Top 7 Causes Of LLM Hallucinations and How To Fix Them
Discover what causes LLMs to hallucinate and the top 6 techniques to minimize them.
Artificial Intelligence and Machine Learning
Top 7 Causes Of LLM Hallucinations and How To Fix Them
Discover what causes LLMs to hallucinate and the top 6 techniques to minimize them.
Table of contents
Table of contents
Introduction
Understanding Hallucinations in Large Language Models
5 Step LLM Implementation Roadmap for Teams
7 Causes of Hallucinations in Large Language Models
Top 6 Techniques to Reduce Hallucinations in Large Language Models
Enterprise Risks and Real World Impacts of AI Hallucinations
Future Trends in LLM Hallucination Mitigation and Research
Conclusion
FAQs
Introduction
Large Language Models have become central to modern AI adoption, powering everything from chatbots to decision support systems. However, their most significant limitation remains hallucination, where models generate incorrect or misleading information that appears factual.
As businesses increasingly rely on AI for content creation, customer interaction, and analytics, hallucinations pose serious risks ranging from misinformation to compliance and reputational damage.
Understanding why these errors occur is essential to building trustworthy, responsible AI systems.
This blog explores the top 7 causes of hallucinations in LLMs, explaining how factors such as training datasets, inference challenges, and over-optimization contribute to the problem. It also offers practical techniques to detect, reduce, and manage hallucinations, helping organizations ensure more accurate, reliable, and transparent AI outcomes.
Understanding Hallucinations in Large Language Models
What are LLM Hallucinations?
“Hallucinations in LLMs are instances where the output shared is false, improperly structured, or non-related to the input provided.”
The errors in the output can vary from minor discrepancies to significant problems, such as manipulating facts or figures. This can lead to confusion and develop a wrong impression of the LLM’s capabilities.
These hallucinations are a byproduct of the limitations that an LLM possesses. For example, LLMs like GPT and BERT (Bidirectional Encoder Representations from Transformers) are trained using large amounts of text to guess the following word in a sentence. They don’t necessarily understand meaning, but they leverage patterns in language to develop texts that sound natural.
