A Brief Guide on DAGs: Characteristics, Types, and Practical Uses
Boost workflow orchestration — unlock the power of DAGs for seamless execution.
Data Analytics and Business Intelligence
A Brief Guide on DAGs: Characteristics, Types, and Practical Uses
Boost workflow orchestration — unlock the power of DAGs for seamless execution.
Table of contents
Table of contents
Introduction
What is a DAG?
Characteristics that Make DAGs Perfect for Data Engineering
Types of DAG Workflows
Top 9 Applications of DAGs in Data Engineering
Top 5 Tools for Managing DAGs in Data Engineering
Conclusion
FAQs
Introduction
As a data engineer, you're likely familiar with directed acyclic graphs (DAGs). If not, this is the perfect place to get started.
Graphs offer a visual glimpse of concepts that are cumbersome to understand otherwise. All tasks are logically organized, with other operations conducted at prescribed intervals and clear links with different tasks. In addition, they offer a lot of information quickly and concisely.
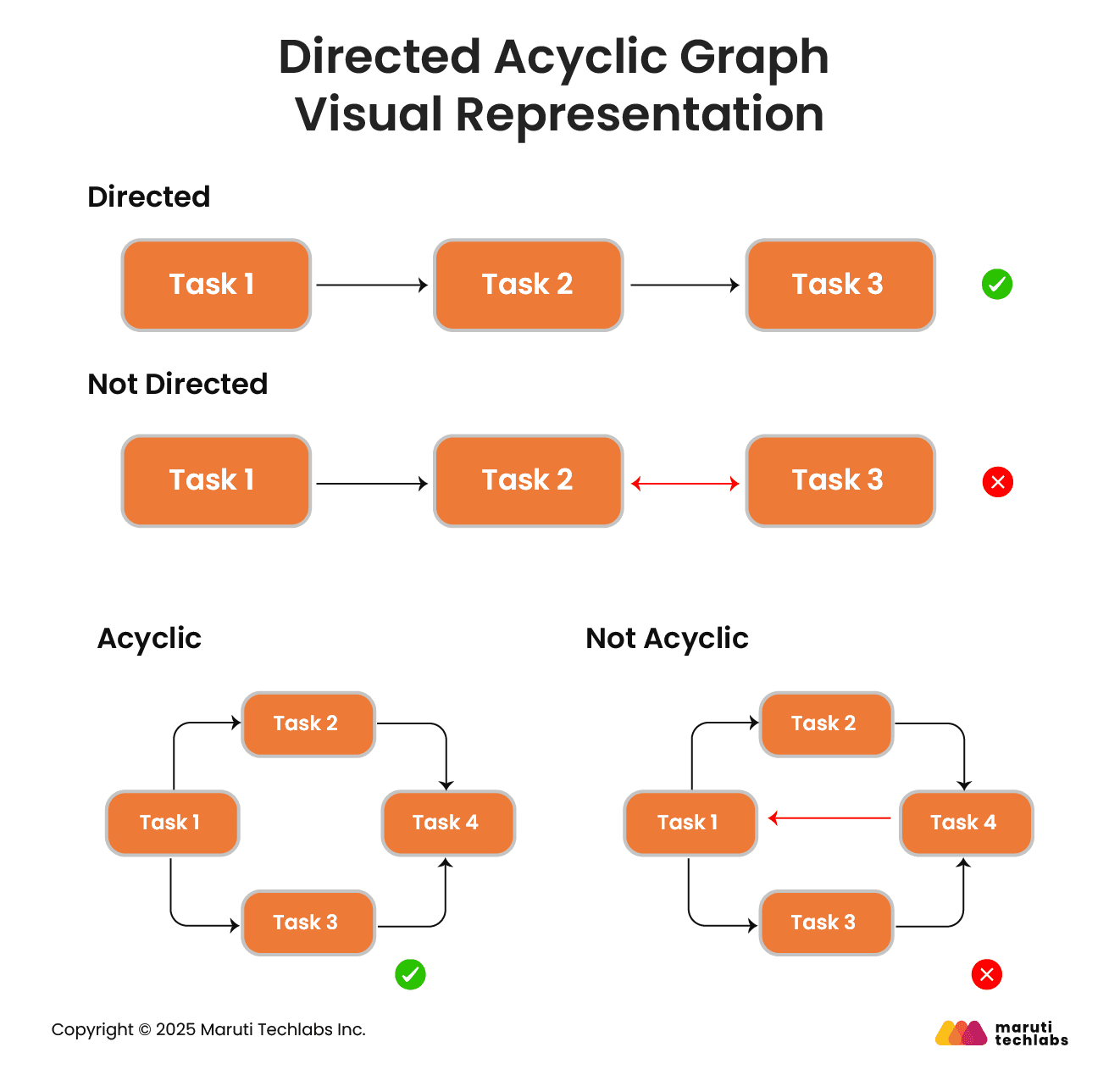
A DAG is one such graph whose nodes are directly connected and don’t form a directed group. In data engineering, the relationship between your data models is often represented via DAGs.
