-tuning, and retrieval augmented generation (RAG).
All the above models are adept at optimizing model behavior. However, which one suits your needs best depends on the targeted use case and available resources.
Let’s get a brief overview of what these techniques have to offer.
- Prompt Engineering: The skill of crafting exact prompts that help models understand your requirements and produce desired outputs.
- Fine-Tuning: Altering pre-trained models to niche datasets, to enhance their outputs on specific tasks or domains.
- Retrieval-Augmented Generation (RAG): An approach that facilitates real-time knowledge retrieval while sharing AI outputs, ensuring contextual relevance and accuracy.
All three approaches offer distinct advantages and trade-offs, making them suitable for various requirements and environments.
Top 3 Use Cases of Prompt Engineering, Fine-Tuning, and RAG Across Industries
Let’s observe how all three techniques can be applied across different industries.
1. Healthcare
- Prompt Engineering:
- AI-powered chatbots to schedule or answer FAQs, simplifying patient interactions.
- For instance, “What’s the process to schedule a follow-up appointment?”
- Fine-Tuning:
- Offering research support or diagnostic assistance by feeding medical datasets to train AI models.
- For instance, fine-tuned models can summarize patient history or analyze radiology reports.
- RAG:
- Having real-time access to the latest medical updates or guidelines.
- For instance, a RAG-equipped system can fetch updated protocols for treating rare diseases.
2. Finance
- Prompt Engineering:
- Creating financial summaries or offering personal investment recommendations.
- For instance, share a summary of this quarter’s generated revenue.