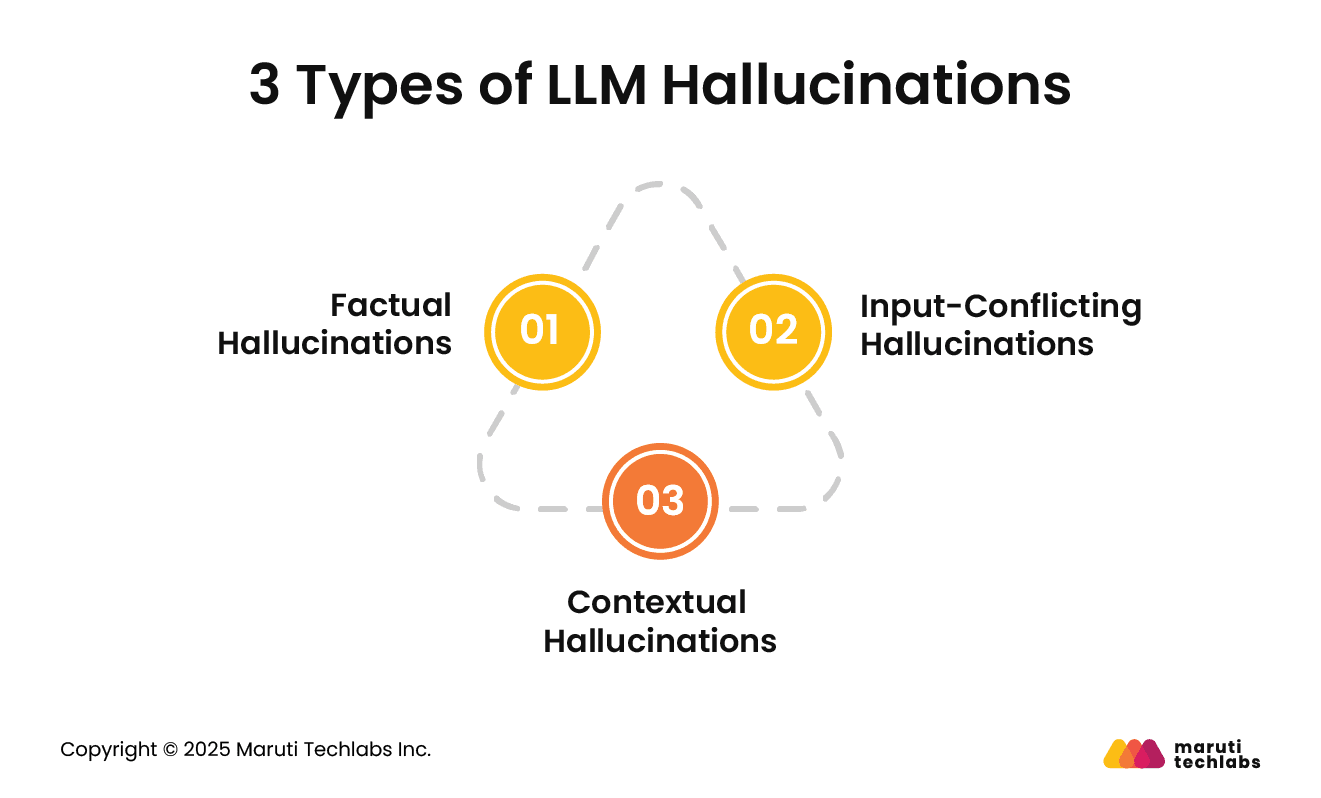
3 Types of LLM Hallucinations
Here are the three different types of hallucinations observed in LLMs.
1. Factual Hallucinations
Fact-conflicting hallucinations are instances that occur when LLMs generate information that isn’t true at all. Several factors contribute to this occurrence, which can occur at various stages of a lifecycle.
2. Input-Conflicting Hallucinations
These hallucinations occur when the output differs from what the user specified. An input consists of the task material and task direction. A mismatch between the LLM’s output and task direction often dictates a misinterpretation of the user’s objectives.
3. Contextual Hallucinations
These are errors where an LLM generates outputs that are contradictory, inconsistent, and observable in multipart responses. These problems are due to an LLM’s limitations in retaining contextual awareness or learning the context for maintaining coherence.
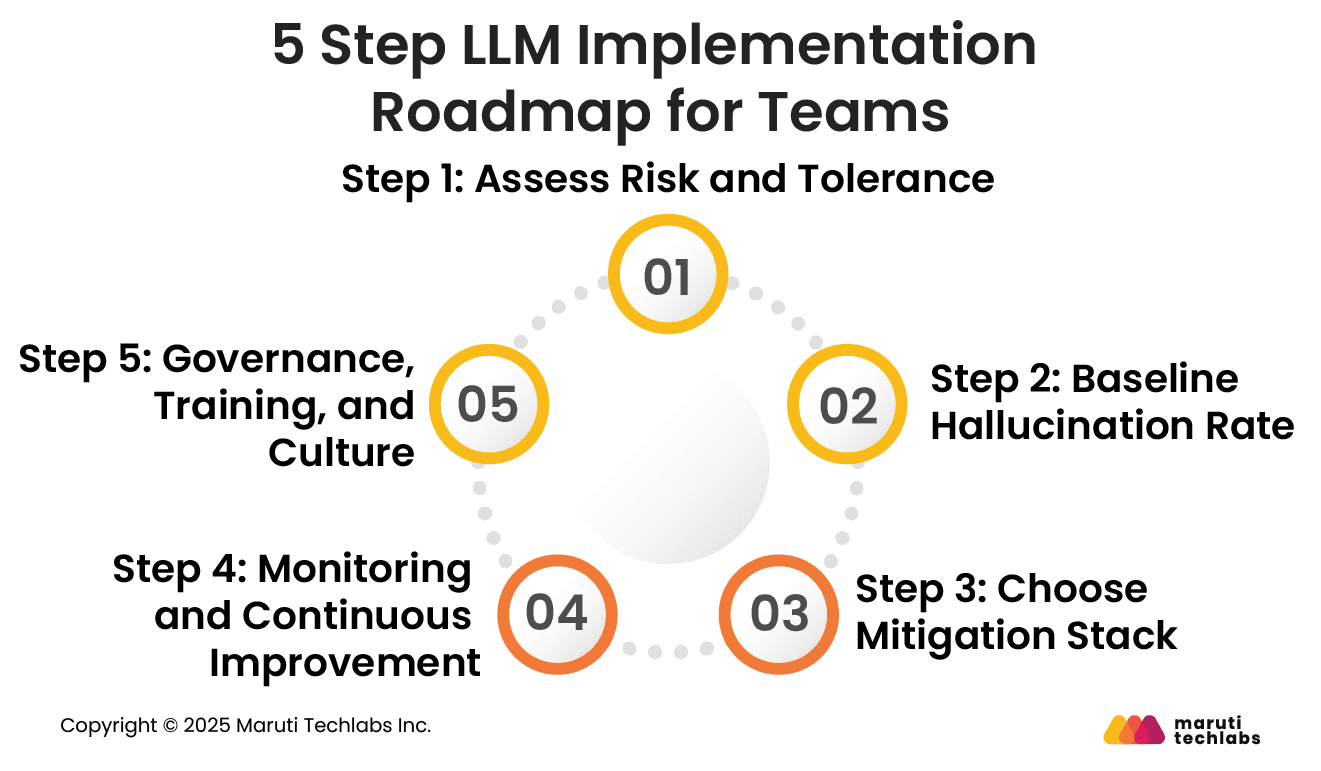
5 Step LLM Implementation Roadmap for Teams
Establishing a structured roadmap helps teams manage hallucinations effectively. From risk assessment to continuous improvement, each step ensures that AI outputs remain reliable, transparent, and aligned with business goals.
Step 1: Assess Risk and Tolerance
Begin by defining acceptable risk levels based on the application context. Evaluate where hallucinations could cause reputational, legal, or financial harm.
This assessment guides model configuration, control intensity, and review processes suited to the organization’s specific tolerance thresholds.
Step 2: Baseline Hallucination Rate
Measure the current hallucination frequency using evaluation datasets and human reviews.
Tracking false or unverifiable outputs establishes a benchmark for gauging future improvements and quantifies the effectiveness of implemented mitigation strategies over time.
Step 3: Choose Mitigation Stack
Select a combination of Retrieval Augmented Generation, prompt engineering, and evaluation frameworks.
These tools enhance factual grounding, optimize responses, and continuously verify information accuracy while maintaining model efficiency and usability.
Step 4: Monitoring and Continuous Improvement