DAGs originated with mathematics, became popular with computational work, and eventually found their way to the modern data world. They offer the perfect way to visualize data pipelines, internal connections, and dependencies between data models.
This blog is all about DAGs. Read on to learn more about the definition, properties, top applications, and tools to implement DAGs.
What is a DAG?
To understand Directed Acyclic Graphs (DAGs), it’s useful to start with a few foundational concepts. A graph is a non-linear data structure made up of nodes (or vertices) and edges. Nodes represent entities or objects, while edges define their relationships or connections.
A sequence of nodes connected by directed edges is called a path. With that in mind, a DAG can be defined as:
A DAG is a directed graph that consists of nodes that depict a particular task, and edges define the dependencies between them with no directed cycles.
A primary characteristic of DAG is its ‘acyclic’ nature, meaning once you start with one node, you can never return to a previous node (and can only move forward). This chronological order eliminates the issue of infinite loops.
DAGs often follow a layered approach, with tasks at a higher level only executed after completing the tasks at lower levels.
Other Essential Components of DAG
Apart from graph, nodes, edges, and path, here’s a breakdown of some of the other critical components of DAG:
Directed Edges: Connections that only flow in one direction are represented via directed edges. Arrows on each edge determine their direction.
Colliders: Nodes with two directed edges pointing at them are termed colliders.
