Fine-Tuning or Distillation: Which One Fits Your Use Case Better?
A simple guide to fine-tuning and distillation, with real examples to help you choose the right AI approach.
Artificial Intelligence and Machine Learning
Fine-Tuning or Distillation: Which One Fits Your Use Case Better?
A simple guide to fine-tuning and distillation, with real examples to help you choose the right AI approach.
Table of contents
Table of contents
Key Takeaways
Introduction
What is Fine-Tuning?
How Does Fine-Tuning Work?
What is Model Distillation?
How Does Model Distillation Work?
Fine-Tuning vs Distillation: Side-by-Side Comparison
How to Decide Between Fine-Tuning and Distillation
Conclusion
FAQs
Key Takeaways
Fine-tuning is useful when accuracy really matters, and mistakes cannot be ignored.
Distillation works better when speed, cost, and scale are more important than deep expertise.
There is no one right choice; the best option depends on what you are building and how it will be used.
Many real-world systems use both approaches to balance knowledge and performance.
The goal is not just powerful AI, but AI that works well in real products and environments.
Introduction
Large Language Models such as GPT, Claude, and Gemini power many AI-driven products today. They help teams work faster by answering questions, creating content, summarizing documents, and writing code. Since these models are trained on vast amounts of data, they can handle a wide range of tasks without much setup.
That strength can also hold them back. These models are designed to work for everyone. But in real business scenarios, “good for everyone” often means not quite right for your specific needs. A healthcare company needs medical accuracy. A bank needs strict compliance and clarity. A support team needs responses that match its tone and policies. To get there, models need some form of customization.
This is where fine-tuning and model distillation come in. Both techniques help adapt large models for real-world use, but they solve different problems. Fine-tuning focuses on teaching a model to perform better for a specific task or domain. Model distillation focuses on transferring knowledge from a large model into a smaller, faster one.
This blog compares fine-tuning and distillation, explains where they differ, and shows when each approach fits best, with examples from BFSI, pharma, and legal.
What is Fine-Tuning?
Fine-tuning is a method for adapting a language model to a specific task. These models already understand language well, but they are designed to be general. Fine-tuning helps narrow the model's focus, enabling it to perform better in a specific domain.
In simple terms, fine-tuning means retraining an existing model using data from a specific domain. For example, a model used for medical documentation is trained on medical reports and terminology. Over time, it learns how information is structured and what level of accuracy is expected, making its responses more reliable than those of a general model.
This approach is especially useful in areas where accuracy and context are critical. General models may sound correct, but still miss important details. Fine-tuning helps reduce that gap.
When done well, fine-tuning brings several benefits:
More accurate results for specialized tasks
Stronger grasp of domain language and context
Outputs that feel consistent and closer to expert expectations
There are also trade-offs to consider:
High-quality training data is hard to collect and prepare
Training and updates demand solid infrastructure and expertise
Costs increase as models grow and evolve
The model may become less effective outside its trained domain
Fine-tuning works best when depth and reliability matter more than broad flexibility.
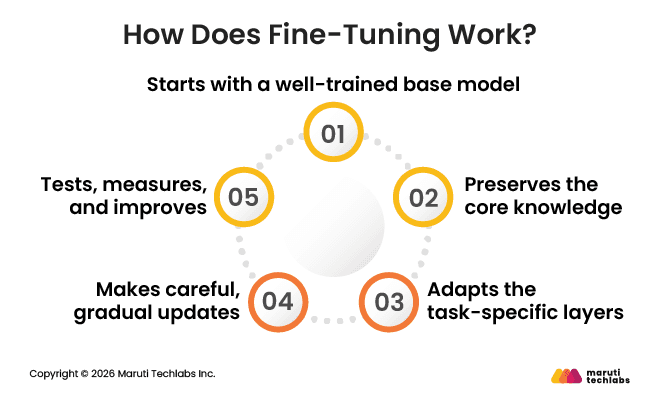
How Does Fine-Tuning Work?
Fine-tuning is about improving a model that already works, rather than building a new one from scratch. The idea is to make small, careful changes so the model improves at a specific task without losing the skills it already has.
1. Starts with a well-trained base model
The process starts by picking a model that has already been trained on a wide range of data. Because of this, the model already understands basic language or visual patterns.
For text-related tasks, models like GPT are often used. Starting with an existing model saves time and makes sure the basics are already in place before any further training begins.
2. Preserves the core knowledge
In most fine-tuning setups, the model's early layers are kept unchanged. These layers handle basic understanding, such as common word patterns in text or simple visual features in images. By leaving them untouched, the model retains its general knowledge and requires less computing power during training.