Implement automated monitoring to flag and analyze trends in hallucinations. Use feedback loops, user reports, and accuracy dashboards to refine prompts and retrain models regularly.
This ensures consistent progress toward higher reliability and reduced error rates.
Step 5: Governance, Training, and Culture
Create a governance framework that enforces accountability and ethical standards. Train teams to recognize hallucinations, validate responses, and document outcomes.
Fostering a culture of transparency and responsibility ensures sustainable, organization-wide AI reliability.
7 Causes of Hallucinations in Large Language Models
Here are the most prominent causes that contribute to numerous aspects of LLM development and deployment.
1. Training Datasets
The nature of your training data can significantly affect and contribute to LLM hallucinations. GPT, Falcon, and Llama are some LLMs that have been trained on numerous datasets from different origins without any supervision.
An LLM model’s primary use case is to generate texts. Though learning about data’s fairness and authenticity is challenging, using unverified training data can have dire consequences.
2. Architectural Flaws
Architectural flaws or mediocre training objectives can also cause hallucinations. The most common example of this is when a model’s output is completely unaligned with expected performance or production.
3. Inference Challenges
Factors like inherent randomness in the sampling methods or defective decoding strategies can contribute to hallucinations during the inference stage.
Additionally, issues such as insufficient attention to the context or limitations in the softmax decoding process can result in outputs that are poorly aligned with the context or training data.
4. Prompt Engineering
Hallucinations are also a result of wrongly engineered prompts. If prompts are ambiguously worded or lack necessary context, they can generate irrelevant or false outputs. Clarity and specificity are primary requirements for helping an LLM generate accurate responses.
5. Stochastic Decoding Strategies
Sampling strategies are used by LLMs, which can infuse randomness into the output. For instance, the risk of hallucinations and creativity can increase in high-temperature settings. This is observed with LLM generating new ideas or plots.