Tree: A tree represents a directed acyclic graph where, except for the starting or root node, every other node has 1 directed edge pointing towards it. As edges start from the root node, no edges point towards it.
Why Do DAGs Matter?
Here are a few reasons that highlight the importance of using DAGs.
They enhance efficiency by conducting independent tasks simultaneously.
DAGs simplify workflows, conceptually and visually. It offers clarity while making it easier to debug.
DAGs observe a modular design, facilitating component reusability across other projects or experiments.
Characteristics that Make DAGs Perfect for Data Engineering
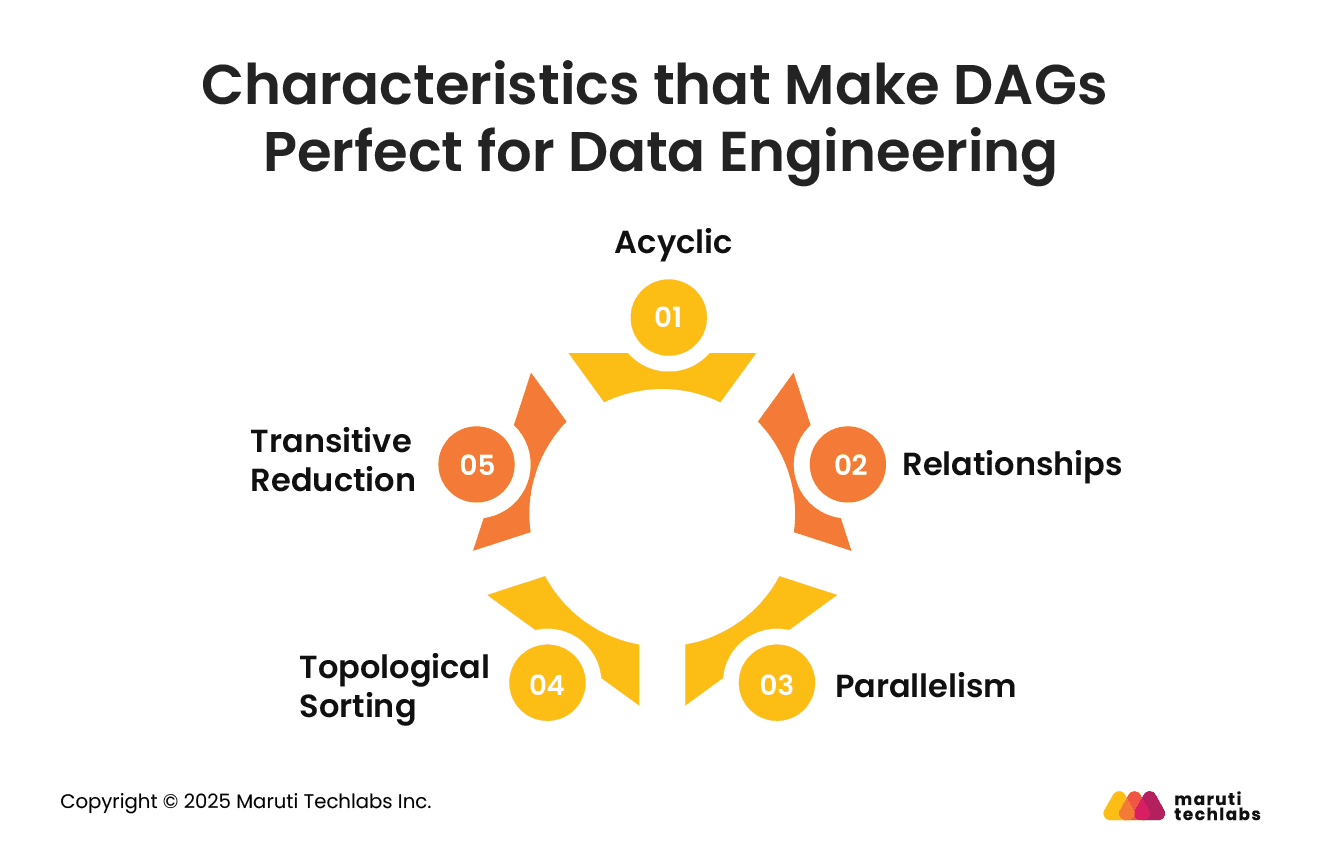
Understanding DAGs can be a game-changer if you have to work with data extensively. Here are the core properties of DAGs:
1. Acyclic
Directed acyclic graphs represent data flows without circular dependencies, as they don’t work in cycles. The absence of cycles makes DAGs a perfect fit for scheduling and executing tasks that follow a particular order.
2. Relationships
Edges in DAGs represent the dependency between tasks, with their direction denoting the direction of the dependency. This makes it easy to understand a program's overall workflow and learn how the tasks fit together.
3. Parallelism
DAGs supplement parallel task execution, improving the efficiency of a schedule or program.
4. Topological Sorting
A topological sort is an algorithm that develops a linear ordering of the vertices in a graph by taking a DAG as input. This algorithm explicitly determines how tasks should be implemented in a DAG.
5. Transitive Reduction
Transitive reduction is a process that maintains the transitive closure of the original graph while eliminating specific edges from a DAG. This facilitates efficient reasoning concerning the dependencies in a DAG.
