Why Multimodal AI is Better than Single-Modal AI Models?
Explore how to boost business insights and decisions with Multimodal AI over single-modal systems.
Artificial Intelligence and Machine Learning
Why Multimodal AI is Better than Single-Modal AI Models?
Explore how to boost business insights and decisions with Multimodal AI over single-modal systems.
Table of contents
Table of contents
Key Takeaways
Introduction
What is Single-Modal AI?
Benefits of Single-Modal AI
What is Multimodal AI?
Benefits of Multimodal AI Models
Difference Between Multimodal AI and Single-Modal AI
Where Does Multimodal AI Outperform Single-Modal AI?
Industry-Wise Comparison of Multimodal AI and Single-Modal AI
Top Widely Used Single-Modal AI Models
Top Widely Used Multimodal AI Models
What Challenges Does Multimodal AI Face?
Conclusion
FAQs
Why Maruti Techlabs for Multimodal AI Development?
Key Takeaways
Multimodal AI processes text, images, audio, video, and sensor data together for deeper contextual understanding.
Single-modal AI focuses on one data type, making it faster, simpler, and cost-effective for specialized tasks.
Multimodal AI delivers higher accuracy, better personalization, and more human-like interactions.
Industries such as healthcare, retail, finance, automotive, and education are rapidly adopting multimodal AI systems.
Leading multimodal AI models include GPT-4o, Gemini, and Claude 3.
Popular single-modal AI models include GPT-3, BERT, and Whisper.
While multimodal AI offers broader intelligence and automation capabilities, it also introduces challenges related to infrastructure costs, privacy, and explainability.
Introduction
AI systems in 2026 are progressing beyond isolated data processing. Businesses no longer rely solely on models that understand only text, images, or audio independently. Instead, enterprises are more frequently adopting multimodal AI systems capable of interpreting multiple data types together to achieve deeper contextual understanding and more accurate decision-making.
This shift is driven by the growing demand for AI applications that can interact naturally with humans, automate complicated workflows, and deliver highly personalized experiences. From AI copilots and self-operating systems to advanced clinical testing and intelligent customer support, multimodal AI is becoming the foundation of next-generation enterprise intelligence. This movement has increased the adoption of Generative AI Services across enterprises.
The global multimodal AI market is projected to exceed USD 10 billion by 2030. As opposed to traditional single-modal AI systems, multimodal AI combines information from text, images, videos, audio, sensor data, and structured datasets to better understand relationships among inputs. This allows businesses to generate richer insights, reduce errors, and boost operational efficiency.
This blog shows how multi-model AI is emerging as a key differentiator for building scalable, intelligent, and user-centric systems when compared to single-modal AI.
What is Single-Modal AI?
Single-modal AI refers to artificial intelligence systems trained on a single data source or modality. These systems typically specialize in processing text, images, audio, or video independently.
For years, single-modal AI served as the standard approach for building intelligent systems because of its simplicity and focused training capabilities. Text-based chatbots, image recognition tools, and speech assistants are all examples of single-modal AI applications.
However, these systems frequently struggle to interpret complex real-world situations because they lack contextual awareness across multiple data formats.
For instance:
A text-only chatbot may fail to understand user sentiments.
An image recognition model cannot interpret spoken instructions.
A speech assistant may miss the visual cues key to accurate responses.
While single-modal AI remains useful for narrow tasks, modern enterprise applications increasingly require richer contextual understanding that goes beyond one data source.