3. Adapts the task-specific layers
The later layers of the model are where specialization happens. These layers are adjusted using new, focused data so the model learns how to perform a specific task.
For example, when fine-tuning for sentiment analysis, these layers learn how to identify whether text is positive, negative, or neutral. This is where the model starts behaving differently from a general-purpose one.
4. Makes careful, gradual updates
During fine-tuning, changes are made gradually rather than all at once. This helps the model adjust to the new task without disturbing what it already does well.
The idea is to improve results step by step while keeping the model stable. Making small changes also lowers the chance of unexpected or incorrect responses.
5. Tests, measures, and improves
After training, the model is tested using real examples from the actual use case. This helps check how well it performs in real situations.
The results show what the model gets right and where it needs improvement. Based on this, small changes are made, and the model is tested again until the output is reliable enough to use.
Overall, fine-tuning is a controlled and iterative process. It balances learning something new while preserving what the model already knows, which is why it works well for specialized, high-accuracy use cases.
What is Model Distillation?
Model distillation is primarily about making AI easier to use in the real world. Instead of trying to make a model smarter, the goal here is to make it lighter and faster. A good way to think about it is this: you take a very large model and keep only what is truly useful, so it can run smoothly in more places.
Simply put, distillation is about shrinking a big model into a smaller one that still does the job. The smaller model won’t be as smart as the original, but it knows enough to handle most day-to-day tasks. Because it’s lighter, it runs faster and costs less to use.
This is useful when AI needs to run on phones, small devices, or apps where speed really matters. It also helps when using large models feels slow or too expensive. With distillation, teams can build faster tools without needing heavy systems in the background.
Model distillation comes with clear advantages:
Smaller models that run faster and cost less
Works well on devices with limited resources
Easier to roll out across many users or systems
Reduces infrastructure and operational effort
There are also a few trade-offs:
Some loss in accuracy compared to large models
Less depth for complex or highly specialized tasks
Not ideal when expert-level detail is required
Overall, model distillation is a practical choice. It works best when speed, scale, and cost matter more than having a deeply specialized model.
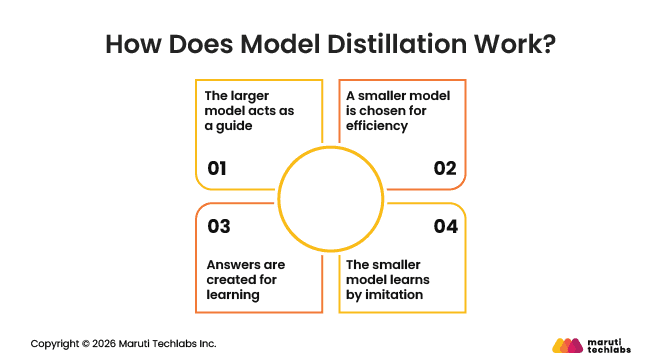
How Does Model Distillation Work?
Model distillation works on a simple idea: a smaller model learns by watching a larger one. Instead of learning everything from scratch, it is guided by a model that already performs well.
1. The larger model acts as a guide
The process starts with a large, well-working model. It has been trained on a lot of data, so it knows how to give good answers. In distillation, this model serves as a reference for what a good response should look like.
2. A smaller model is chosen for efficiency
Next, a smaller model is selected. This model is designed to run faster and more cheaply. On its own, it would not match the performance of the larger model, but distillation helps close that gap by teaching it to respond similarly.
3. Answers are created for learning
Instead of using original training data, the larger model is given many inputs, such as questions or prompts. Its responses are collected and used as examples. These responses act as learning material for the smaller model. This makes it possible to transfer knowledge without needing access to massive datasets.
4. The smaller model learns by imitation
The smaller model is then trained to match the responses of the larger one as closely as possible. Over time, it learns patterns, reasoning styles, and behaviors from the guide model. The goal is not to copy everything perfectly, but to perform well enough for practical use.
In real-world setups, this process can vary. Sometimes more than one large model is used to guide the smaller one. In other cases, only question-and-answer examples are used. What stays the same is the goal: to create a smaller model that behaves like a larger one, while being much easier to run and scale.
Fine-Tuning vs Distillation: Side-by-Side Comparison
Fine-tuning and distillation both help improve language model performance, but they serve different purposes. Fine-tuning focuses on improving a model's performance on a specific task, especially when accuracy and detail matter.
Distillation, on the other hand, is about making models easier to run. Instead of pushing for maximum depth, it aims to keep things fast, lightweight, and cost-effective. Understanding this difference makes it easier to choose the right approach for your use case.