These stochastic processes can at times create nonsensical or unexpected responses, denoting the probabilistic nature of a model’s decision-making process.
6. Ambiguity Handling
Unclear or ambiguous inputs can generate false or factually incorrect outputs. The absence of specific information can force models to fill gaps with invented data. Such instances are evident, as observed with ChatGPT when it falsely accused a professor in response to an ambiguous prompt.
7. Over-Optimization
At times when longer outputs are expected from LLMs, they can offer verbose or irrelevant information. This over-optimization can lead LLM to produce hallucinatory content instead of providing concise and accurate information.
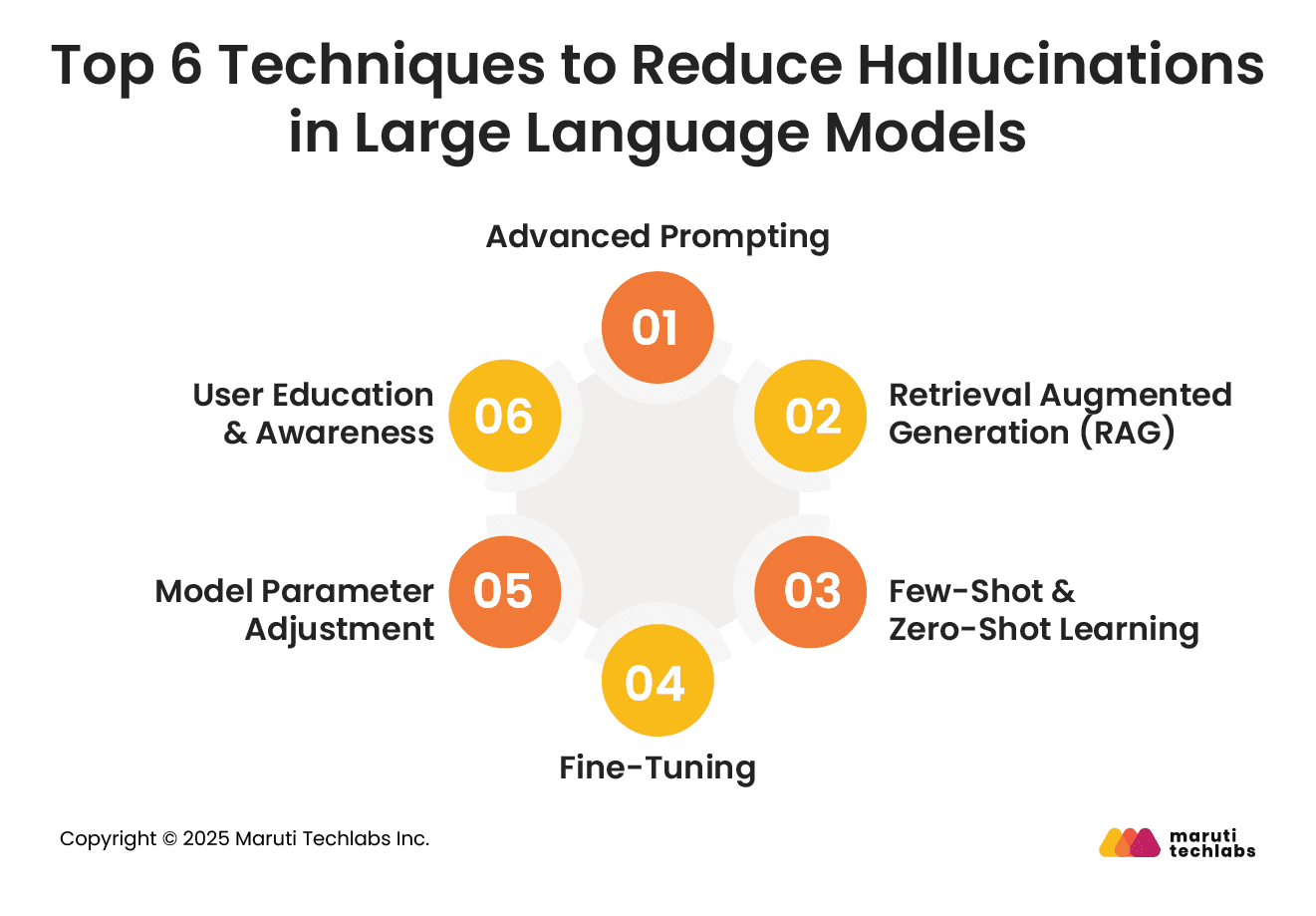
Top 6 Techniques to Reduce Hallucinations in Large Language Models
Let’s explore some practices that you can follow to decrease LLM hallucinations.