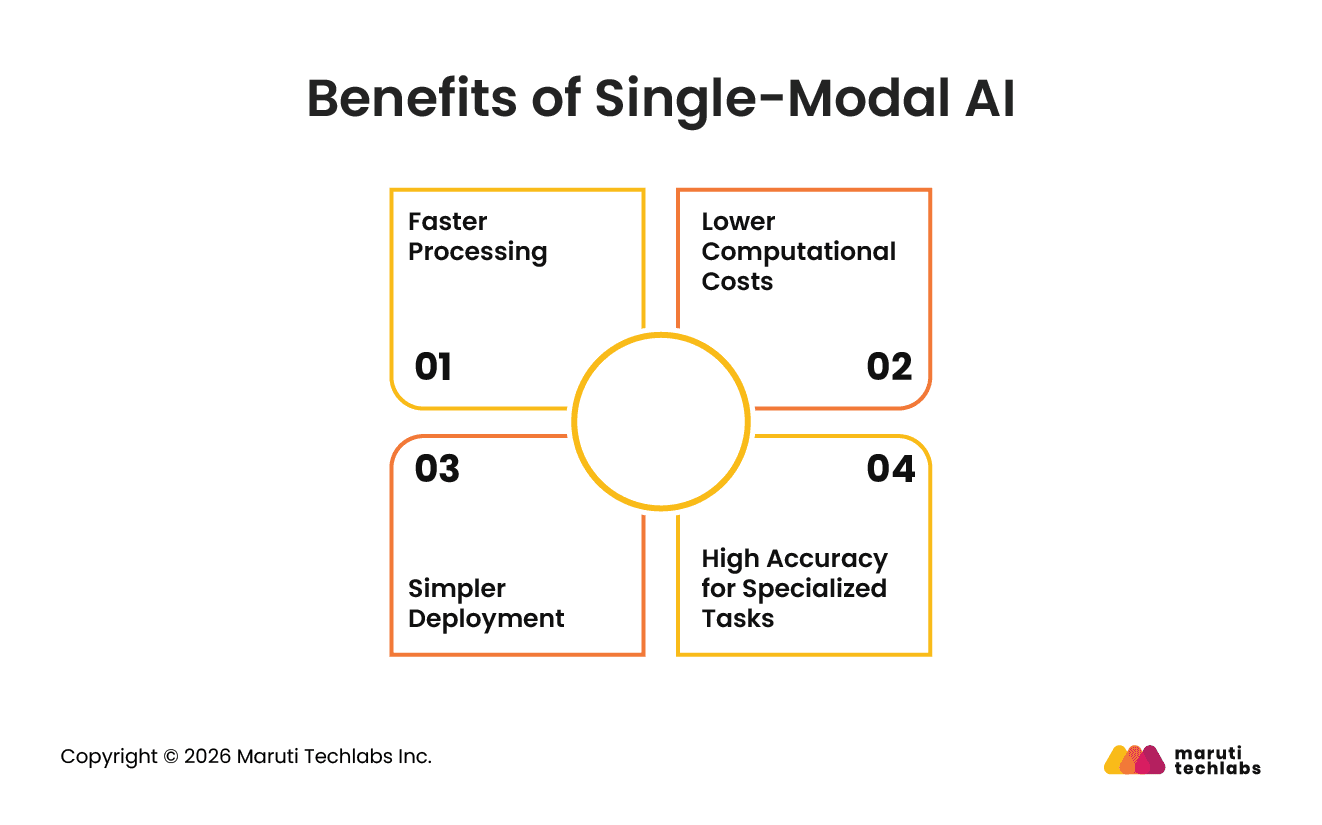
Benefits of Single-Modal AI
Single-modal AI models offer faster processing, lower computational requirements, simpler deployment, and high efficiency for specialized tasks involving a single data type such as text, images, or audio.
1. Faster Processing
Single-modal AI models process a single type of data, allowing faster training, inference, and response times for targeted tasks.
Tesla relies heavily on camera-based computer vision systems for driver assistance and autonomous driving capabilities.
2. Lower Computational Costs
These models require less computing power, storage, and infrastructure compared to multimodal AI systems, making them more cost-effective.
Duolingo uses text- and speech-focused AI models for language exercises and pronunciation evaluation, which require less computational power than multimodal systems that process multiple complex data streams simultaneously.