Types of DAG Workflows
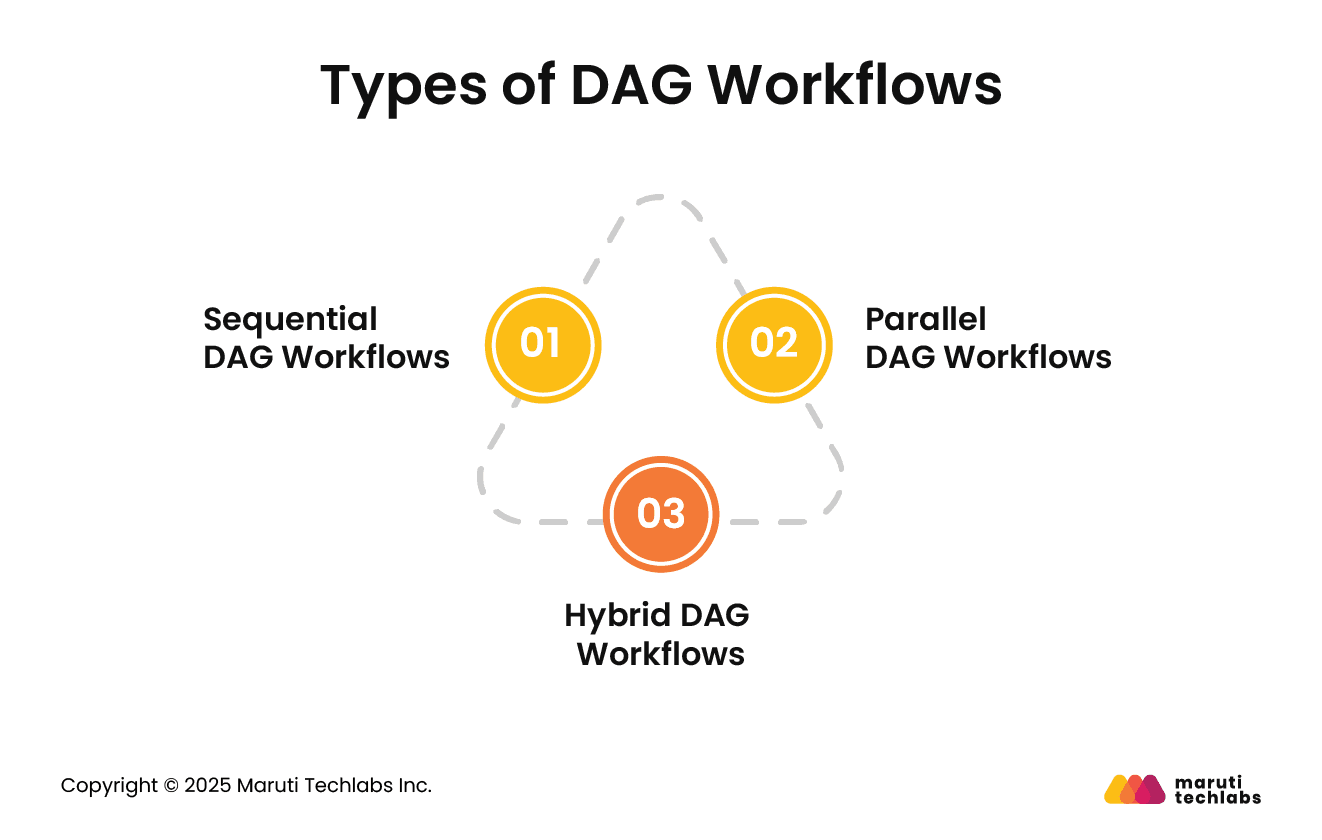
Depending on their approach to execution, DAG workflows can be categorized into 3 types.
1. Sequential DAG Workflows
In a sequential DAG workflow, tasks follow a linear sequence, where a new task is only initiated upon completion of the previous one. However, a sequential workflow facilitates more complex dependency management and scalability than a simple linear workflow.
2. Parallel DAG Workflows
Here, tasks follow an organized structure. However, they can run concurrently, independently of each other. This feat is achieved by dividing workflows into multiple branches that execute simultaneously.
3. Hybrid DAG Workflows
This offers a mix of sequential and parallel execution. Hybrid DAG workflows are extensively used in DevOps and data pipelines where some tasks must follow a sequence while others can run in parallel.
Top 9 Applications of DAGs in Data Engineering
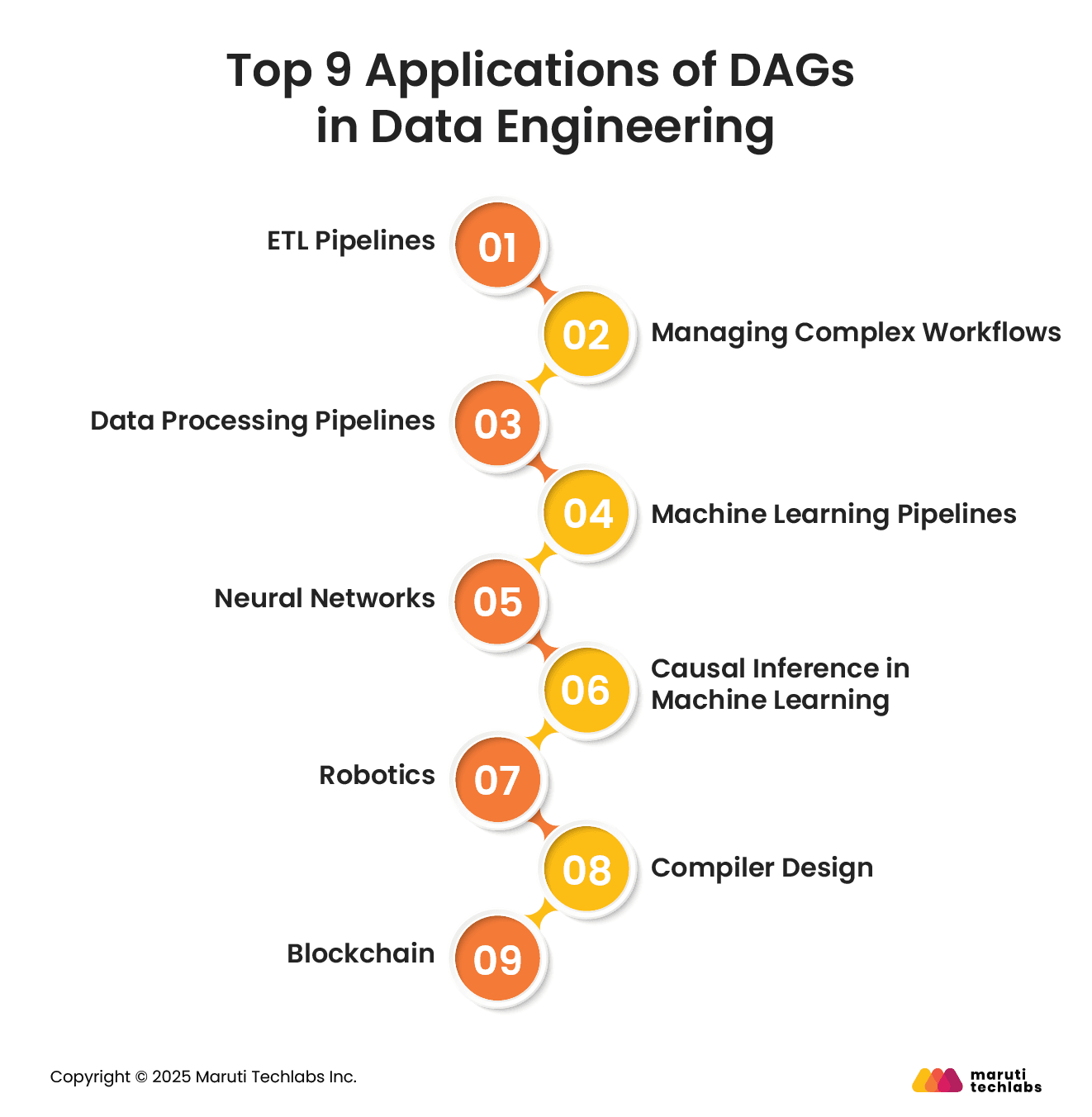
DAGs have many applications in data engineering. Here are its most prominent uses.
1. ETL Pipelines
DAGs are widely used for performing the Extract, Transform, and Load (ETL) processes. ETL works by extracting data from different sources, transforming it into a viable format, and loading it into the target system.
A practical example of this can be accumulating data from your CRM system, converting it into your required format, and loading it into a suitable platform for analytics.
DAGs can also track and log task runtimes for ETL processes. This assists with discovering bottlenecks and tasks demanding optimization.
2. Managing Complex Workflows