- Fine-Tuning:
- Training an AI model on specific datasets to detect fraudulent transactions.
- For instance, spotting unusual patterns in credit card payments.
- RAG:
- Sharing real-time insights of stock performance or market trends.
- For instance, giving the latest news updates can adversely affect a specific stock’s prices.
3. Marketing & Advertising
- Prompt Engineering:
- Creating blog outlines, headlines, content copies, and more.
- For instance, write a quirky headline for the upcoming winter sale.
- Fine-Tuning:
- Developing AI models that are adept at creating end-to-end marketing campaigns or ad copies.
- For example, create promotional content for a pizza franchise.
- RAG:
- Fetching information on live events or other real-time offers for dynamic ad content.
- For example, creating ad content based on current weather conditions.
Across industries, these three methods drive smarter operations, enhancing patient care in healthcare, detecting fraud in finance, and crafting dynamic marketing campaigns. Each plays a unique role in driving AI-driven efficiency and innovation.
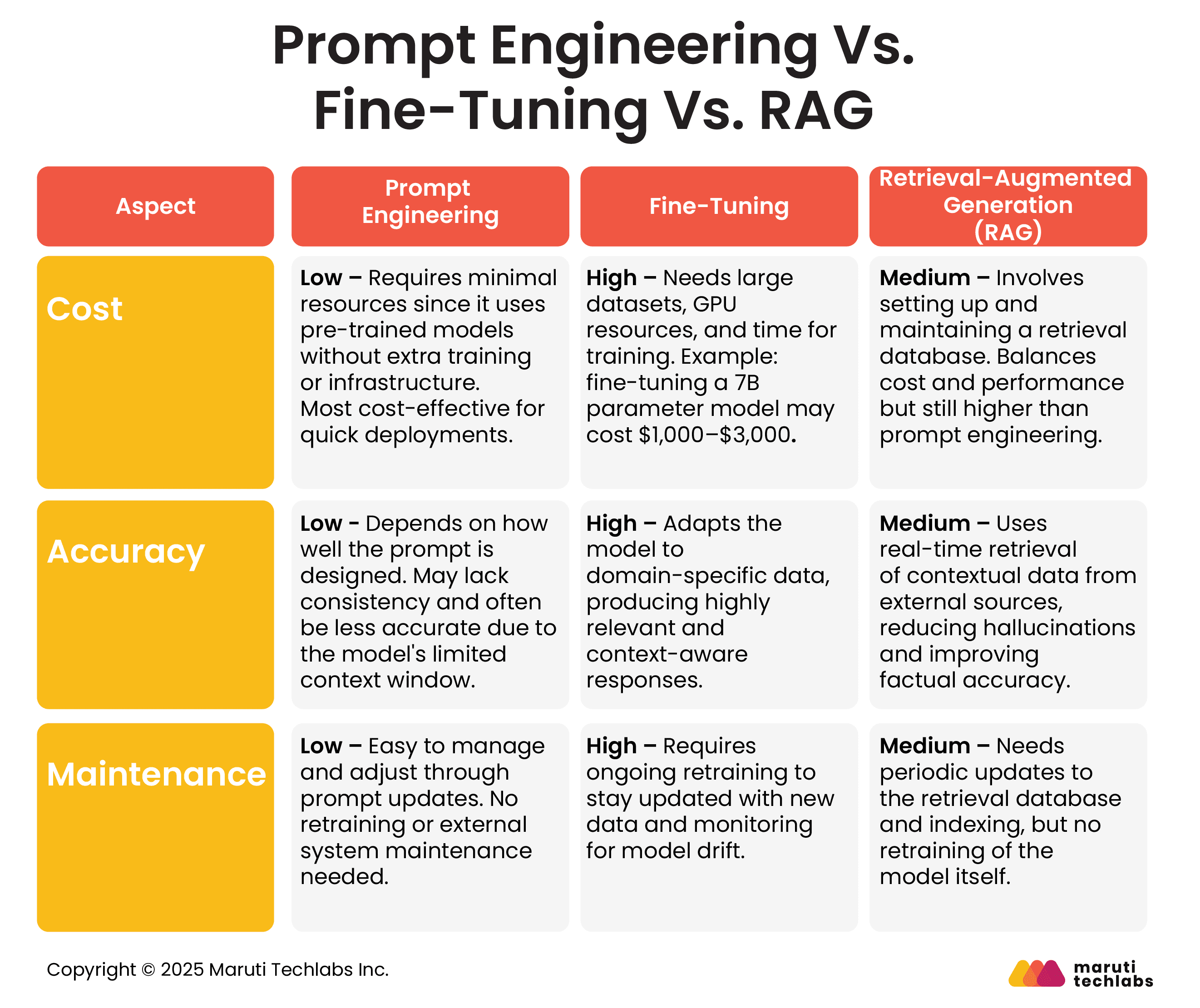
Ultimate Comparison: Prompt Engineering Vs. Fine-Tuning Vs. RAG
Let’s break down how each method compares in terms of cost, accuracy, and upkeep.
Prompt Engineering, Fine-Tuning, or RAG: How Do You Select the Right Approach?
Follow these five simple steps to zero in on the approach that fits your business best.
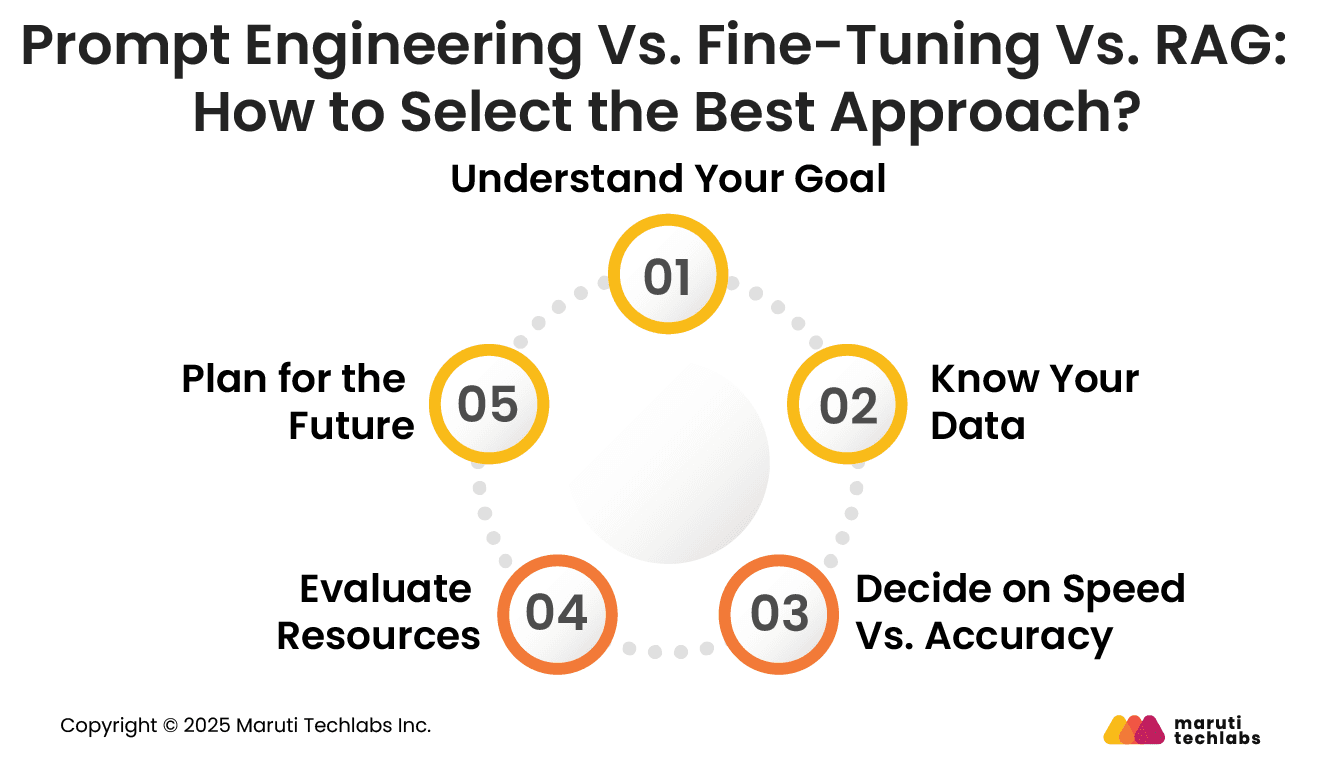
1. Understand Your Goal
Identify whether your focus is on accuracy, scalability, or cost efficiency. Your business objective determines which AI optimization approach is best suited for your needs.