3. Simpler Deployment
Single-modal AI systems are easier to develop, integrate, maintain, and scale because they focus on one data source and simpler architectures.
Grammarly uses text-only AI models for grammar correction, tone analysis, and writing suggestions.
4. High Accuracy for Specialized Tasks
For domain-specific applications such as image classification, speech recognition, or sentiment analysis, single-modal AI can deliver highly optimized performance.
Google uses image-focused AI models for facial recognition, object detection, and photo organization.
What is Multimodal AI?
Multimodal AI is a machine learning approach that processes and combines multiple types of data simultaneously, such as text, images, audio, video, and sensor inputs.
Unlike traditional AI systems designed for a single data type, multimodal AI models establish relationships across different modalities to gain a more complete understanding of information.
For example:
A multimodal AI assistant can process voice commands, facial expressions, and text prompts together.
Healthcare AI systems can combine MRI scans, patient history, and laboratory data for diagnosis.
Retail recommendation engines can use browsing history, product images, and customer reviews simultaneously.
By combining multiple data sources, multimodal AI delivers more intelligent, context-aware, and human-like interactions.
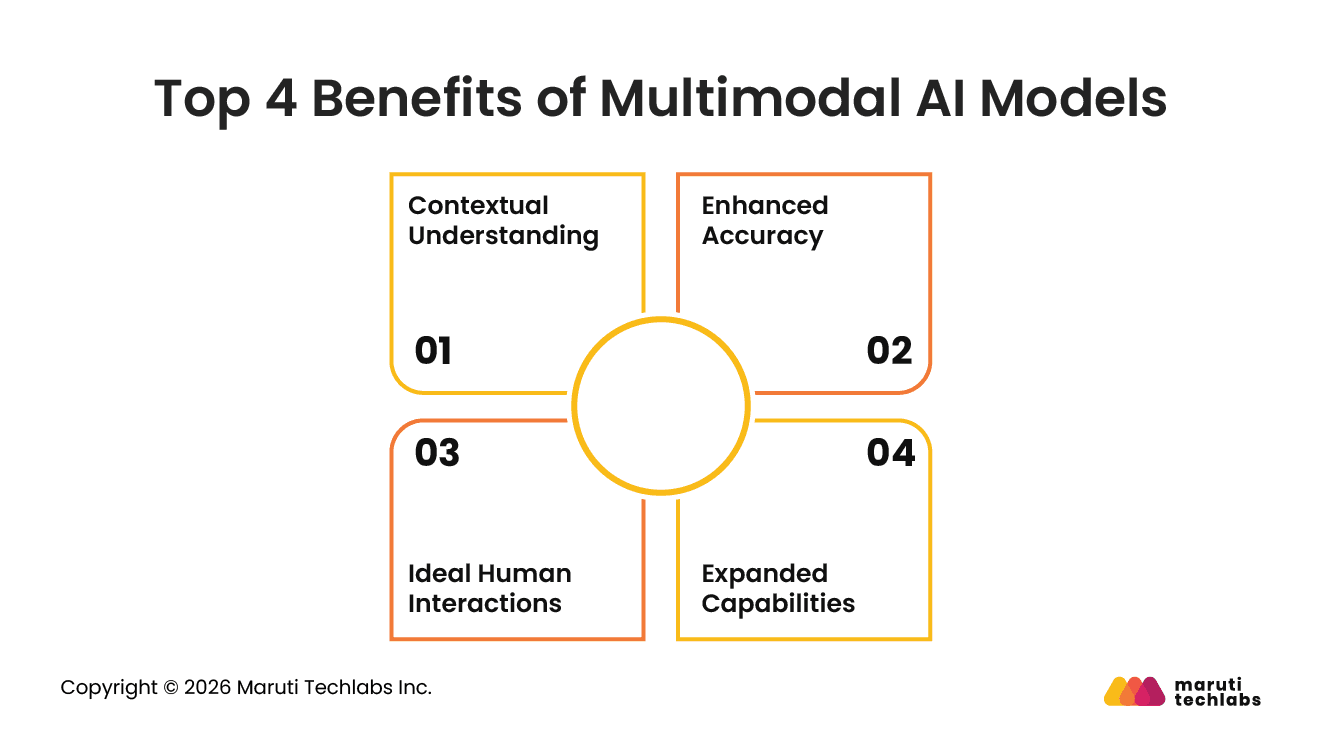
Benefits of Multimodal AI Models
Multimodal AI models benefit businesses by processing text, images, audio, video, and sensor data simultaneously, resulting in higher accuracy, deeper contextual understanding, improved automation, and more personalized user experiences across industries.