DAGs are a perfect fit when working with multiple tasks and dependencies. For instance, a machine learning workflow may include tasks such as feature engineering, model training and model deployment.
3. Data Processing Pipelines
Data processing pipelines make ample use of DAGs to accumulate data from numerous sources and convert it to uncover important insights. For instance, a DAG in Apache Spark can process clickstream data from a website, calculate session durations by performing aggregation, and populate a dashboard with insights.
4. Machine Learning Pipelines
DAGs offer assistance with an ML workflow’s modular and iterative nature. They keep the pipeline organized while allowing you to experiment with preprocessing steps, algorithms, and hyperparameters.
For example, one can perform seamless experimentation and deployment with tools like MLflow to manage ML workflows. In addition, one can ensure the accuracy and relevance of models by leveraging DAGs to retrain pipelines triggered by data drift detection.
5. Neural Networks
A neural network is an ML program designed to make decisions like a human brain. It uses processes that imitate the way biological neurons perform together to make observations and arrive at conclusions.
DAGs perform mapping for neural networks and assist with visualizing multiple layers of deep neural networks.
6. Causal Inference in Machine Learning
DAGs can contribute significantly to teaching AI models to spot causal relationships with causal inference. AI systems supporting causal inference are getting high praise as a tool in epidemiology. It holds the potential to help researchers in their investigations of disease determinants.