2. Know Your Data
Assess the volume, quality, and structure of your data. High-quality, domain-specific data favors fine-tuning or RAG over simple prompting.
3. Decide on Speed Vs. Accuracy
If you need quick deployment, prompt engineering works best. For precision and context-rich outputs, RAG or fine-tuning delivers stronger results.
4. Evaluate Resources
Consider budget, infrastructure, and technical expertise. Fine-tuning demands high computational resources and specialized skills, while RAG and prompt engineering require fewer resources.
5. Plan for the Future
Choose a scalable approach. RAG supports continuous data updates, while fine-tuning provides long-term domain expertise and flexible engineering.
Choosing Between Prompt Engineering, Fine-Tuning, and RAG
There’s no one-size-fits-all when it comes to customizing LLMs. The right approach really depends on what you’re building, the type of data you have, and the level of control you want. Let’s look at a few real-world scenarios to see when prompt engineering, fine-tuning, or RAG makes the most sense.
1. Choose Prompt Engineering if:
- You’re just commencing your AI journey and want to test new ideas quickly.
- Your tasks involve generating content, writing blogs, and creating FAQs.
- You lack technical expertise or have a limited budget.
- You don’t require niche or specialized outputs.
2. Choose Fine-Tuning if:
- You need to perform tasks like writing code or creating technical reports.
- You have access to technical resources or niche high-quality datasets.
- You have a long-term goal that justifies your upfront investment.
- Your model needs a consistent style or tone.
3. Choose RAG if:
- Your product relies on data that is frequently updated, such as healthcare or financial regulations.
- You want to avoid model retraining while receiving accurate, context-specific data.
- You plan to minimize hallucinations using verified sources.
- You need to maintain a vector database and have the resources for it.
In short, prompt engineering is best for quick experiments and content generation with minimal setup. Fine-tuning works when you need precision, consistency, and domain expertise. RAG is ideal for keeping outputs current and factual without retraining the model. The right choice depends on your goals, data, and the level of hands-on involvement you want with your AI.
Conclusion
Choosing between Prompt Engineering, Fine-Tuning, and RAG ultimately depends on your organization’s priorities, whether that’s cost-efficiency, accuracy, scalability, or adaptability.
Understanding your data maturity, business goals, and available resources is key to selecting the correct method. The right approach can significantly enhance productivity, customer experience, and decision-making through optimized language model performance.
If you’re ready to unlock the full potential of AI customization, explore how Maruti Techlab’s Generative AI Services can help you design, implement, and scale the best-fit solution for your business.
If you’re just commencing your AI journey, our AI Strategy and Readiness services can help you learn your business requirements and help design an adequate AI solution.
Partner with Maruti Techlabs today to build more innovative, adaptive, and cost-efficient AI systems.
Frequently Asked Questions
1. What is the difference between fine-tuning, prompt engineering, and RAG?
Fine-tuning customizes a model using domain-specific data for precise outputs.
Prompt engineering optimizes how you query models for better responses without retraining.
RAG combines language models with external databases to fetch real-time, factual information, thereby improving accuracy and reducing hallucinations.
2. What is the main advantage of using prompt engineering over fine-tuning?
Prompt engineering is faster, cheaper, and requires no retraining. It enables businesses to achieve beneficial results using existing models with minimal data or technical effort, making it perfect for experimentation or quick deployments.
However, fine-tuning requires more computational resources, specialized datasets, and time to achieve domain-specific performance.
3. Can you use both RAG and fine-tuning?
Yes. Combining RAG and fine-tuning often delivers optimal results. Fine-tuning tailors the model’s internal knowledge to specific domains, while RAG supplements it with up-to-date, external data.
Together, they enhance contextual understanding, accuracy, and factual relevance, particularly in industries that require frequent updates to information, such as healthcare or finance.
4. How do I choose between fine-tuning, prompt engineering, and RAG?
Choose based on goals, data availability, and resources. Utilize prompt engineering for speed and cost efficiency, fine-tuning for accuracy in specialized domains, and RAG for real-time, factual outputs.
Assess your infrastructure, technical expertise, and scalability requirements to select the most balanced and sustainable approach for your business.
About the author
Pinakin Ariwala
Vice President Data Science & Technology
Pinakin Ariwala has over 20 years of experience in AI/ML, data engineering, and software development. He has led AI and machine learning projects across industries, including agriculture, finance, and healthcare, and has been featured on the Clutch Leaders Matrix podcast discussing real-world AI/ML applications.