Here are the major advantages enterprises gain from adopting multimodal AI.
1. Contextual Understanding
Multimodal AI improves contextual awareness by combining linguistic, visual, and auditory inputs. This enables systems to understand user intent more accurately and respond more naturally.
For instance, Pinterest Lens uses multimodal AI to combine image and text queries, helping users discover products through photos rather than traditional keyword searches.
2. Enhanced Accuracy
By processing multiple data types together, multimodal AI boosts prediction accuracy and reduces ambiguity. Cross-referencing inputs allows systems to validate information more effectively.
For example, Wayfair uses vision-language AI models to analyze customer-uploaded photos of product damage alongside textual complaints, helping to automate faster, more accurate return and resolution workflows. Organizations that use Data Visualization Services can further improve the quality of multimodal insights concerning business intelligence applications.
3. Ideal Human Interactions
Traditional AI systems frequently struggle to create natural interactions because they rely on limited input types. Multimodal AI enables far more intuitive and human-like communication through voice, visuals, gestures, and text.
Virtual assistants equipped with multimodal capabilities can understand spoken commands while interpreting visual context obtained from cameras or shared screens.
Amazon Alexa uses multimodal AI to process voice commands alongside contextual inputs such as user behavior, device activity, and smart home visuals.
4. Expanded Capabilities
Multimodal AI enables systems to perform complex tasks that require understanding multiple forms of information simultaneously.
This includes image recognition, speech interpretation, object detection, content generation, and real-time contextual analysis.
Unilever uses multimodal AI and digital twins powered by NVIDIA technologies to generate product imagery faster, reduce production costs, and uphold brand consistency across global marketing channels.
Difference Between Multimodal AI and Single-Modal AI
While single-modal AI specializes in processing one data type, multimodal AI integrates multiple modalities to deliver broader intelligence and stronger contextual understanding.