7. Robotics
Researchers plan to enhance the performance of dual-arm robots, using DAG and a large language model-based structural planning method. In this framework, LLM creates a DAG that includes subtasks as complex tasks, with edges representing their internal dependencies. Here, this information is used to finalize motion planning and coordination between the 2 arms for executing tasks.
8. Compiler Design
Compilers are programs that translate programming languages (source code) into computer instructions (machine code). DAGs are used to optimize compiler designs. For example, a DAG can improve efficiency by identifying and eliminating common subexpressions.
9. Blockchain
DAG fosters flexibility and scalability, increasing transaction processing rate in a specific period. Such enhancements have much to offer in areas like access controls for IoT networks and supply chain management.
Top 5 Tools for Managing DAGs in Data Engineering
Here are 5 popular tools that can help you manage DAGs effectively.
1. Apache Airflow
Apache Airflow is a renowned platform for building, scheduling, and observing workflows. It’s highly proficient at defining complex data pipelines as DAGs. Airflow makes grasping and troubleshooting data workflows easy by providing a user-friendly interface for visualizing and managing DAGs. Its flexibility and scalability have made this platform a primary choice for data engineering teams.
2. Prefect
Prefect simplifies the development and management of data workflows. It makes integration with Python code easy, offering a Python-based API for defining DAGs. It provides features like backfills, automatic retries, and robust monitoring, prioritizing observability and reliability.
3. Dask
Dask manages distributed data workflows and is a parallel computing library for Python. It’s a perfect fit for large-scale data processing tasks because it can parallelize computations across multiple cores or machines. Dask ensures efficient resource utilization with a DAG-based execution model for scheduling and coordinating tasks.
4. Kubeflow Pipelines
Kubeflow Pipelines is the perfect open-source platform for developing and deploying scalable ML workflows. From data preprocessing to model deployment, it defines end-to-end workflows using DAGs. Due to its seamless integration with Kubernetes, it’s a preferable option for running workflows in cloud environments. Kubeflow also enhances transparency and control with its visual interface for managing and monitoring workflows.
5. Dagster
Dagster orchestrates modern data workflows. It simplifies testing and maintaining DAGs by emphasizing modularity and type safety. Dagster is the best choice for working with diverse technologies as it offers seamless integration with tools like Apache Spark and Snowflake.
Conclusion
Directed Acyclic Graphs (DAGs) are foundational to modern data engineering. They offer a structured approach to orchestrating complex workflows. DAGs ensure processes execute in a precise, non-redundant sequence, eliminating cycles and preventing infinite loops.
This structure is crucial in managing ETL pipelines, automating machine learning workflows, and optimizing data processing tasks. Tools like Apache Airflow and Prefect leverage DAGs to provide scalability and clear visualization of data flows, enhancing efficiency and reliability in data operations.
If you’re planning to harness the full potential of DAGs in your data engineering endeavors, Maruti Techlabs can be your trusted partners. With a proven track record in delivering robust data solutions, our expertise ensures seamless integration and management of DAG-based workflows tailored to your business needs.
1. What’s the difference between a DAG and a Flowchart?
DAGs emphasize task dependencies and execution order, making them ideal for computational workflows. In contrast, flowcharts offer a broader visual overview of decision-making processes and logic, without focusing solely on task dependencies.
2. Can DAGs handle real-time data workflows?
Tools like Apache Airflow and Prefect enable (near) real-time data workflows — Airflow uses sensors to observe data arrival and trigger tasks, while Prefect, based on real-time triggers, supports dynamic task execution.
3. What are some common challenges with DAGs?
Key challenges include managing complex workflows, which can complicate debugging and maintenance; addressing performance bottlenecks caused by poorly optimized DAGs; and overcoming the learning curve associated with tools like Airflow and Prefect.
4. How do DAGs improve error handling in workflows?
DAGs enhance error handling by tracking dependencies to pinpoint task failures, enabling partial reruns of failed tasks, and offering robust monitoring tools like Airflow and Prefect with comprehensive logs and error notifications.
5. Are there alternatives to DAGs for workflow orchestration?
Though DAGs are widely used, other models like event-driven architectures or state machines can also handle workflows. However, they often lack the clarity and effective dependency management that DAGs offer, particularly in complex pipelines.
Pinakin Ariwala has over 20 years of experience in AI/ML, data engineering, and software development. He has led AI and machine learning projects across industries, including agriculture, finance, and healthcare, and has been featured on the Clutch Leaders Matrix podcast discussing real-world AI/ML applications.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!