1. Advanced Prompting
Advanced prompting or prompt engineering is a strategy that enhances the model’s capability to understand tasks and offer more relevant, exact, and coherent responses.
One of the most well-known techniques is the chain-of-thought. It classifies the reasoning of the model into intermediary steps before sharing a final answer. This method works best for explanatory tasks or complex problem-solving.
Chain-of-thought prompts minimize hallucinations by articulating a clear reasoning path, discouraging the model from reaching direct conclusions.
2. Retrieval Augmented Generation (RAG)
Retrieval augmented generation empowers the generative capabilities of LLMs with authentic information retrieval. RAG can lower the chances of hallucinations.
However, hallucinations can still occur, even with access to relevant information, because the output may not match or may even contradict the retrieved data.
To truly reduce hallucinations in RAG systems, we need benchmark datasets that can measure how often they occur. These datasets are essential for building better ways to prevent such errors. Two useful tools for this are the Retrieval-Augmented Generation Benchmark (RGB) and RAGTruth.
RGB is a special dataset for testing RAG in both English and Chinese. It’s split into four test areas that focus on key skills needed to fight hallucinations. This provides a thorough method for evaluating how well LLMs handle RAG tasks.
In one study, researchers tested six different LLMs using RGB. They found that while the models could handle some noisy or messy data, they often failed at three main things: rejecting false information, combining information correctly, and spotting incorrect facts.
RAGTruth examines hallucinations at a word level, sifting through various domains and activities within the traditional RAG setup for LLM usage. It fetches almost 18,000 genuine responses shared by numerous LLMs employing RAG.
3. Few-Shot & Zero-Shot Learning
A few-shot prompt is where one offers precisely selected examples that guide an LLM model. These examples include the expected output, allowing the model to observe and duplicate the style, format, and other details in its responses.
By demonstrating what response is expected, few-shot prompts LLM can offer factually correct responses, narrowing its focus on specific requirements.
Zero-shot learning relies on an LLM's broad understanding of language and knowledge patterns to offer a response to inputs they haven’t been trained on. This restrains the model from making unsupported assumptions or fabrications.
Few-shot and zero-shot help a model generate coherent responses from minimal examples while mitigating the occurrence of hallucinations.
4. Fine-Tuning
Fine-tuning involves adjusting an LLM’s current learnings to better understand nuances, facts, and details of a new topic. This enhances a model's accuracy and relevance.
Training the model on specific and selected data allows for the update of an LLM’s knowledge, thereby removing outdated information from its pretraining.
It aids the model’s ability to share correct, clear, and contextually relevant answers, reducing the probability of generating made-up or false information.
5. Model Parameter Adjustment
The outputs of an LLM are significantly impacted by various model parameters such as top-p, temperature, and frequency-penalty. Lower temperature settings offer a predictable output while higher temperature settings foster creativity and randomness.
A higher frequency penalty limits the model’s use of repeated words. On the other hand, increasing the presence penalty prompts an LLM to use words that haven’t been used in the output yet.
The top-p setting controls the variety of a response by choosing words within a probable range. These parameters together create a balance between sharing varied outputs while maintaining accuracy. Therefore, fine-tuning limits the likelihood of LLM hallucinations.
6. User Education & Awareness
It’s imperative to educate employees and stakeholders about the LLM's potential to generate misleading text and other risks. If accuracy is your primary concern, users should continually assess and verify LLM outputs.
An organization should establish governance policies across LLM use, especially if the generated information can cause harm or monetary loss. Companies should have precise guidelines that facilitate responsible AI usage, that prevent offensive content and misinformation.