Aspect
Single-Modal AI
Multimodal AI
Data Processing
Processes one data type only
Processes multiple data types together
Context Awareness
Limited contextual understanding
Rich contextual understanding
Accuracy
Lower in complex scenarios
Higher due to cross-modal validation
User Interaction
Restricted and less natural
More human-like and intuitive
Flexibility
Suitable for narrow tasks
Handles complex real-world tasks
Decision-Making
Relies on isolated inputs
Uses combined insights for better decisions
Enterprise Use Cases
Chatbots, OCR, speech recognition
Healthcare AI, autonomous systems, AI copilots
Scalability
Easier to manage
More infrastructure-intensive
Training Complexity
Lower
Higher due to multiple data pipelines
Personalization
Limited
Advanced personalization capabilities
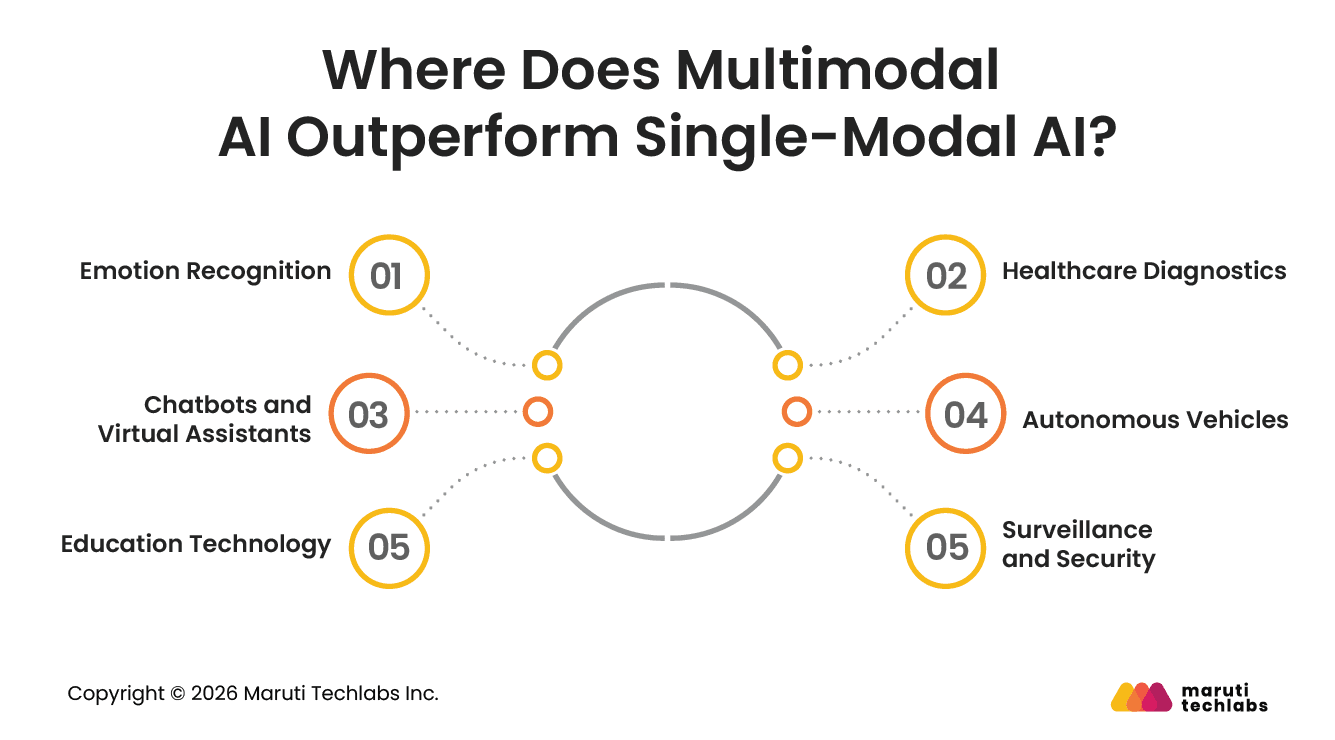
Where Does Multimodal AI Outperform Single-Modal AI?
Multimodal AI is superior to single-modal AI because it combines multiple data types, such as text, images, audio, and video, to deliver deeper contextual understanding, higher accuracy, and more intelligent decision-making, while single-modal AI processes only one input type at a time.
1. Emotion Recognition
Multimodal AI analyzes video, text, and audio together to understand emotions more precisely. It assesses facial expressions, voice tone, and words in customer communications to provide empathetic responses.
Single-modal AI relies on a single data type, often resulting in lower accuracy and performance.
2. Healthcare Diagnostics
Multimodal AI combines medical images, patient records, and genetic data to produce accurate diagnoses and customized treatments, such as merging X-rays, MRIs, and medical history for better insights.
Traditional AI, limited to one data type, risks less accurate outcomes.
3. Chatbots and Virtual Assistants
Multimodal AI processes voice, text, and visual inputs for natural interactions, similar to Google Assistant or Alexa, utilizing voice and camera data for advanced assistance.
Traditional AI, limited to one input type, struggles with complex or context-rich queries.
4. Autonomous Vehicles
Multimodal AI combines data from cameras, LIDAR, radar, and GPS to increase safety and navigation by utilizing multiple sensors to spot obstacles for autonomous driving.