Aspect
Fine-Tuning
Distillation
Main goal
Improve accuracy in a specific domain
Make models smaller and faster
Best suited for
Specialized work like healthcare, legal, or finance
General tasks on limited resources
Data required
Large amounts of domain-specific data
A trained large model to learn from
Output quality
Very strong within a focused area
Good for most tasks, but less detailed
Cost
Higher due to data and computing needs
Lower due to smaller model size
Where it runs best
Cloud or enterprise systems
Mobile apps, edge devices, lightweight systems
In short, fine-tuning is the better choice when precision and domain knowledge matter most. Distillation works better when speed, scale, and lower costs are the priority. The right option depends on what you need the model to do and where you plan to use it.
How to Decide Between Fine-Tuning and Distillation
Both fine-tuning and distillation improve AI models, but they serve different purposes. The right choice depends on what your project needs most — deep expertise or efficiency and speed.
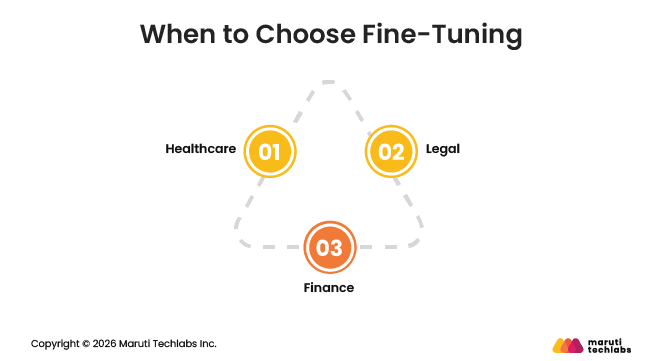
When to Choose Fine-Tuning
Fine-tuning is ideal if you need your AI to act like a domain expert. It works best in industries where accuracy and specialized knowledge matter more than speed.
Healthcare: Fine-tuned models can analyze medical reports, detect diseases, or understand patient data with high precision.
Legal: They can review contracts, summarize case laws, or draft legal documents using specialized terminology.
Finance: Fine-tuned models can process loan applications, spot fraud, or generate compliance-ready reports.
In these cases, even a small mistake can be a big problem. Fine-tuning helps the model learn the field well, so it can act like an expert.
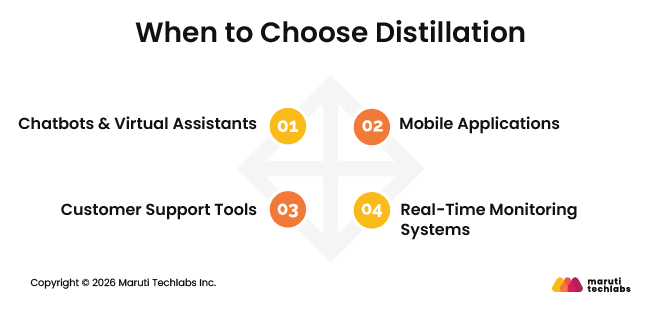
When to Choose Distillation
Distillation is best when you want AI that’s quick, light, and easy to use. It’s a good choice when speed and scalability are more important than knowing every detail.
Chatbots & Virtual Assistants: Provide quick responses to customer queries without heavy server requirements.
Mobile Applications: Run AI on smartphones efficiently, without draining the battery or relying on the cloud constantly.
Customer Support Tools: Deliver instant answers while keeping operational costs low.
Real-Time Monitoring Systems: Make fast decisions where speed is more important than full accuracy.
With distillation, the slight drop in precision is acceptable because the focus is on performance and efficiency.
Using Both Approaches Together
Sometimes it helps to use both. For example, a bank can fine-tune a model to make it an expert, then create a smaller, faster version to run on apps or chatbots. This way, they get quick, efficient AI without losing the expert knowledge.
Conclusion
Fine-tuning and distillation are two ways to improve AI, but they address different problems. Fine-tuning is useful when accuracy really matters, and even small mistakes can cause issues. Distillation is a better fit when you need faster responses, lower costs, and systems that can handle many users. There is no single right choice. It depends on what you want the AI to do.
In real life, most systems need a balance. A model may be trained carefully to learn the right knowledge first, and then made smaller so it can be used in apps, tools, or customer-facing systems without slowing things down. This is how AI becomes practical, not just powerful.
As AI continues to grow, the focus will shift from building bigger models to building smarter ones that are easier to use and easier to run. The goal is simple: AI that fits real business needs.
Pinakin Ariwala has over 20 years of experience in AI/ML, data engineering, and software development. He has led AI and machine learning projects across industries, including agriculture, finance, and healthcare, and has been featured on the Clutch Leaders Matrix podcast discussing real-world AI/ML applications.
Stuck with a Tech Hurdle?
We fix, build, and optimize. The first consultation is on us!