While it’s practically impossible to eliminate LLM hallucinations, implementing the above-mentioned preventive measures can substantially decrease their frequency. Maintaining equilibrium between utilizing technology without causing harm is necessary, which can only be achieved through responsible and thoughtful engagement with AI.
Enterprise Risks and Real World Impacts of AI Hallucinations
In regulated industries such as healthcare, legal, and finance, hallucinations in large language models can lead to severe consequences, from compliance violations to reputational and financial losses.
1. Risks in Regulated Domains
In healthcare, inaccurate AI-generated summaries or diagnoses can endanger patient safety. In the legal sector, fabricated citations may compromise case integrity, while in finance, incorrect risk assessments or data insights can lead to regulatory breaches and poor investment decisions. Each error carries tangible, real-world implications.
2. Real-World Example
A notable case involved an attorney in the United States who submitted a legal brief containing AI-generated case citations from ChatGPT. The incident led to court sanctions and public criticism, highlighting how unchecked reliance on AI can damage credibility and professional accountability.
Future Trends in LLM Hallucination Mitigation and Research
As large language models mature, researchers are focusing on deeper reasoning, improved factual grounding, and better alignment with human judgment to minimize hallucinations and enhance trust in AI-generated outputs.
1. Self-Alignment and Causal Reasoning Frameworks
Emerging research emphasizes self-alignment, where models learn to critique and correct their own outputs.
Integrating causal reasoning enables systems to understand relationships among facts, thereby improving logical consistency and reducing unsupported or fabricated statements in complex reasoning tasks.
2. arXiv and Ongoing Research Contributions
The arXiv community continues to publish cutting-edge work on hallucination detection, model interpretability, and factual grounding.
Studies focus on evaluating model transparency, designing benchmark datasets, and building frameworks that improve reliability while balancing creativity and contextual flexibility.
3. Enhanced Knowledge Graphs and Retrieval Systems
Future models will increasingly rely on dynamic knowledge graphs and retrieval augmented architectures.
These systems provide real-time, factual references, ensuring answers are grounded in verified data sources and reducing reliance on potentially outdated or incomplete internal training materials.
4. Model Calibration and Uncertainty Awareness
Model calibration and expert deferral mechanisms are gaining attention.
By teaching models to recognize uncertainty and escalate ambiguous queries to human experts, organizations can achieve safer deployment and maintain trust in AI-assisted decision processes.
Conclusion
Hallucination in LLMs can lead to misinformation, reduce trust in AI systems, and cause costly errors in decision-making. Minimizing hallucinations is crucial to ensure reliability, maintain credibility, and improve user confidence in AI-driven solutions.
In modern Generative AI systems, strategies like fine-tuning with curated data, adjusting frequency and presence penalties, and controlling output variety with top-p can significantly reduce these issues. These approaches make AI responses more accurate, relevant, and aligned with the intended context.
At Maruti Techlabs, we specialize in building and refining AI models to deliver dependable, high-quality outputs. From AI readiness audits to end-to-end AI development services, we help organizations deploy solutions that are both powerful and trustworthy.
Connect with us today to explore our AI Services or get your AI readiness audit to start building reliable, business-ready AI systems. Use our AI Readiness Assessment Tool to evaluate your preparedness for adopting AI effectively.
FAQs
1. How to reduce hallucinations in large language models?
You can reduce hallucinations in LLMs by fine-tuning with high-quality, domain-specific data, using retrieval-augmented generation (RAG), adjusting parameters like frequency/presence penalties and top-p, and implementing post-processing checks to verify factual accuracy before delivering responses.
2. How to avoid hallucinations in large language models?
Avoid hallucinations by combining the model with verified external data sources, applying strict prompt engineering, continuously updating training data, and using fact-checking tools or human review for critical outputs, especially in high-stakes or specialized domains.
3. What are the leading causes of hallucinations in large language models?
Hallucinations often occur due to gaps or biases in training data, outdated knowledge, probabilistic text generation without fact verification, overgeneralization, and prompts that lead the model to guess rather than retrieve accurate information.
Pinakin Ariwala has over 20 years of experience in AI/ML, data engineering, and software development. He has led AI and machine learning projects across industries, including agriculture, finance, and healthcare, and has been featured on the Clutch Leaders Matrix podcast discussing real-world AI/ML applications.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!