Traditional AI, which relies on a single data type, performs less accurately in complex conditions.
5. Education Technology
Multimodal AI combines text, video, audio, and simulations to create customized learning experiences, similar to web platforms that modify lessons to each student’s style and pace.
Traditional AI, limited to a single data type, struggles to support multiple learning needs effectively.
6. Surveillance and Security
Multimodal AI combines video, audio, and motion sensor data to enable more intelligent threat detection, allowing surveillance systems to identify risks and reduce false alarms accurately.
Traditional AI, limited to a single data source, often produces more errors and misses detections.
Industry-Wise Comparison of Multimodal AI and Single-Modal AI
Industry
Single-modal AI Applications
Multimodal AI Applications
Business Impact
Healthcare
Medical image analysis or patient record analysis independently
Medical imaging + patient records + diagnostics
Multimodal AI improves diagnostic accuracy, while single-modal AI speeds up specialized analysis.
Retail & E-commerce
Recommendation engines based only on browsing or purchase history
Product images + reviews + browsing behavior
Multimodal AI enables deeper personalization, while single-modal AI improves basic recommendations.
Finance
Transaction monitoring or document analysis separately
Voice analysis + transaction history + documents
Multimodal AI strengthens fraud detection, while single-modal AI improves transaction monitoring.
Manufacturing
Sensor-based predictive maintenance
Sensor data + video feeds + maintenance logs
Multimodal AI improves predictive maintenance, while single-modal AI reduces equipment downtime.
Automotive
Camera-based driver assistance systems
Cameras + radar + GPS + LiDAR
Multimodal AI enhances autonomous driving, while single-modal AI supports driver assistance.
Education
Text-based learning platforms and automated grading
Video + text + simulations + assessments
Multimodal AI personalizes learning, while single-modal AI streamlines assessments.
Media & Entertainment
Content recommendations based only on watch history
Audio + video + user engagement data
Multimodal AI improves content relevance, while single-modal AI boosts engagement tracking.
Security & Surveillance
Facial recognition or motion detection independently
Motion sensors + facial recognition + audio
Multimodal AI improves threat detection, while single-modal AI accelerates monitoring.
Customer Support
Chatbots using only text interactions
Voice + chat + screenshots + CRM data
Multimodal AI improves issue resolution, while single-modal AI handles routine queries.
Logistics
GPS-based route optimization
GPS + weather + fleet sensor data
Multimodal AI improves route optimization, while single-modal AI enhances delivery tracking.
Top Widely Used Single-Modal AI Models
Single-modal AI models are designed to process a single type of data, such as text, images, or audio, making them highly effective for specialized tasks like language processing, speech recognition, and computer vision applications.
OpenAI GPT-3: Processes and generates text for chatbots, content creation, summarization, and language tasks.
Google BERT: Understands text context for search engines, sentiment analysis, and natural language processing.
Meta LLaMA: Generates human-like text for research, open-source AI applications, and conversational systems.
OpenAI Whisper: Converts speech into text for transcription, translation, and voice-based applications.
DeepMind WaveNet: Produces natural-sounding speech for virtual assistants and text-to-speech systems.
Microsoft ResNet: Analyzes and classifies images for computer vision and image recognition tasks.
Ultralytics YOLO: Detects and tracks objects in real-time images and video streams.
Stability AI Stable Diffusion: Generates high-quality AI images from text prompts.
Top Widely Used Multimodal AI Models
The top multimodal AI models that dominate 2026 include:
GPT-4o (OpenAI): Processes text, images, and audio for natural conversations and advanced reasoning.
Claude 3 (Anthropic): Excels at understanding text and visual documents like charts and graphs.
Gemini (Google): Supports text, audio, image, and video processing across enterprise applications.
DALL·E 3 (OpenAI): Generates detailed images from textual prompts.
LLaVA: Open-source vision-language assistant for multimodal tasks.
PaLM-E (Google): Combines robotics, visual understanding, and language processing.
ImageBind (Meta): Connects six modalities for advanced multimodal understanding.
CLIP (OpenAI): Links images with natural language descriptions for recognition tasks.
What Challenges Does Multimodal AI Face?
Multimodal AI faces significant challenges related to privacy, infrastructure costs, compliance, and explainability.
1. Data Privacy and Security
Multimodal systems process large volumes of sensitive data, including voice recordings, images, biometric information, and personal interactions. Without proper safeguards, firms risk privacy violations and compliance issues.
2. High Infrastructure Costs
Training multimodal AI requires major computational resources, big datasets, and scalable infrastructure. This increases implementation and operating costs.
3. Data Integration Complexity
Combining structured and unstructured data from multiple sources is technically challenging. Retaining consistency across modalities requires advanced data engineering practices.
4. Bias and Ethical Risks
Biases found in training datasets can spread across multiple modalities, causing unfair or inaccurate outcomes in hiring, surveillance, healthcare, and finance applications.
5. Real-Time Processing Challenges
Processing text, images, audio, and sensor data simultaneously requires high-performance systems that deliver low-latency responses.
6. Explainability Issues
As multimodal AI systems become more complex, understanding how decisions are made becomes increasingly difficult, creating challenges in regulated industries.
Conclusion
Multimodal AI is redefining the future of artificial intelligence by enabling systems to process and understand multiple data modalities simultaneously. Compared to single-modal AI, it delivers deeper contextual understanding, enhanced accuracy, more natural interactions, and broader real-world applicability.
From healthcare diagnostics and autonomous vehicles to intelligent virtual assistants and adaptive education platforms, multimodal AI is helping businesses solve increasingly complex problems with greater efficiency.
Leading models such as GPT-4o, Gemini, Claude 3, and DALL·E 3 demonstrate how rapidly this technology is advancing across industries. However, organizations must also address challenges related to privacy, infrastructure, bias, and operational complexity to unlock their full potential responsibly.
FAQs
1. What is multimodal AI?
Multimodal AI is an artificial intelligence system capable of processing and integrating multiple data types, such as text, images, audio, video, and sensor inputs simultaneously.
2. How does multimodal AI work?
Multimodal AI uses advanced machine learning architectures and data fusion techniques to combine insights from multiple modalities for context-aware understanding and decision-making.
3. Is ChatGPT an example of multimodal AI?
Yes. Advanced versions like GPT-4o can process text, images, and audio together, making interactions more natural and contextually aware.
4. What is the difference between generative AI and multimodal AI?
Generative AI focuses on creating new content, while multimodal AI focuses on understanding and integrating multiple data types. Some generative AI systems can also be multimodal.
5. What are the limitations of multimodal AI?
Major limitations include high infrastructure costs, privacy concerns, bias risks, data integration complexity, and explainability challenges.
Why Maruti Techlabs for Multimodal AI Development?
At Maruti Techlabs, we help organizations design and deploy multimodal AI solutions customized to complex business environments. Our team combines deep expertise in Generative AI Services, Custom AI/ML Development, cloud-native architectures, and analytics to create intelligent systems that process diversified data streams seamlessly.
We developed an AI-powered audio classification model for a SaaS provider that could identify human vs machine responses within 500 milliseconds using predictive modeling and voice pattern analysis.
Achieved over 90% classification accuracy
Reduced manual intervention through automated audio analysis
Saved approximately $110K per month in operational costs
Improved real-time decision-making using AI-powered voice pattern recognition
Businesses building future-ready AI systems can leverage Custom AI/ML Development services to create multimodal systems that understand user intent across text, images, and voice inputs.
Pinakin Ariwala has over 20 years of experience in AI/ML, data engineering, and software development. He has led AI and machine learning projects across industries, including agriculture, finance, and healthcare, and has been featured on the Clutch Leaders Matrix podcast discussing real-world AI/ML applications.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!